 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Sparse Customization in Heterogeneous Edge Computing
Paper and Code
Dec 10, 2024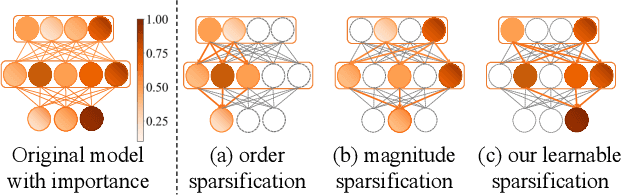
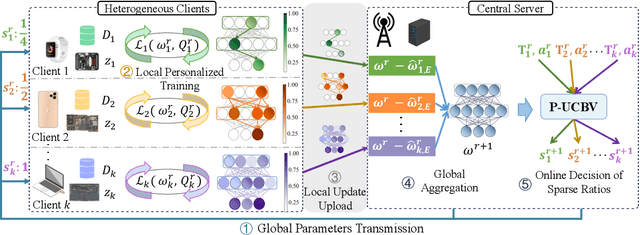


To effectively manage and utilize massive distributed data at the network edge, Federated Learning (FL) has emerged as a promising edge computing paradigm across data silos. However, FL still faces two challenges: system heterogeneity (i.e., the diversity of hardware resources across edge devices) and statistical heterogeneity (i.e., non-IID data). Although sparsification can extract diverse submodels for diverse clients, most sparse FL works either simply assign submodels with artificially-given rigid rules or prune partial parameters using heuristic strategies, resulting in inflexible sparsification and poor performance. In this work, we propose Learnable Personalized Sparsification for heterogeneous Federated learning (FedLPS), which achieves the learnable customization of heterogeneous sparse models with importance-associated patterns and adaptive ratios to simultaneously tackle system and statistical heterogeneity. Specifically, FedLPS learns the importance of model units on local data representation and further derives an importance-based sparse pattern with minimal heuristics to accurately extract personalized data features in non-IID settings. Furthermore, Prompt Upper Confidence Bound Variance (P-UCBV) is designed to adaptively determine sparse ratios by learning the superimposed effect of diverse device capabilities and non-IID data, aiming at resource self-adaptation with promising accuracy. Extensive experiments show that FedLPS outperforms status quo approaches in accuracy and training costs, which improves accuracy by 1.28%-59.34% while reducing running time by more than 68.80%.