 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Portrait Intrinsic Decomposition and Relighting
Paper and Code
Jun 22, 2021
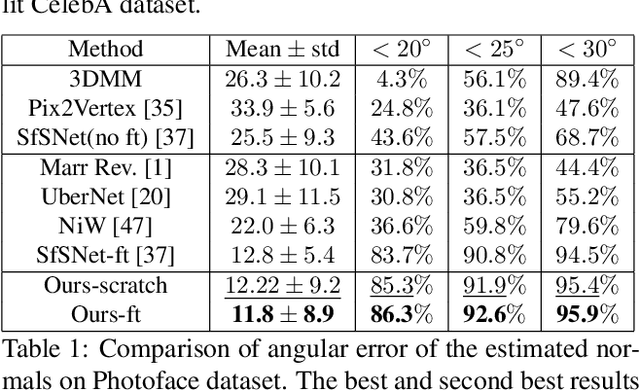
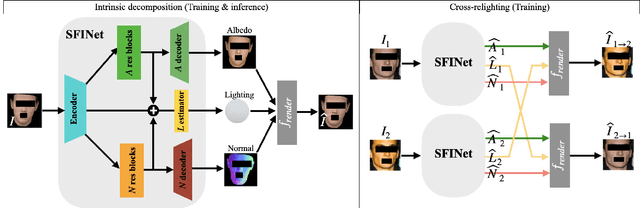
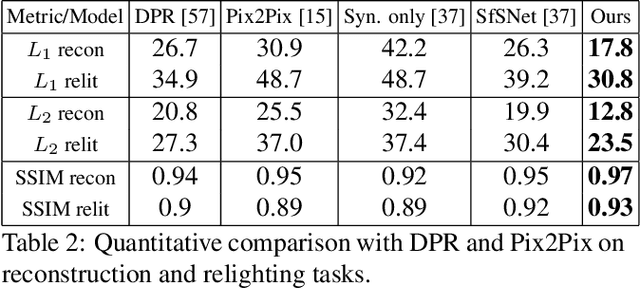
Inverse rendering is the problem of decomposing an image into its intrinsic components, i.e. albedo, normal and lighting. To solve this ill-posed problem from single image, state-of-the-art methods in shape from shading mostly resort to supervised training on all the components on either synthetic or real datasets. Here, we propose a new self-supervised training paradigm that 1) reduces the need for full supervision on the decomposition task and 2) takes into account the relighting task. We introduce new self-supervised loss terms that leverage the consistencies between multi-lit images (images of the same scene under different illuminations). Our approach is applicable to multi-lit datasets. We apply our training approach in two settings: 1) train on a mixture of synthetic and real data, 2) train on real datasets with limited supervision. We show-case the effectiveness of our training paradigm on both intrinsic decomposition and relighting and demonstrate how the model struggles in both tasks without the self-supervised loss terms in limited supervision settings. We provide results of comprehensive experiments on SfSNet, CelebA and Photoface datasets and verify the performance of our approach on images in the wild.