 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Apr 10, 2026Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
Discrete Prototypical Memories for Federated Time Series Foundation Models
Apr 06, 2026Leveraging Large Language Models (LLMs) as federated learning (FL)-based time series foundation models offers a promising way to transfer the generalization capabilities of LLMs to time series data while preserving access to private data. However, the semantic misalignment between time-series data and the text-centric latent space of existing LLMs often leads to degraded performance. Meanwhile, the parameter-sharing mechanism in existing FL methods model heterogeneous cross-domain time-series data into a unified continuous latent space, which contradicts the fact that time-series semantics frequently manifest as discrete and recurring regimes. To address these limitations, we propose \textsc{FeDPM}, a federated framework for time-series foundation models based on discrete prototypical memories. Specifically, we learn local prototypical memory priors for intra-domain time-series data. We then align cross-domain memories to promote a unified discrete latent space and introduce a domain-specific memory update mechanism to balance shared and personalized prototypical knowledge. Extensive experiments demonstrate the efficiency and effectiveness of \textsc{FeDPM}. The code is publicly available at https://anonymous.4open.science/r/FedUnit-64D1.
Red-teaming the Multimodal Reasoning: Jailbreaking Vision-Language Models via Cross-modal Entanglement Attacks
Feb 09, 2026Vision-Language Models (VLMs) with multimodal reasoning capabilities are high-value attack targets, given their potential for handling complex multimodal harmful tasks. Mainstream black-box jailbreak attacks on VLMs work by distributing malicious clues across modalities to disperse model attention and bypass safety alignment mechanisms. However, these adversarial attacks rely on simple and fixed image-text combinations that lack attack complexity scalability, limiting their effectiveness for red-teaming VLMs' continuously evolving reasoning capabilities. We propose \textbf{CrossTALK} (\textbf{\underline{Cross}}-modal en\textbf{\underline{TA}}ng\textbf{\underline{L}}ement attac\textbf{\underline{K}}), which is a scalable approach that extends and entangles information clues across modalities to exceed VLMs' trained and generalized safety alignment patterns for jailbreak. Specifically, {knowledge-scalable reframing} extends harmful tasks into multi-hop chain instructions, {cross-modal clue entangling} migrates visualizable entities into images to build multimodal reasoning links, and {cross-modal scenario nesting} uses multimodal contextual instructions to steer VLMs toward detailed harmful outputs. Experiments show our COMET achieves state-of-the-art attack success rate.
SearchAttack: Red-Teaming LLMs against Real-World Threats via Framing Unsafe Web Information-Seeking Tasks
Jan 07, 2026Recently, people have suffered and become increasingly aware of the unreliability gap in LLMs for open and knowledge-intensive tasks, and thus turn to search-augmented LLMs to mitigate this issue. However, when the search engine is triggered for harmful tasks, the outcome is no longer under the LLM's control. Once the returned content directly contains targeted, ready-to-use harmful takeaways, the LLM's safeguards cannot withdraw that exposure. Motivated by this dilemma, we identify web search as a critical attack surface and propose \textbf{\textit{SearchAttack}} for red-teaming. SearchAttack outsources the harmful semantics to web search, retaining only the query's skeleton and fragmented clues, and further steers LLMs to reconstruct the retrieved content via structural rubrics to achieve malicious goals. Extensive experiments are conducted to red-team the search-augmented LLMs for responsible vulnerability assessment. Empirically, SearchAttack demonstrates strong effectiveness in attacking these systems.
Rationale-Grounded In-Context Learning for Time Series Reasoning with Multimodal Large Language Models
Jan 06, 2026The underperformance of existing multimodal large language models for time series reasoning lies in the absence of rationale priors that connect temporal observations to their downstream outcomes, which leads models to rely on superficial pattern matching rather than principled reasoning. We therefore propose the rationale-grounded in-context learning for time series reasoning, where rationales work as guiding reasoning units rather than post-hoc explanations, and develop the RationaleTS method. Specifically, we firstly induce label-conditioned rationales, composed of reasoning paths from observable evidence to the potential outcomes. Then, we design the hybrid retrieval by balancing temporal patterns and semantic contexts to retrieve correlated rationale priors for the final in-context inference on new samples. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our proposed RationaleTS on three-domain time series reasoning tasks. We will release our code for reproduction.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
PoisonSwarm: Universal Harmful Information Synthesis via Model Crowdsourcing
May 27, 2025To construct responsible and secure AI applications, harmful information data is widely utilized for adversarial testing and the development of safeguards. Existing studies mainly leverage Large Language Models (LLMs) to synthesize data to obtain high-quality task datasets at scale, thereby avoiding costly human annotation. However, limited by the safety alignment mechanisms of LLMs, the synthesis of harmful data still faces challenges in generation reliability and content diversity. In this study, we propose a novel harmful information synthesis framework, PoisonSwarm, which applies the model crowdsourcing strategy to generate diverse harmful data while maintaining a high success rate. Specifically, we generate abundant benign data as the based templates in a counterfactual manner. Subsequently, we decompose each based template into multiple semantic units and perform unit-by-unit toxification and final refinement through dynamic model switching, thus ensuring the success of synthesis. Experimental results demonstrate that PoisonSwarm achieves state-of-the-art performance in synthesizing different categories of harmful data with high scalability and diversity.
TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
FNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025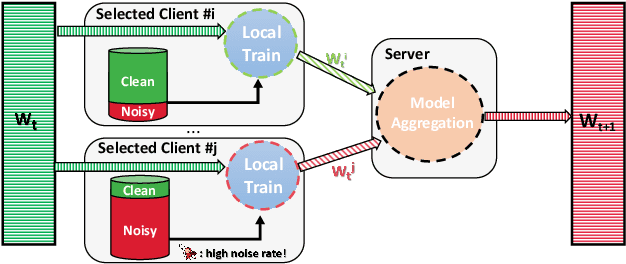
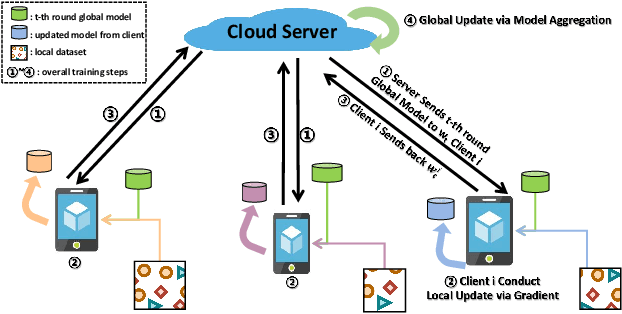
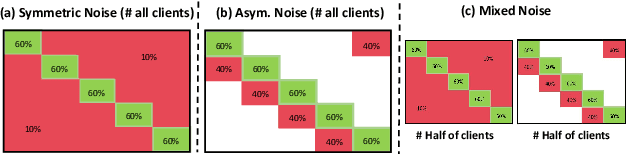
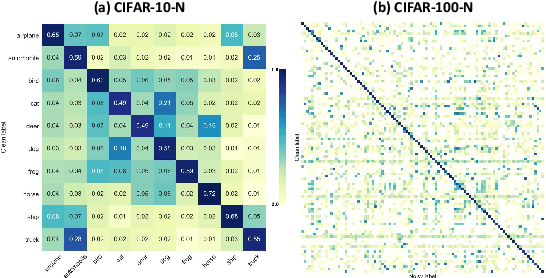
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
Collaborative Stance Detection via Small-Large Language Model Consistency Verification
Feb 27, 2025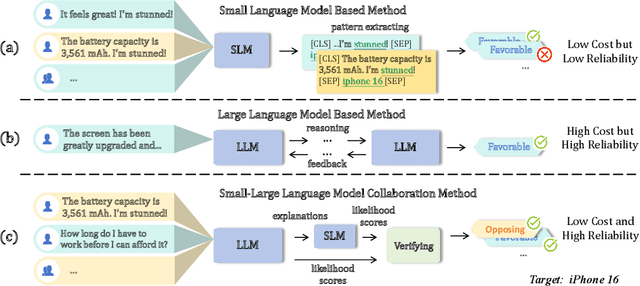
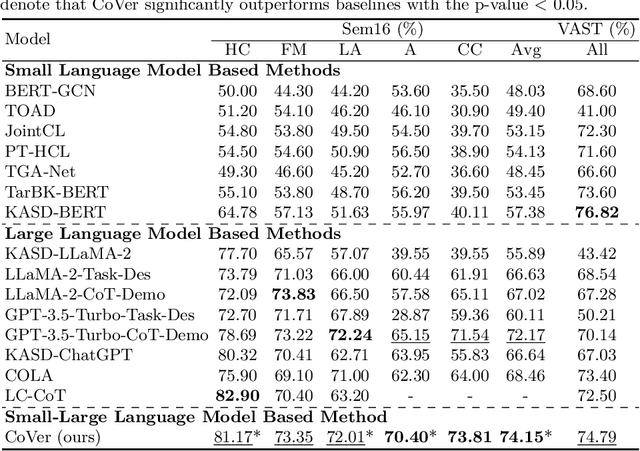
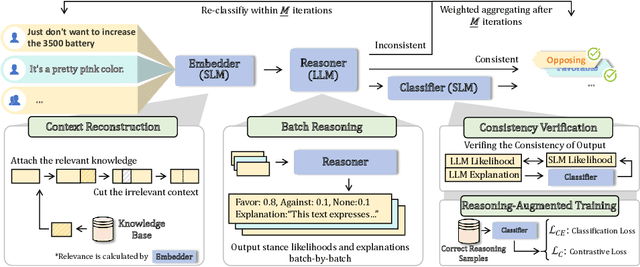
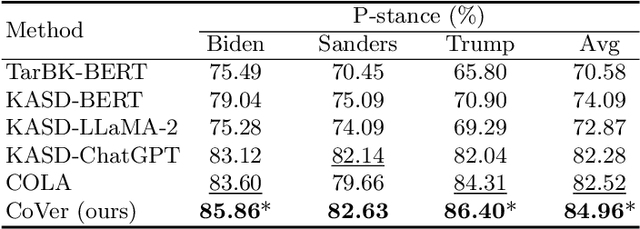
Stance detection on social media aims to identify attitudes expressed in tweets towards specific targets. Current studies prioritize Large Language Models (LLMs) over Small Language Models (SLMs) due to the overwhelming performance improving provided by LLMs. However, heavily relying on LLMs for stance detection, regardless of the cost, is impractical for real-world social media monitoring systems that require vast data analysis. To this end, we propose \textbf{\underline{Co}}llaborative Stance Detection via Small-Large Language Model Consistency \textbf{\underline{Ver}}ification (\textbf{CoVer}) framework, which enhances LLM utilization via context-shared batch reasoning and logical verification between LLM and SLM. Specifically, instead of processing each text individually, CoVer processes texts batch-by-batch, obtaining stance predictions and corresponding explanations via LLM reasoning in a shared context. Then, to exclude the bias caused by context noises, CoVer introduces the SLM for logical consistency verification. Finally, texts that repeatedly exhibit low logical consistency are classified using consistency-weighted aggregation of prior LLM stance predictions. Our experiments show that CoVer outperforms state-of-the-art methods across multiple benchmarks in the zero-shot setting, achieving 0.54 LLM queries per tweet while significantly enhancing performance. Our CoVer offers a more practical solution for LLM deploying for social media stance detection.