 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePegasus: A Universal Framework for Scalable Deep Learning Inference on the Dataplane
Jun 06, 2025The paradigm of Intelligent DataPlane (IDP) embeds deep learning (DL) models on the network dataplane to enable intelligent traffic analysis at line-speed. However, the current use of the match-action table (MAT) abstraction on the dataplane is misaligned with DL inference, leading to several key limitations, including accuracy degradation, limited scale, and lack of generality. This paper proposes Pegasus to address these limitations. Pegasus translates DL operations into three dataplane-oriented primitives to achieve generality: Partition, Map, and SumReduce. Specifically, Partition "divides" high-dimensional features into multiple low-dimensional vectors, making them more suitable for the dataplane; Map "conquers" computations on the low-dimensional vectors in parallel with the technique of fuzzy matching, while SumReduce "combines" the computation results. Additionally, Pegasus employs Primitive Fusion to merge computations, improving scalability. Finally, Pegasus adopts full precision weights with fixed-point activations to improve accuracy. Our implementation on a P4 switch demonstrates that Pegasus can effectively support various types of DL models, including Multi-Layer Perceptron (MLP), Recurrent Neural Network (RNN), Convolutional Neural Network (CNN), and AutoEncoder models on the dataplane. Meanwhile, Pegasus outperforms state-of-the-art approaches with an average accuracy improvement of up to 22.8%, along with up to 248x larger model size and 212x larger input scale.
Learnable Sparse Customization in Heterogeneous Edge Computing
Dec 10, 2024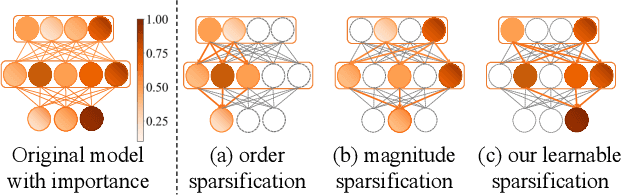
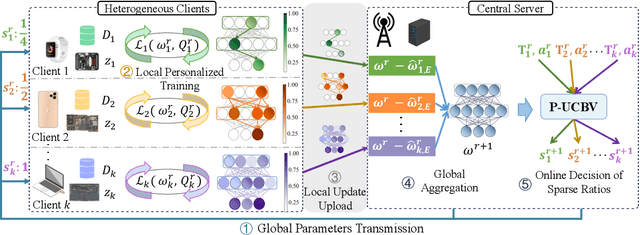


To effectively manage and utilize massive distributed data at the network edge, Federated Learning (FL) has emerged as a promising edge computing paradigm across data silos. However, FL still faces two challenges: system heterogeneity (i.e., the diversity of hardware resources across edge devices) and statistical heterogeneity (i.e., non-IID data). Although sparsification can extract diverse submodels for diverse clients, most sparse FL works either simply assign submodels with artificially-given rigid rules or prune partial parameters using heuristic strategies, resulting in inflexible sparsification and poor performance. In this work, we propose Learnable Personalized Sparsification for heterogeneous Federated learning (FedLPS), which achieves the learnable customization of heterogeneous sparse models with importance-associated patterns and adaptive ratios to simultaneously tackle system and statistical heterogeneity. Specifically, FedLPS learns the importance of model units on local data representation and further derives an importance-based sparse pattern with minimal heuristics to accurately extract personalized data features in non-IID settings. Furthermore, Prompt Upper Confidence Bound Variance (P-UCBV) is designed to adaptively determine sparse ratios by learning the superimposed effect of diverse device capabilities and non-IID data, aiming at resource self-adaptation with promising accuracy. Extensive experiments show that FedLPS outperforms status quo approaches in accuracy and training costs, which improves accuracy by 1.28%-59.34% while reducing running time by more than 68.80%.
Archilles' Heel in Semi-open LLMs: Hiding Bottom against Recovery Attacks
Oct 15, 2024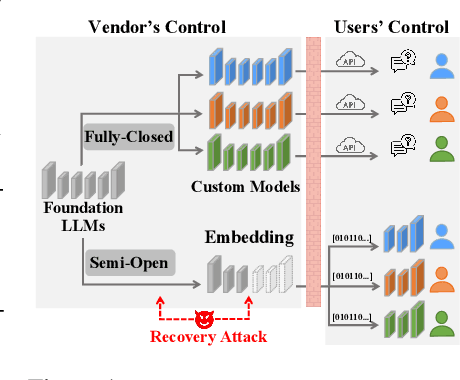
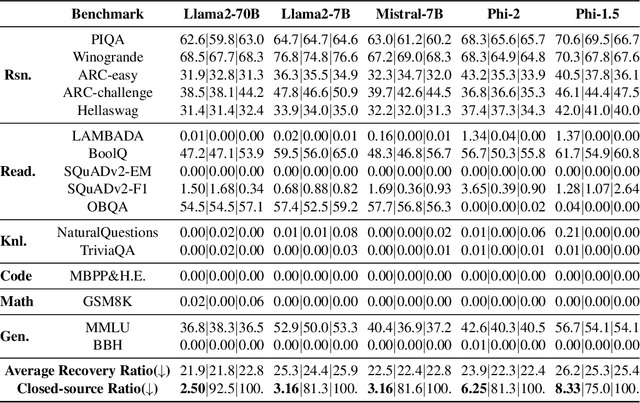
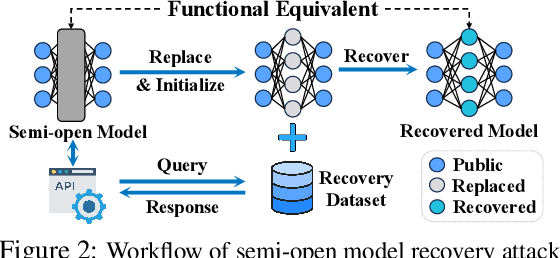
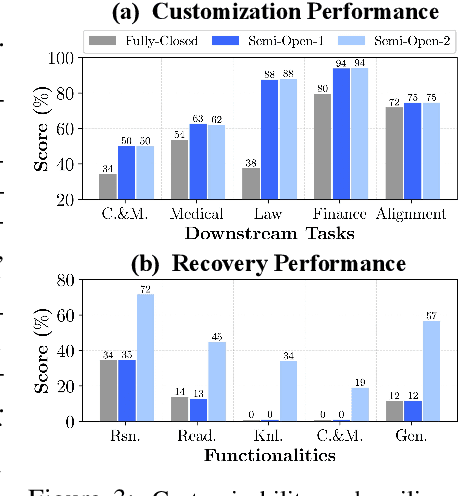
Closed-source large language models deliver strong performance but have limited downstream customizability. Semi-open models, combining both closed-source and public layers, were introduced to improve customizability. However, parameters in the closed-source layers are found vulnerable to recovery attacks. In this paper, we explore the design of semi-open models with fewer closed-source layers, aiming to increase customizability while ensuring resilience to recovery attacks. We analyze the contribution of closed-source layer to the overall resilience and theoretically prove that in a deep transformer-based model, there exists a transition layer such that even small recovery errors in layers before this layer can lead to recovery failure. Building on this, we propose \textbf{SCARA}, a novel approach that keeps only a few bottom layers as closed-source. SCARA employs a fine-tuning-free metric to estimate the maximum number of layers that can be publicly accessible for customization. We apply it to five models (1.3B to 70B parameters) to construct semi-open models, validating their customizability on six downstream tasks and assessing their resilience against various recovery attacks on sixteen benchmarks. We compare SCARA to baselines and observe that it generally improves downstream customization performance and offers similar resilience with over \textbf{10} times fewer closed-source parameters. We empirically investigate the existence of transition layers, analyze the effectiveness of our scheme and finally discuss its limitations.
Towards Fine-Grained Webpage Fingerprinting at Scale
Sep 06, 2024
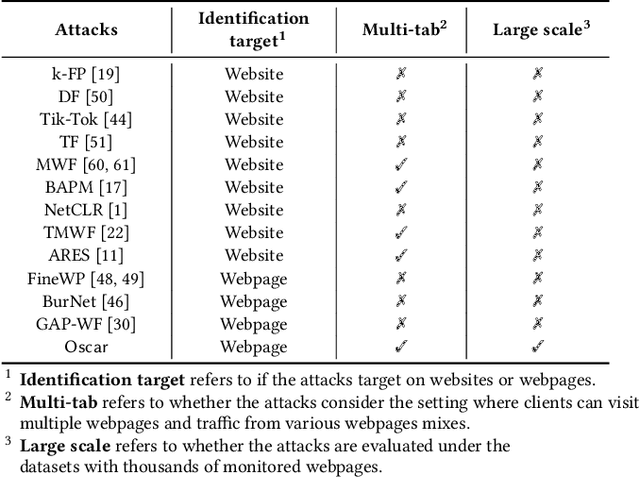
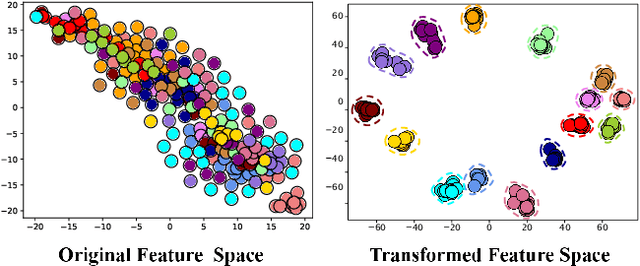

Website Fingerprinting (WF) attacks can effectively identify the websites visited by Tor clients via analyzing encrypted traffic patterns. Existing attacks focus on identifying different websites, but their accuracy dramatically decreases when applied to identify fine-grained webpages, especially when distinguishing among different subpages of the same website. WebPage Fingerprinting (WPF) attacks face the challenges of highly similar traffic patterns and a much larger scale of webpages. Furthermore, clients often visit multiple webpages concurrently, increasing the difficulty of extracting the traffic patterns of each webpage from the obfuscated traffic. In this paper, we propose Oscar, a WPF attack based on multi-label metric learning that identifies different webpages from obfuscated traffic by transforming the feature space. Oscar can extract the subtle differences among various webpages, even those with similar traffic patterns. In particular, Oscar combines proxy-based and sample-based metric learning losses to extract webpage features from obfuscated traffic and identify multiple webpages. We prototype Oscar and evaluate its performance using traffic collected from 1,000 monitored webpages and over 9,000 unmonitored webpages in the real world. Oscar demonstrates an 88.6% improvement in the multi-label metric Recall@5 compared to the state-of-the-art attacks.
Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
Mar 17, 2024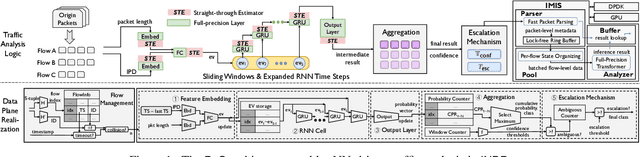
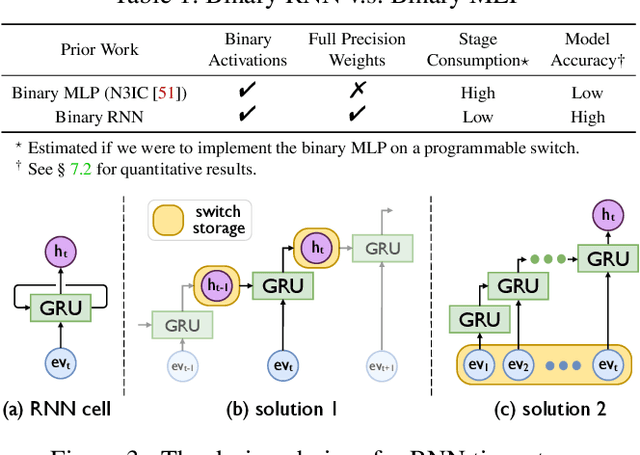
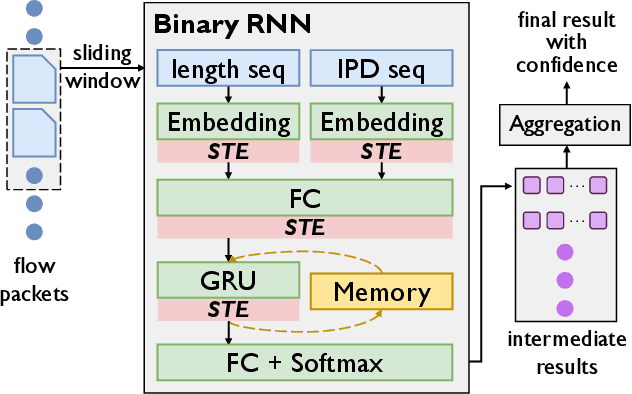
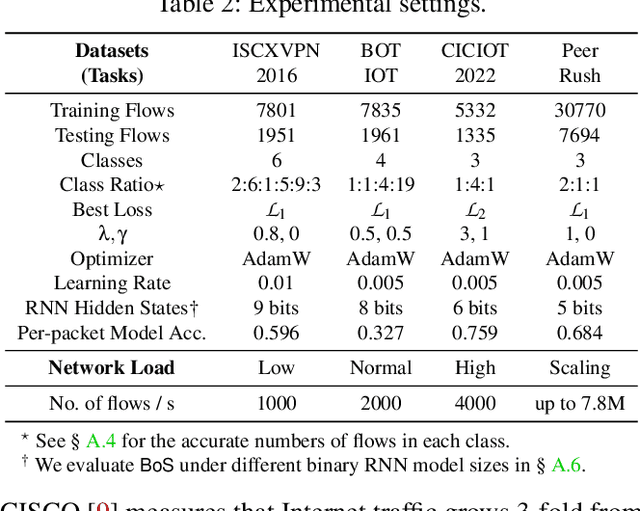
The emerging programmable networks sparked significant research on Intelligent Network Data Plane (INDP), which achieves learning-based traffic analysis at line-speed. Prior art in INDP focus on deploying tree/forest models on the data plane. We observe a fundamental limitation in tree-based INDP approaches: although it is possible to represent even larger tree/forest tables on the data plane, the flow features that are computable on the data plane are fundamentally limited by hardware constraints. In this paper, we present BoS to push the boundaries of INDP by enabling Neural Network (NN) driven traffic analysis at line-speed. Many types of NNs (such as Recurrent Neural Network (RNN), and transformers) that are designed to work with sequential data have advantages over tree-based models, because they can take raw network data as input without complex feature computations on the fly. However, the challenge is significant: the recurrent computation scheme used in RNN inference is fundamentally different from the match-action paradigm used on the network data plane. BoS addresses this challenge by (i) designing a novel data plane friendly RNN architecture that can execute unlimited RNN time steps with limited data plane stages, effectively achieving line-speed RNN inference; and (ii) complementing the on-switch RNN model with an off-switch transformer-based traffic analysis module to further boost the overall performance. We implement a prototype of BoS using a P4 programmable switch as our data plane, and extensively evaluate it over multiple traffic analysis tasks. The results show that BoS outperforms state-of-the-art in both analysis accuracy and scalability.
Pencil: Private and Extensible Collaborative Learning without the Non-Colluding Assumption
Mar 17, 2024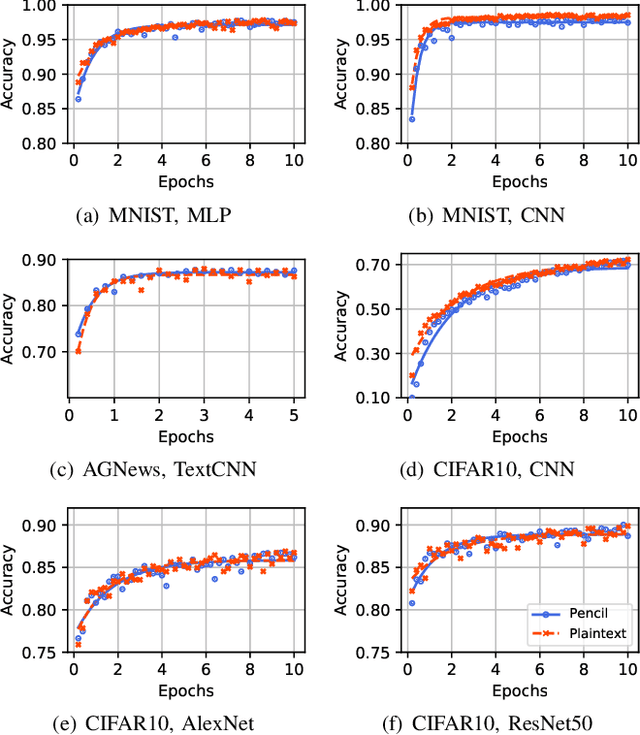
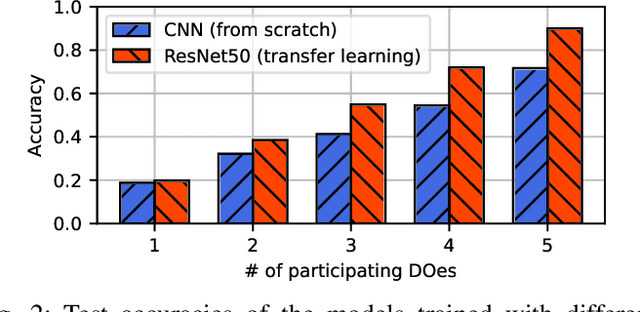


The escalating focus on data privacy poses significant challenges for collaborative neural network training, where data ownership and model training/deployment responsibilities reside with distinct entities. Our community has made substantial contributions to addressing this challenge, proposing various approaches such as federated learning (FL) and privacy-preserving machine learning based on cryptographic constructs like homomorphic encryption (HE) and secure multiparty computation (MPC). However, FL completely overlooks model privacy, and HE has limited extensibility (confined to only one data provider). While the state-of-the-art MPC frameworks provide reasonable throughput and simultaneously ensure model/data privacy, they rely on a critical non-colluding assumption on the computing servers, and relaxing this assumption is still an open problem. In this paper, we present Pencil, the first private training framework for collaborative learning that simultaneously offers data privacy, model privacy, and extensibility to multiple data providers, without relying on the non-colluding assumption. Our fundamental design principle is to construct the n-party collaborative training protocol based on an efficient two-party protocol, and meanwhile ensuring that switching to different data providers during model training introduces no extra cost. We introduce several novel cryptographic protocols to realize this design principle and conduct a rigorous security and privacy analysis. Our comprehensive evaluations of Pencil demonstrate that (i) models trained in plaintext and models trained privately using Pencil exhibit nearly identical test accuracies; (ii) The training overhead of Pencil is greatly reduced: Pencil achieves 10 ~ 260x higher throughput and 2 orders of magnitude less communication than prior art; (iii) Pencil is resilient against both existing and adaptive (white-box) attacks.
* Network and Distributed System Security Symposium (NDSS) 2024
Defending Against Data Reconstruction Attacks in Federated Learning: An Information Theory Approach
Mar 02, 2024
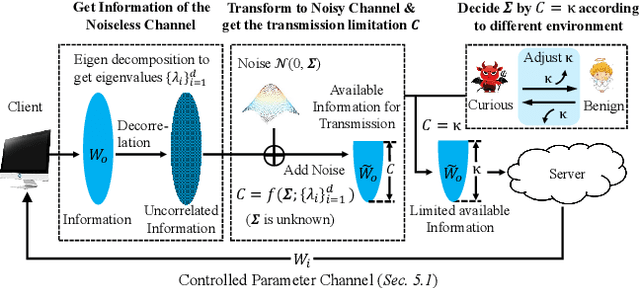
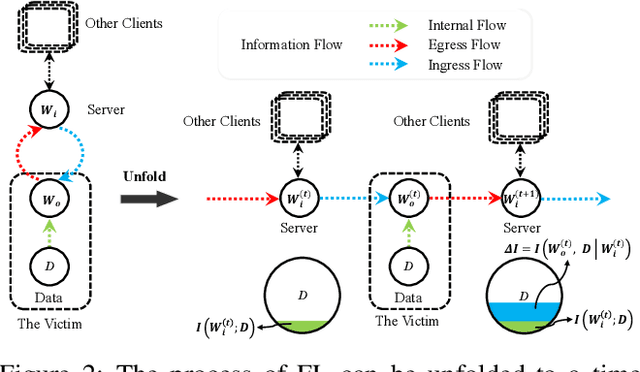
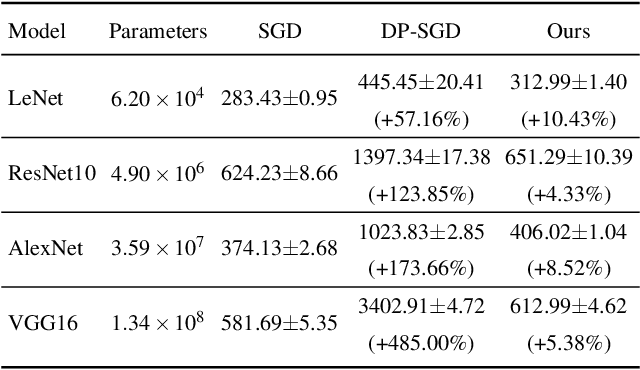
Federated Learning (FL) trains a black-box and high-dimensional model among different clients by exchanging parameters instead of direct data sharing, which mitigates the privacy leak incurred by machine learning. However, FL still suffers from membership inference attacks (MIA) or data reconstruction attacks (DRA). In particular, an attacker can extract the information from local datasets by constructing DRA, which cannot be effectively throttled by existing techniques, e.g., Differential Privacy (DP). In this paper, we aim to ensure a strong privacy guarantee for FL under DRA. We prove that reconstruction errors under DRA are constrained by the information acquired by an attacker, which means that constraining the transmitted information can effectively throttle DRA. To quantify the information leakage incurred by FL, we establish a channel model, which depends on the upper bound of joint mutual information between the local dataset and multiple transmitted parameters. Moreover, the channel model indicates that the transmitted information can be constrained through data space operation, which can improve training efficiency and the model accuracy under constrained information. According to the channel model, we propose algorithms to constrain the information transmitted in a single round of local training. With a limited number of training rounds, the algorithms ensure that the total amount of transmitted information is limited. Furthermore, our channel model can be applied to various privacy-enhancing techniques (such as DP) to enhance privacy guarantees against DRA. Extensive experiments with real-world datasets validate the effectiveness of our methods.
LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers
May 28, 2023Prior works have attempted to build private inference frameworks for transformer-based large language models (LLMs) in a server-client setting, where the server holds the model parameters and the client inputs the private data for inference. However, these frameworks impose significant overhead when the private inputs are forward propagated through the original LLMs. In this paper, we show that substituting the computation- and communication-heavy operators in the transformer architecture with privacy-computing friendly approximations can greatly reduce the private inference costs with minor impact on model performance. Compared to the state-of-the-art Iron (NeurIPS 2022), our privacy-computing friendly model inference pipeline achieves a $5\times$ acceleration in computation and an 80\% reduction in communication overhead, while retaining nearly identical accuracy.
A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021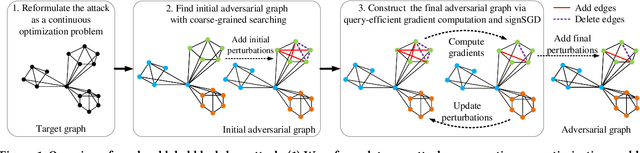
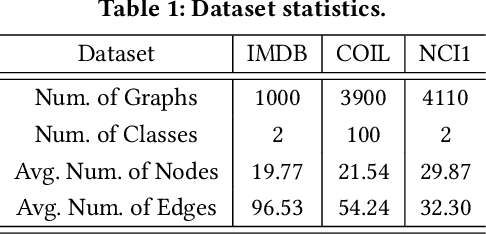
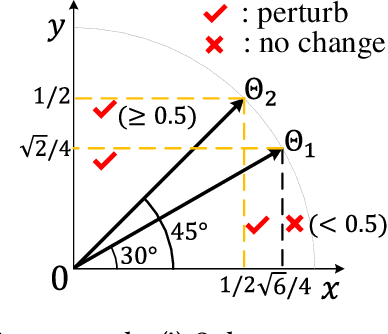
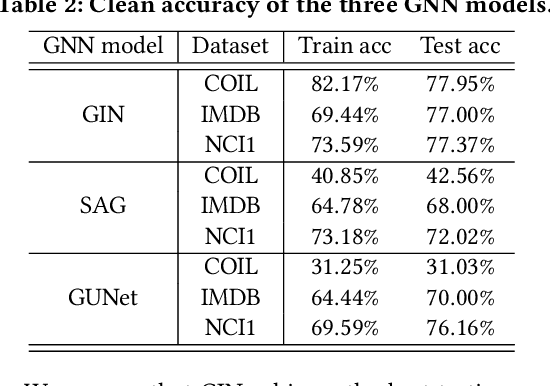
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.