 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Frequency-Decomposition Graph Neural Networks for Road Network Representation Learning
Nov 16, 2025Road networks are critical infrastructures underpinning intelligent transportation systems and their related applications. Effective representation learning of road networks remains challenging due to the complex interplay between spatial structures and frequency characteristics in traffic patterns. Existing graph neural networks for modeling road networks predominantly fall into two paradigms: spatial-based methods that capture local topology but tend to over-smooth representations, and spectral-based methods that analyze global frequency components but often overlook localized variations. This spatial-spectral misalignment limits their modeling capacity for road networks exhibiting both coarse global trends and fine-grained local fluctuations. To bridge this gap, we propose HiFiNet, a novel hierarchical frequency-decomposition graph neural network that unifies spatial and spectral modeling. HiFiNet constructs a multi-level hierarchy of virtual nodes to enable localized frequency analysis, and employs a decomposition-updating-reconstruction framework with a topology-aware graph transformer to separately model and fuse low- and high-frequency signals. Theoretically justified and empirically validated on multiple real-world datasets across four downstream tasks, HiFiNet demonstrates superior performance and generalization ability in capturing effective road network representations.
Spatio-Temporal Data Enhanced Vision-Language Model for Traffic Scene Understanding
Nov 12, 2025Nowadays, navigation and ride-sharing apps have collected numerous images with spatio-temporal data. A core technology for analyzing such images, associated with spatiotemporal information, is Traffic Scene Understanding (TSU), which aims to provide a comprehensive description of the traffic scene. Unlike traditional spatio-temporal data analysis tasks, the dependence on both spatio-temporal and visual-textual data introduces distinct challenges to TSU task. However, recent research often treats TSU as a common image understanding task, ignoring the spatio-temporal information and overlooking the interrelations between different aspects of the traffic scene. To address these issues, we propose a novel SpatioTemporal Enhanced Model based on CILP (ST-CLIP) for TSU. Our model uses the classic vision-language model, CLIP, as the backbone, and designs a Spatio-temporal Context Aware Multiaspect Prompt (SCAMP) learning method to incorporate spatiotemporal information into TSU. The prompt learning method consists of two components: A dynamic spatio-temporal context representation module that extracts representation vectors of spatio-temporal data for each traffic scene image, and a bi-level ST-aware multi-aspect prompt learning module that integrates the ST-context representation vectors into word embeddings of prompts for the CLIP model. The second module also extracts low-level visual features and image-wise high-level semantic features to exploit interactive relations among different aspects of traffic scenes. To the best of our knowledge, this is the first attempt to integrate spatio-temporal information into visionlanguage models to facilitate TSU task. Experiments on two realworld datasets demonstrate superior performance in the complex scene understanding scenarios with a few-shot learning strategy.
LightReasoner: Can Small Language Models Teach Large Language Models Reasoning?
Oct 09, 2025Large language models (LLMs) have demonstrated remarkable progress in reasoning, often through supervised fine-tuning (SFT). However, SFT is resource-intensive, relying on large curated datasets, rejection-sampled demonstrations, and uniform optimization across all tokens, even though only a fraction carry meaningful learning value. In this work, we explore a counterintuitive idea: can smaller language models (SLMs) teach larger language models (LLMs) by revealing high-value reasoning moments that reflect the latter's unique strength? We propose LightReasoner, a novel framework that leverages the behavioral divergence between a stronger expert model (LLM) and a weaker amateur model (SLM). LightReasoner operates in two stages: (1) a sampling stage that pinpoints critical reasoning moments and constructs supervision examples capturing the expert's advantage through expert-amateur contrast, and (2) a fine-tuning stage that aligns the expert model with these distilled examples, amplifying its reasoning strengths. Across seven mathematical benchmarks, LightReasoner improves accuracy by up to 28.1%, while reducing time consumption by 90%, sampled problems by 80%, and tuned token usage by 99%, all without relying on ground-truth labels. By turning weaker SLMs into effective teaching signals, LightReasoner offers a scalable and resource-efficient approach for advancing LLM reasoning. Code is available at: https://github.com/HKUDS/LightReasoner
ProDiff: Prototype-Guided Diffusion for Minimal Information Trajectory Imputation
May 29, 2025Trajectory data is crucial for various applications but often suffers from incompleteness due to device limitations and diverse collection scenarios. Existing imputation methods rely on sparse trajectory or travel information, such as velocity, to infer missing points. However, these approaches assume that sparse trajectories retain essential behavioral patterns, which place significant demands on data acquisition and overlook the potential of large-scale human trajectory embeddings. To address this, we propose ProDiff, a trajectory imputation framework that uses only two endpoints as minimal information. It integrates prototype learning to embed human movement patterns and a denoising diffusion probabilistic model for robust spatiotemporal reconstruction. Joint training with a tailored loss function ensures effective imputation. ProDiff outperforms state-of-the-art methods, improving accuracy by 6.28\% on FourSquare and 2.52\% on WuXi. Further analysis shows a 0.927 correlation between generated and real trajectories, demonstrating the effectiveness of our approach.
Genie Centurion: Accelerating Scalable Real-World Robot Training with Human Rewind-and-Refine Guidance
May 24, 2025



While Vision-Language-Action (VLA) models show strong generalizability in various tasks, real-world deployment of robotic policy still requires large-scale, high-quality human expert demonstrations. However, passive data collection via human teleoperation is costly, hard to scale, and often biased toward passive demonstrations with limited diversity. To address this, we propose Genie Centurion (GCENT), a scalable and general data collection paradigm based on human rewind-and-refine guidance. When the robot execution failures occur, GCENT enables the system revert to a previous state with a rewind mechanism, after which a teleoperator provides corrective demonstrations to refine the policy. This framework supports a one-human-to-many-robots supervision scheme with a Task Sentinel module, which autonomously predicts task success and solicits human intervention when necessary, enabling scalable supervision. Empirical results show that GCENT achieves up to 40% higher task success rates than state-of-the-art data collection methods, and reaches comparable performance using less than half the data. We also quantify the data yield-to-effort ratio under multi-robot scenarios, demonstrating GCENT's potential for scalable and cost-efficient robot policy training in real-world environments.
Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
Feb 18, 2025Limited by the context window size of Large Language Models(LLMs), handling various tasks with input tokens exceeding the upper limit has been challenging, whether it is a simple direct retrieval task or a complex multi-hop reasoning task. Although various methods have been proposed to enhance the long-context processing capabilities of LLMs, they either incur substantial post-training costs, or require additional tool modules(e.g.,RAG), or have not shown significant improvement in realistic tasks. Our work observes the correlation between the attention distribution and generated answers across each layer, and establishes the attention allocation aligns with retrieval-augmented capabilities through experiments. Drawing on the above insights, we propose a novel method InfiniRetri that leverages the LLMs's own attention information to enable accurate retrieval across inputs of infinitely length. Our evaluations indicate that InfiniRetri achieves 100% accuracy in the Needle-In-a-Haystack(NIH) test over 1M tokens using a 0.5B parameter model, surpassing other method or larger models and setting a new state-of-the-art(SOTA). Moreover, our method achieves significant performance improvements on real-world benchmarks, with a maximum 288% improvement. In addition, InfiniRetri can be applied to any Transformer-based LLMs without additional training and substantially reduces inference latency and compute overhead in long texts. In summary, our comprehensive studies show InfiniRetri's potential for practical applications and creates a paradigm for retrievaling information using LLMs own capabilities under infinite-length tokens. Code will be released in link.
Bridging Traffic State and Trajectory for Dynamic Road Network and Trajectory Representation Learning
Feb 08, 2025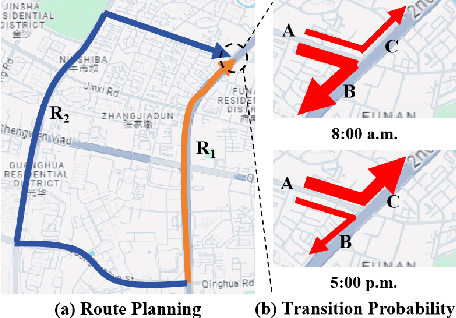

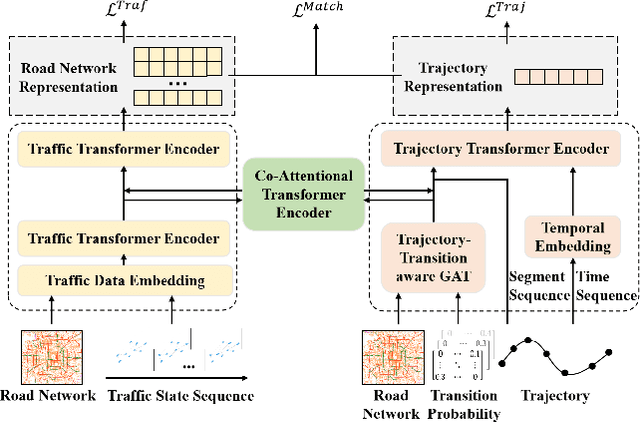
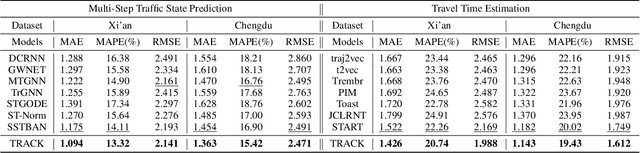
Effective urban traffic management is vital for sustainable city development, relying on intelligent systems with machine learning tasks such as traffic flow prediction and travel time estimation. Traditional approaches usually focus on static road network and trajectory representation learning, and overlook the dynamic nature of traffic states and trajectories, which is crucial for downstream tasks. To address this gap, we propose TRACK, a novel framework to bridge traffic state and trajectory data for dynamic road network and trajectory representation learning. TRACK leverages graph attention networks (GAT) to encode static and spatial road segment features, and introduces a transformer-based model for trajectory representation learning. By incorporating transition probabilities from trajectory data into GAT attention weights, TRACK captures dynamic spatial features of road segments. Meanwhile, TRACK designs a traffic transformer encoder to capture the spatial-temporal dynamics of road segments from traffic state data. To further enhance dynamic representations, TRACK proposes a co-attentional transformer encoder and a trajectory-traffic state matching task. Extensive experiments on real-life urban traffic datasets demonstrate the superiority of TRACK over state-of-the-art baselines. Case studies confirm TRACK's ability to capture spatial-temporal dynamics effectively.
Learning Universal Multi-level Market Irrationality Factors to Improve Stock Return Forecasting
Feb 07, 2025Recent years have witnessed the perfect encounter of deep learning and quantitative trading has achieved great success in stock investment. Numerous deep learning-based models have been developed for forecasting stock returns, leveraging the powerful representation capabilities of neural networks to identify patterns and factors influencing stock prices. These models can effectively capture general patterns in the market, such as stock price trends, volume-price relationships, and time variations. However, the impact of special irrationality factors -- such as market sentiment, speculative behavior, market manipulation, and psychological biases -- have not been fully considered in existing deep stock forecasting models due to their relative abstraction as well as lack of explicit labels and data description. To fill this gap, we propose UMI, a Universal multi-level Market Irrationality factor model to enhance stock return forecasting. The UMI model learns factors that can reflect irrational behaviors in market from both individual stock and overall market levels. For the stock-level, UMI construct an estimated rational price for each stock, which is cointegrated with the stock's actual price. The discrepancy between the actual and the rational prices serves as a factor to indicate stock-level irrational events. Additionally, we define market-level irrational behaviors as anomalous synchronous fluctuations of stocks within a market. Using two self-supervised representation learning tasks, i.e., sub-market comparative learning and market synchronism prediction, the UMI model incorporates market-level irrationalities into a market representation vector, which is then used as the market-level irrationality factor.
GTG: Generalizable Trajectory Generation Model for Urban Mobility
Feb 03, 2025



Trajectory data mining is crucial for smart city management. However, collecting large-scale trajectory datasets is challenging due to factors such as commercial conflicts and privacy regulations. Therefore, we urgently need trajectory generation techniques to address this issue. Existing trajectory generation methods rely on the global road network structure of cities. When the road network structure changes, these methods are often not transferable to other cities. In fact, there exist invariant mobility patterns between different cities: 1) People prefer paths with the minimal travel cost; 2) The travel cost of roads has an invariant relationship with the topological features of the road network. Based on the above insight, this paper proposes a Generalizable Trajectory Generation model (GTG). The model consists of three parts: 1) Extracting city-invariant road representation based on Space Syntax method; 2) Cross-city travel cost prediction through disentangled adversarial training; 3) Travel preference learning by shortest path search and preference update. By learning invariant movement patterns, the model is capable of generating trajectories in new cities. Experiments on three datasets demonstrates that our model significantly outperforms existing models in terms of generalization ability.
Exact Fit Attention in Node-Holistic Graph Convolutional Network for Improved EEG-Based Driver Fatigue Detection
Jan 25, 2025EEG-based fatigue monitoring can effectively reduce the incidence of related traffic accidents. In the past decade, with the advancement of deep learning, convolutional neural networks (CNN) have been increasingly used for EEG signal processing. However, due to the data's non-Euclidean characteristics, existing CNNs may lose important spatial information from EEG, specifically channel correlation. Thus, we propose the node-holistic graph convolutional network (NHGNet), a model that uses graphic convolution to dynamically learn each channel's features. With exact fit attention optimization, the network captures inter-channel correlations through a trainable adjacency matrix. The interpretability is enhanced by revealing critical areas of brain activity and their interrelations in various mental states. In validations on two public datasets, NHGNet outperforms the SOTAs. Specifically, in the intra-subject, NHGNet improved detection accuracy by at least 2.34% and 3.42%, and in the inter-subjects, it improved by at least 2.09% and 15.06%. Visualization research on the model revealed that the central parietal area plays an important role in detecting fatigue levels, whereas the frontal and temporal lobes are essential for maintaining vigilance.