 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Noisy Clients in Federated Learning with End-to-end Label Correction
Aug 08, 2024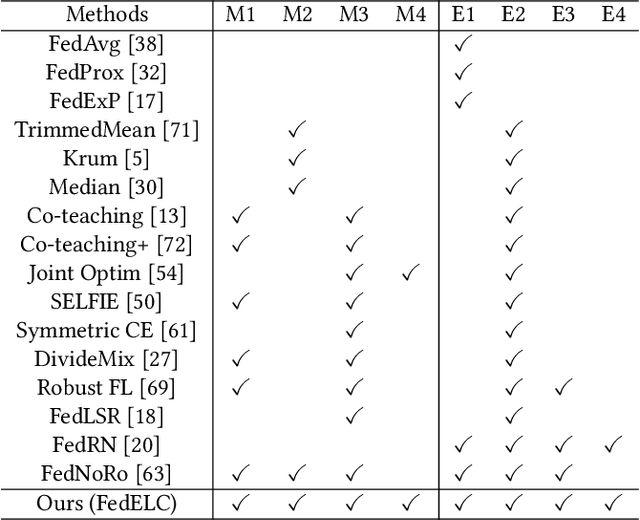
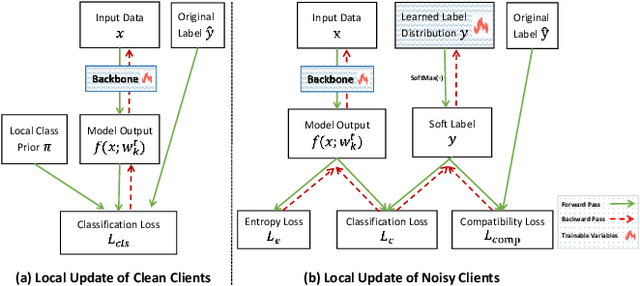

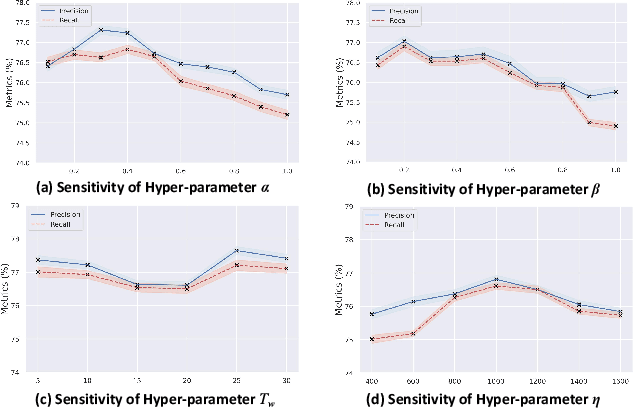
Recently, federated learning (FL) has achieved wide successes for diverse privacy-sensitive applications without sacrificing the sensitive private information of clients. However, the data quality of client datasets can not be guaranteed since corresponding annotations of different clients often contain complex label noise of varying degrees, which inevitably causes the performance degradation. Intuitively, the performance degradation is dominated by clients with higher noise rates since their trained models contain more misinformation from data, thus it is necessary to devise an effective optimization scheme to mitigate the negative impacts of these noisy clients. In this work, we propose a two-stage framework FedELC to tackle this complicated label noise issue. The first stage aims to guide the detection of noisy clients with higher label noise, while the second stage aims to correct the labels of noisy clients' data via an end-to-end label correction framework which is achieved by learning possible ground-truth labels of noisy clients' datasets via back propagation. We implement sixteen related methods and evaluate five datasets with three types of complicated label noise scenarios for a comprehensive comparison. Extensive experimental results demonstrate our proposed framework achieves superior performance than its counterparts for different scenarios. Additionally, we effectively improve the data quality of detected noisy clients' local datasets with our label correction framework. The code is available at https://github.com/Sprinter1999/FedELC.
Federated Skewed Label Learning with Logits Fusion
Nov 14, 2023Federated learning (FL) aims to collaboratively train a shared model across multiple clients without transmitting their local data. Data heterogeneity is a critical challenge in realistic FL settings, as it causes significant performance deterioration due to discrepancies in optimization among local models. In this work, we focus on label distribution skew, a common scenario in data heterogeneity, where the data label categories are imbalanced on each client. To address this issue, we propose FedBalance, which corrects the optimization bias among local models by calibrating their logits. Specifically, we introduce an extra private weak learner on the client side, which forms an ensemble model with the local model. By fusing the logits of the two models, the private weak learner can capture the variance of different data, regardless of their category. Therefore, the optimization direction of local models can be improved by increasing the penalty for misclassifying minority classes and reducing the attention to majority classes, resulting in a better global model. Extensive experiments show that our method can gain 13\% higher average accuracy compared with state-of-the-art methods.
Managed Geo-Distributed Feature Store: Architecture and System Design
May 31, 2023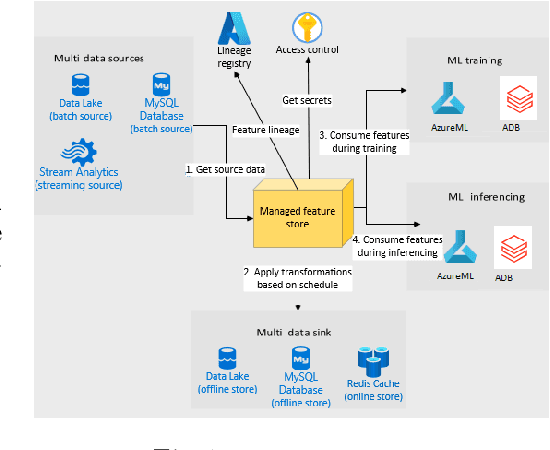

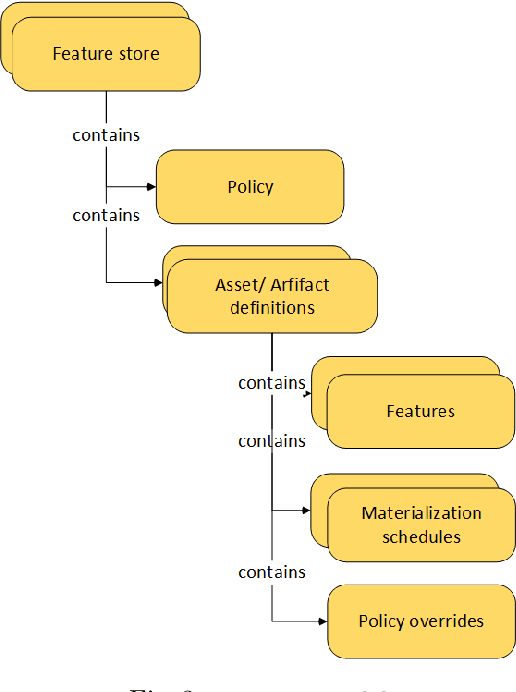
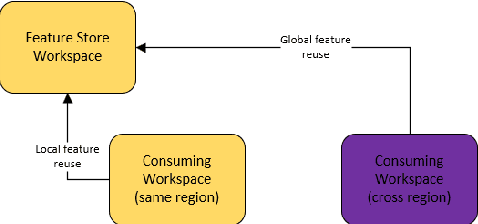
Companies are using machine learning to solve real-world problems and are developing hundreds to thousands of features in the process. They are building feature engineering pipelines as part of MLOps life cycle to transform data from various data sources and materialize the same for future consumption. Without feature stores, different teams across various business groups would maintain the above process independently, which can lead to conflicting and duplicated features in the system. Data scientists find it hard to search for and reuse existing features and it is painful to maintain version control. Furthermore, feature correctness violations related to online (inferencing) - offline (training) skews and data leakage are common. Although the machine learning community has extensively discussed the need for feature stores and their purpose, this paper aims to capture the core architectural components that make up a managed feature store and to share the design learning in building such a system.
Survey of Knowledge Distillation in Federated Edge Learning
Jan 14, 2023The increasing demand for intelligent services and privacy protection of mobile and Internet of Things (IoT) devices motivates the wide application of Federated Edge Learning (FEL), in which devices collaboratively train on-device Machine Learning (ML) models without sharing their private data. \textcolor{black}{Limited by device hardware, diverse user behaviors and network infrastructure, the algorithm design of FEL faces challenges related to resources, personalization and network environments}, and Knowledge Distillation (KD) has been leveraged as an important technique to tackle the above challenges in FEL. In this paper, we investigate the works that KD applies to FEL, discuss the limitations and open problems of existing KD-based FEL approaches, and provide guidance for their real deployment.