 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManaged Geo-Distributed Feature Store: Architecture and System Design
May 31, 2023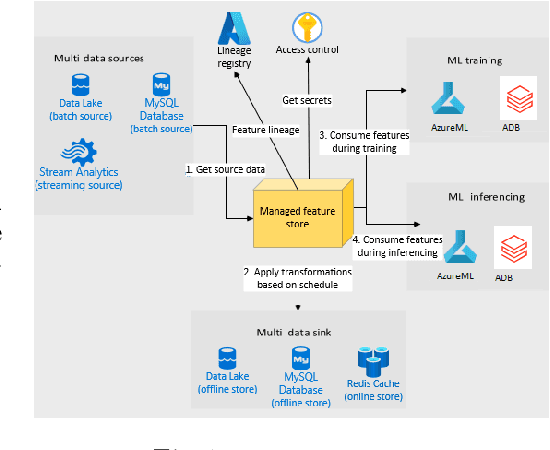

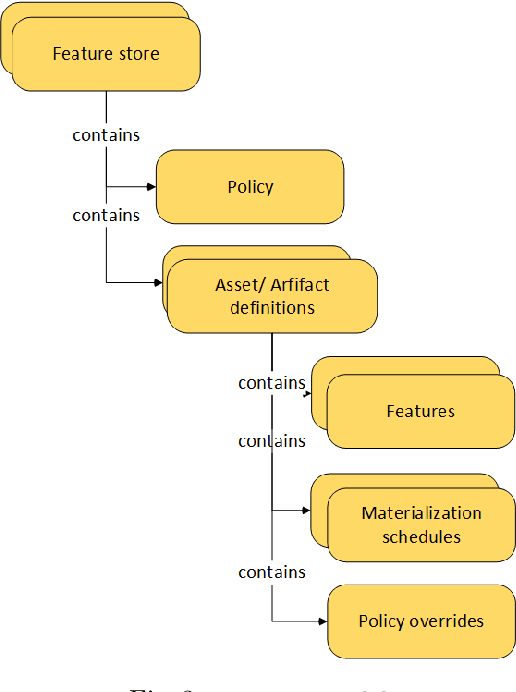
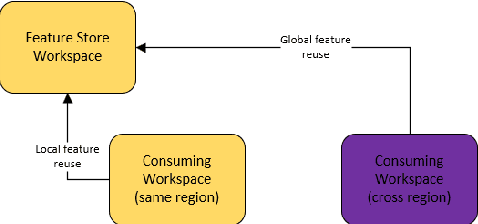
Companies are using machine learning to solve real-world problems and are developing hundreds to thousands of features in the process. They are building feature engineering pipelines as part of MLOps life cycle to transform data from various data sources and materialize the same for future consumption. Without feature stores, different teams across various business groups would maintain the above process independently, which can lead to conflicting and duplicated features in the system. Data scientists find it hard to search for and reuse existing features and it is painful to maintain version control. Furthermore, feature correctness violations related to online (inferencing) - offline (training) skews and data leakage are common. Although the machine learning community has extensively discussed the need for feature stores and their purpose, this paper aims to capture the core architectural components that make up a managed feature store and to share the design learning in building such a system.
Joint Learning of Portrait Intrinsic Decomposition and Relighting
Jun 22, 2021
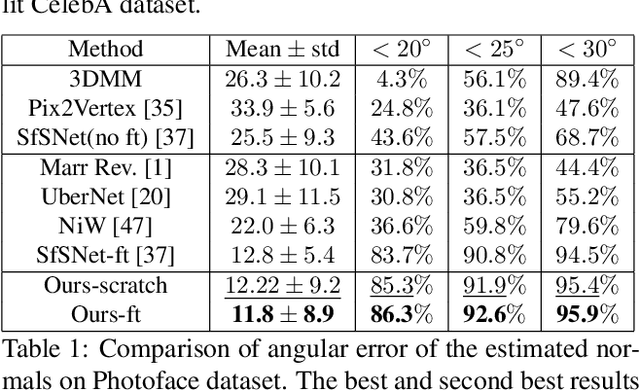
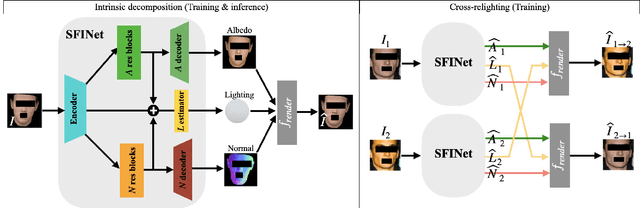
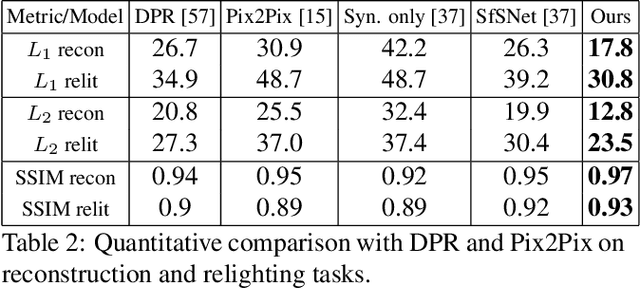
Inverse rendering is the problem of decomposing an image into its intrinsic components, i.e. albedo, normal and lighting. To solve this ill-posed problem from single image, state-of-the-art methods in shape from shading mostly resort to supervised training on all the components on either synthetic or real datasets. Here, we propose a new self-supervised training paradigm that 1) reduces the need for full supervision on the decomposition task and 2) takes into account the relighting task. We introduce new self-supervised loss terms that leverage the consistencies between multi-lit images (images of the same scene under different illuminations). Our approach is applicable to multi-lit datasets. We apply our training approach in two settings: 1) train on a mixture of synthetic and real data, 2) train on real datasets with limited supervision. We show-case the effectiveness of our training paradigm on both intrinsic decomposition and relighting and demonstrate how the model struggles in both tasks without the self-supervised loss terms in limited supervision settings. We provide results of comprehensive experiments on SfSNet, CelebA and Photoface datasets and verify the performance of our approach on images in the wild.