 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Large Language Models for Code Vulnerability Detection: An Experimental Study
Dec 24, 2024



Code vulnerability detection (CVD) is essential for addressing and preventing system security issues, playing a crucial role in ensuring software security. Previous learning-based vulnerability detection methods rely on either fine-tuning medium-size sequence models or training smaller neural networks from scratch. Recent advancements in large pre-trained language models (LLMs) have showcased remarkable capabilities in various code intelligence tasks including code understanding and generation. However, the effectiveness of LLMs in detecting code vulnerabilities is largely under-explored. This work aims to investigate the gap by fine-tuning LLMs for the CVD task, involving four widely-used open-source LLMs. We also implement other five previous graph-based or medium-size sequence models for comparison. Experiments are conducted on five commonly-used CVD datasets, including both the part of short samples and long samples. In addition, we conduct quantitative experiments to investigate the class imbalance issue and the model's performance on samples of different lengths, which are rarely studied in previous works. To better facilitate communities, we open-source all codes and resources of this study in https://github.com/SakiRinn/LLM4CVD and https://huggingface.co/datasets/xuefen/VulResource.
Learnable Sparse Customization in Heterogeneous Edge Computing
Dec 10, 2024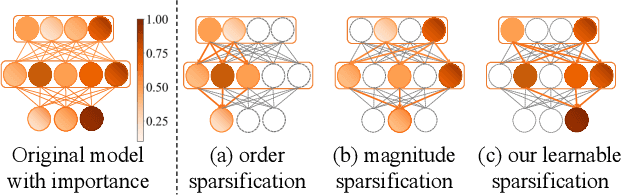
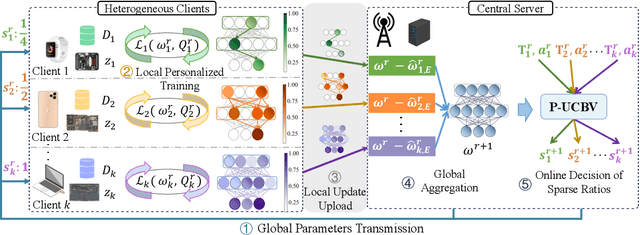


To effectively manage and utilize massive distributed data at the network edge, Federated Learning (FL) has emerged as a promising edge computing paradigm across data silos. However, FL still faces two challenges: system heterogeneity (i.e., the diversity of hardware resources across edge devices) and statistical heterogeneity (i.e., non-IID data). Although sparsification can extract diverse submodels for diverse clients, most sparse FL works either simply assign submodels with artificially-given rigid rules or prune partial parameters using heuristic strategies, resulting in inflexible sparsification and poor performance. In this work, we propose Learnable Personalized Sparsification for heterogeneous Federated learning (FedLPS), which achieves the learnable customization of heterogeneous sparse models with importance-associated patterns and adaptive ratios to simultaneously tackle system and statistical heterogeneity. Specifically, FedLPS learns the importance of model units on local data representation and further derives an importance-based sparse pattern with minimal heuristics to accurately extract personalized data features in non-IID settings. Furthermore, Prompt Upper Confidence Bound Variance (P-UCBV) is designed to adaptively determine sparse ratios by learning the superimposed effect of diverse device capabilities and non-IID data, aiming at resource self-adaptation with promising accuracy. Extensive experiments show that FedLPS outperforms status quo approaches in accuracy and training costs, which improves accuracy by 1.28%-59.34% while reducing running time by more than 68.80%.
Clustering Based on Density Propagation and Subcluster Merging
Nov 04, 2024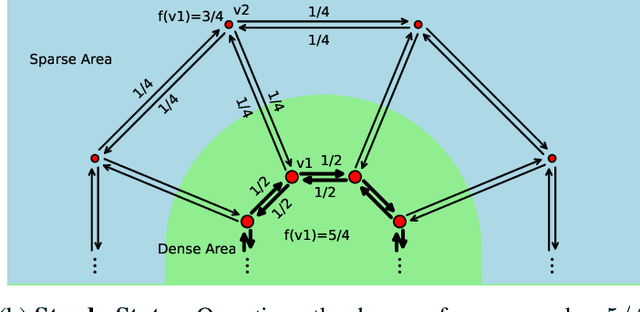
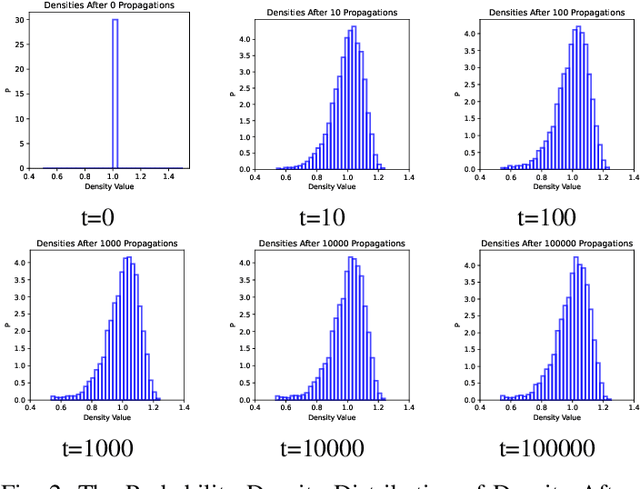
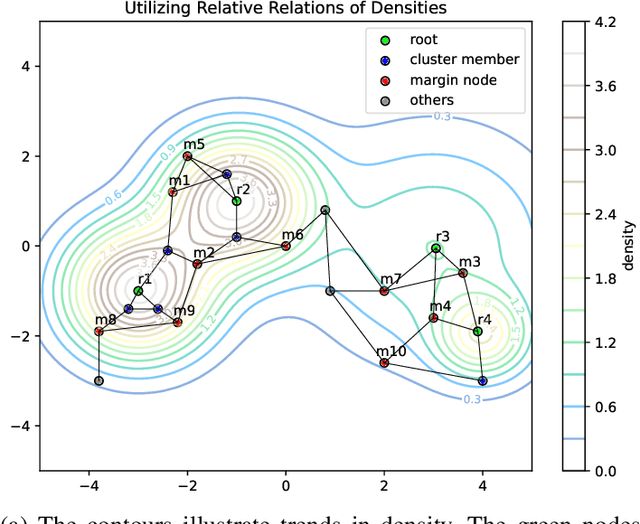
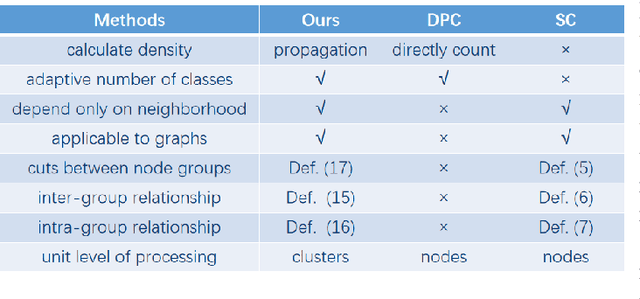
We propose the DPSM method, a density-based node clustering approach that automatically determines the number of clusters and can be applied in both data space and graph space. Unlike traditional density-based clustering methods, which necessitate calculating the distance between any two nodes, our proposed technique determines density through a propagation process, thereby making it suitable for a graph space. In DPSM, nodes are partitioned into small clusters based on propagated density. The partitioning technique has been proved to be sound and complete. We then extend the concept of spectral clustering from individual nodes to these small clusters, while introducing the CluCut measure to guide cluster merging. This measure is modified in various ways to account for cluster properties, thus provides guidance on when to terminate the merging process. Various experiments have validated the effectiveness of DOSM and the accuracy of these conclusions.
Tackling Noisy Clients in Federated Learning with End-to-end Label Correction
Aug 08, 2024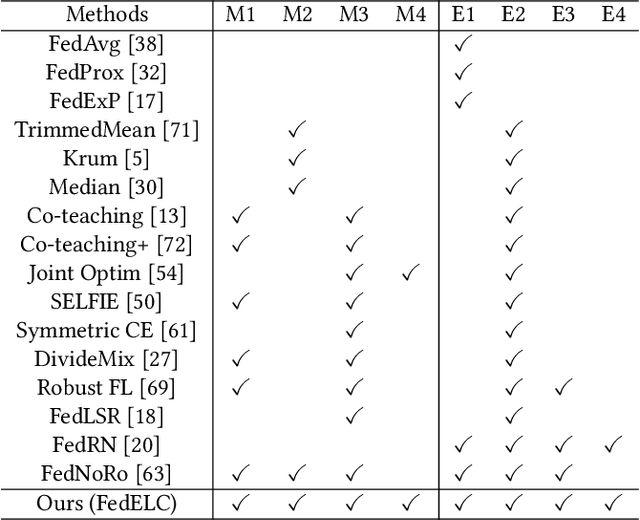
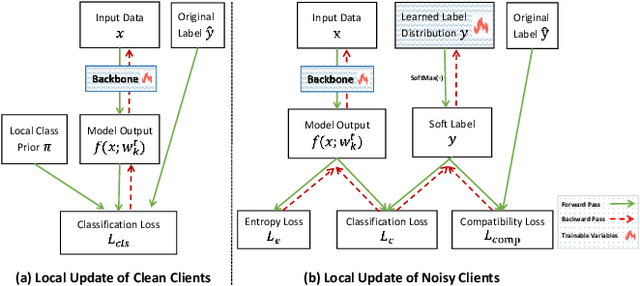

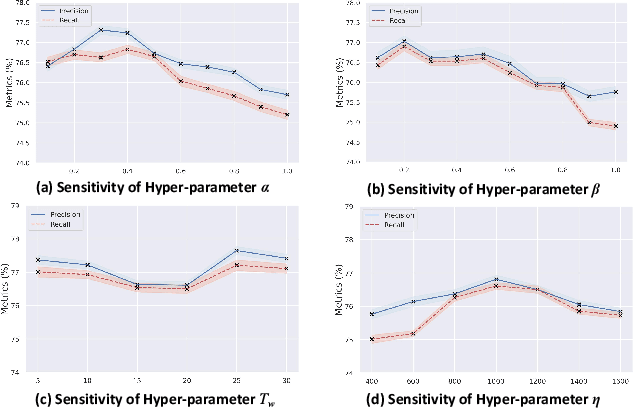
Recently, federated learning (FL) has achieved wide successes for diverse privacy-sensitive applications without sacrificing the sensitive private information of clients. However, the data quality of client datasets can not be guaranteed since corresponding annotations of different clients often contain complex label noise of varying degrees, which inevitably causes the performance degradation. Intuitively, the performance degradation is dominated by clients with higher noise rates since their trained models contain more misinformation from data, thus it is necessary to devise an effective optimization scheme to mitigate the negative impacts of these noisy clients. In this work, we propose a two-stage framework FedELC to tackle this complicated label noise issue. The first stage aims to guide the detection of noisy clients with higher label noise, while the second stage aims to correct the labels of noisy clients' data via an end-to-end label correction framework which is achieved by learning possible ground-truth labels of noisy clients' datasets via back propagation. We implement sixteen related methods and evaluate five datasets with three types of complicated label noise scenarios for a comprehensive comparison. Extensive experimental results demonstrate our proposed framework achieves superior performance than its counterparts for different scenarios. Additionally, we effectively improve the data quality of detected noisy clients' local datasets with our label correction framework. The code is available at https://github.com/Sprinter1999/FedELC.
Personalized Federated Learning for Spatio-Temporal Forecasting: A Dual Semantic Alignment-Based Contrastive Approach
Apr 04, 2024



The existing federated learning (FL) methods for spatio-temporal forecasting fail to capture the inherent spatio-temporal heterogeneity, which calls for personalized FL (PFL) methods to model the spatio-temporally variant patterns. While contrastive learning approach is promising in addressing spatio-temporal heterogeneity, the existing methods are noneffective in determining negative pairs and can hardly apply to PFL paradigm. To tackle this limitation, we propose a novel PFL method, named Federated dUal sEmantic aLignment-based contraStive learning (FUELS), which can adaptively align positive and negative pairs based on semantic similarity, thereby injecting precise spatio-temporal heterogeneity into the latent representation space by auxiliary contrastive tasks. From temporal perspective, a hard negative filtering module is introduced to dynamically align heterogeneous temporal representations for the supplemented intra-client contrastive task. From spatial perspective, we design lightweight-but-efficient prototypes as client-level semantic representations, based on which the server evaluates spatial similarity and yields client-customized global prototypes for the supplemented inter-client contrastive task. Extensive experiments demonstrate that FUELS outperforms state-of-the-art methods, with communication cost decreasing by around 94%.
FedBIAD: Communication-Efficient and Accuracy-Guaranteed Federated Learning with Bayesian Inference-Based Adaptive Dropout
Jul 14, 2023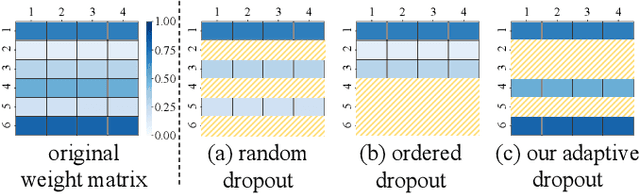

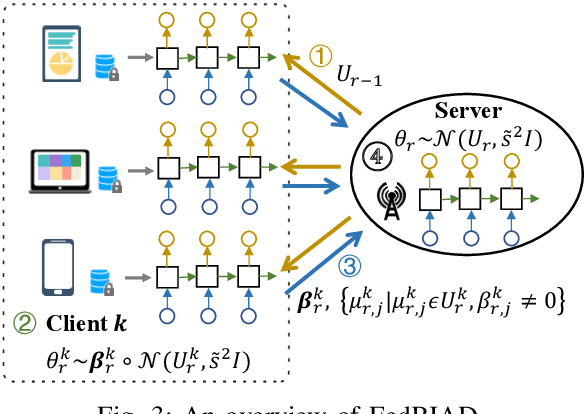

Federated Learning (FL) emerges as a distributed machine learning paradigm without end-user data transmission, effectively avoiding privacy leakage. Participating devices in FL are usually bandwidth-constrained, and the uplink is much slower than the downlink in wireless networks, which causes a severe uplink communication bottleneck. A prominent direction to alleviate this problem is federated dropout, which drops fractional weights of local models. However, existing federated dropout studies focus on random or ordered dropout and lack theoretical support, resulting in unguaranteed performance. In this paper, we propose Federated learning with Bayesian Inference-based Adaptive Dropout (FedBIAD), which regards weight rows of local models as probability distributions and adaptively drops partial weight rows based on importance indicators correlated with the trend of local training loss. By applying FedBIAD, each client adaptively selects a high-quality dropping pattern with accurate approximations and only transmits parameters of non-dropped weight rows to mitigate uplink costs while improving accuracy. Theoretical analysis demonstrates that the convergence rate of the average generalization error of FedBIAD is minimax optimal up to a squared logarithmic factor. Extensive experiments on image classification and next-word prediction show that compared with status quo approaches, FedBIAD provides 2x uplink reduction with an accuracy increase of up to 2.41% even on non-Independent and Identically Distributed (non-IID) data, which brings up to 72% decrease in training time.