 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021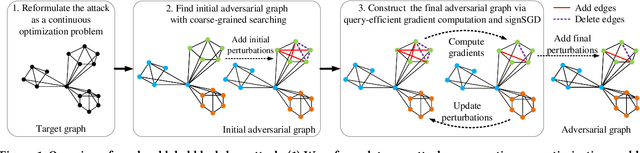
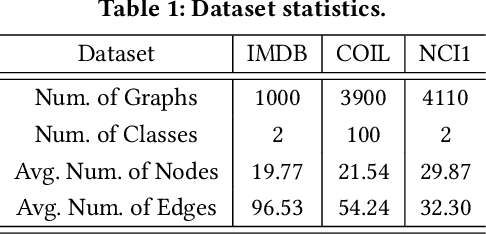
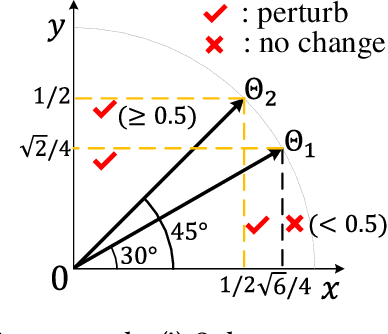
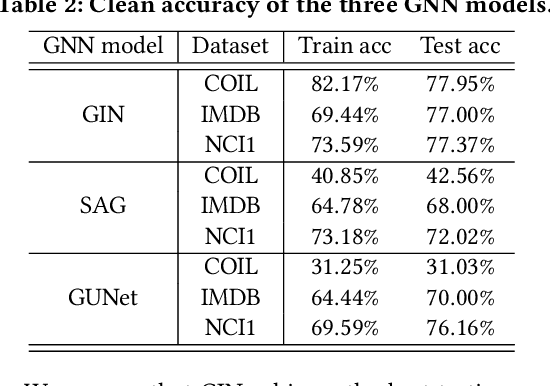
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.
Data Poisoning Attacks to Deep Learning Based Recommender Systems
Jan 08, 2021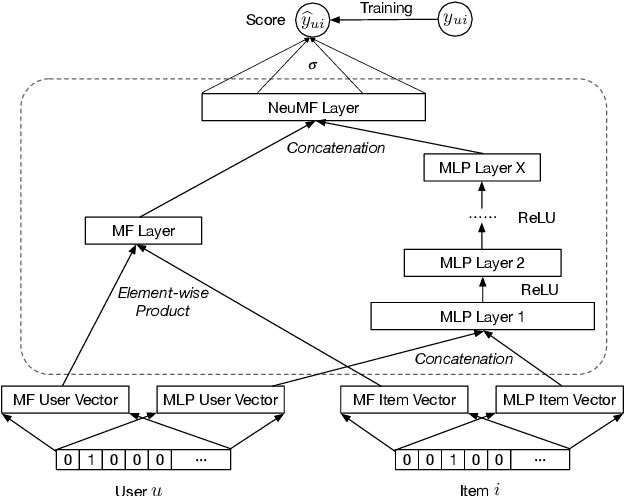
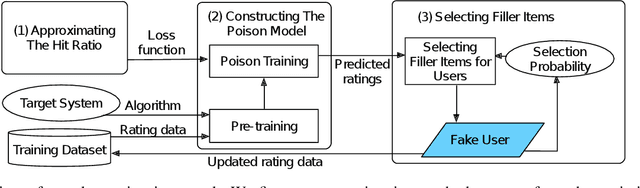
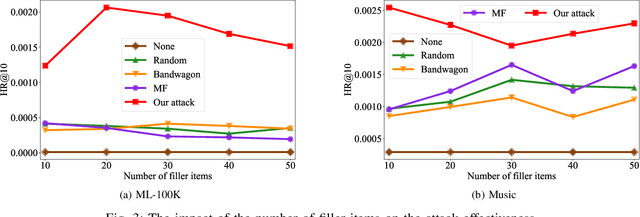
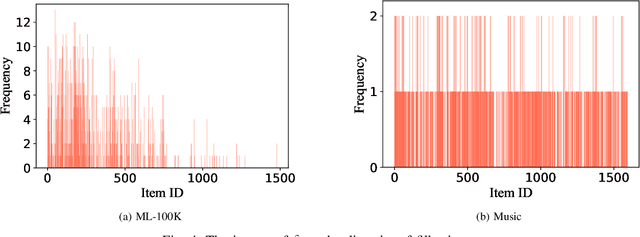
Recommender systems play a crucial role in helping users to find their interested information in various web services such as Amazon, YouTube, and Google News. Various recommender systems, ranging from neighborhood-based, association-rule-based, matrix-factorization-based, to deep learning based, have been developed and deployed in industry. Among them, deep learning based recommender systems become increasingly popular due to their superior performance. In this work, we conduct the first systematic study on data poisoning attacks to deep learning based recommender systems. An attacker's goal is to manipulate a recommender system such that the attacker-chosen target items are recommended to many users. To achieve this goal, our attack injects fake users with carefully crafted ratings to a recommender system. Specifically, we formulate our attack as an optimization problem, such that the injected ratings would maximize the number of normal users to whom the target items are recommended. However, it is challenging to solve the optimization problem because it is a non-convex integer programming problem. To address the challenge, we develop multiple techniques to approximately solve the optimization problem. Our experimental results on three real-world datasets, including small and large datasets, show that our attack is effective and outperforms existing attacks. Moreover, we attempt to detect fake users via statistical analysis of the rating patterns of normal and fake users. Our results show that our attack is still effective and outperforms existing attacks even if such a detector is deployed.