 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Gods and Broken Screens: Architecting a Secure, Intent-Centric Mobile Agent Operating System
Feb 13, 2026The evolution of Large Language Models (LLMs) has shifted mobile computing from App-centric interactions to system-level autonomous agents. Current implementations predominantly rely on a "Screen-as-Interface" paradigm, which inherits structural vulnerabilities and conflicts with the mobile ecosystem's economic foundations. In this paper, we conduct a systematic security analysis of state-of-the-art mobile agents using Doubao Mobile Assistant as a representative case. We decompose the threat landscape into four dimensions - Agent Identity, External Interface, Internal Reasoning, and Action Execution - revealing critical flaws such as fake App identity, visual spoofing, indirect prompt injection, and unauthorized privilege escalation stemming from a reliance on unstructured visual data. To address these challenges, we propose Aura, an Agent Universal Runtime Architecture for a clean-slate secure agent OS. Aura replaces brittle GUI scraping with a structured, agent-native interaction model. It adopts a Hub-and-Spoke topology where a privileged System Agent orchestrates intent, sandboxed App Agents execute domain-specific tasks, and the Agent Kernel mediates all communication. The Agent Kernel enforces four defense pillars: (i) cryptographic identity binding via a Global Agent Registry; (ii) semantic input sanitization through a multilayer Semantic Firewall; (iii) cognitive integrity via taint-aware memory and plan-trajectory alignment; and (iv) granular access control with non-deniable auditing. Evaluation on MobileSafetyBench shows that, compared to Doubao, Aura improves low-risk Task Success Rate from roughly 75% to 94.3%, reduces high-risk Attack Success Rate from roughly 40% to 4.4%, and achieves near-order-of-magnitude latency gains. These results demonstrate Aura as a viable, secure alternative to the "Screen-as-Interface" paradigm.
Softmax Linear Attention: Reclaiming Global Competition
Feb 02, 2026While linear attention reduces the quadratic complexity of standard Transformers to linear time, it often lags behind in expressivity due to the removal of softmax normalization. This omission eliminates \emph{global competition}, a critical mechanism that enables models to sharply focus on relevant information amidst long-context noise. In this work, we propose \textbf{Softmax Linear Attention (SLA)}, a framework designed to restore this competitive selection without sacrificing efficiency. By lifting the softmax operation from the token level to the head level, SLA leverages attention heads as coarse semantic slots, applying a competitive gating mechanism to dynamically select the most relevant subspaces. This reintroduces the ``winner-take-all'' dynamics essential for precise retrieval and robust long-context understanding. Distinct from prior methods that focus on refining local kernel functions, SLA adopts a broader perspective by exploiting the higher-level multi-head aggregation structure. Extensive experiments demonstrate that SLA consistently enhances state-of-the-art linear baselines (RetNet, GLA, GDN) across language modeling and long-context benchmarks, particularly in challenging retrieval scenarios where it significantly boosts robustness against noise, validating its capability to restore precise focus while maintaining linear complexity.
FlowletFormer: Network Behavioral Semantic Aware Pre-training Model for Traffic Classification
Aug 27, 2025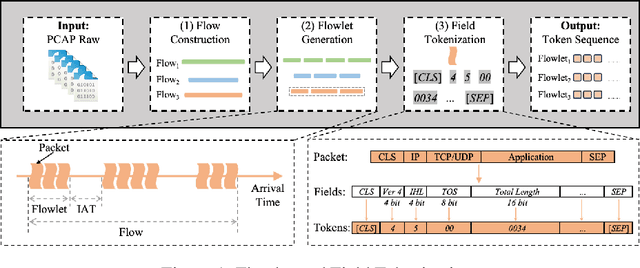
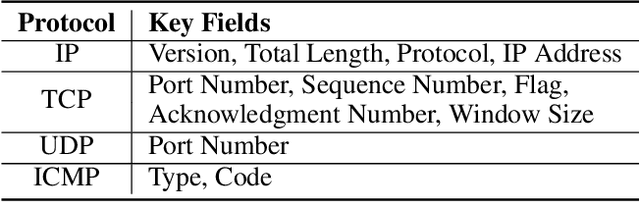
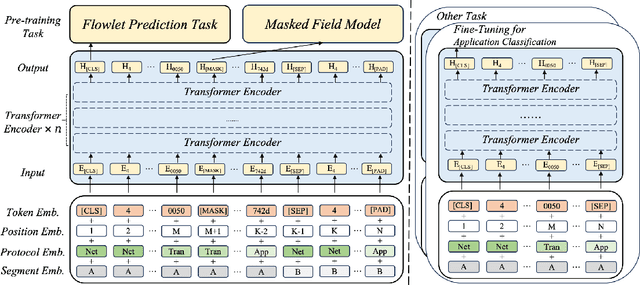
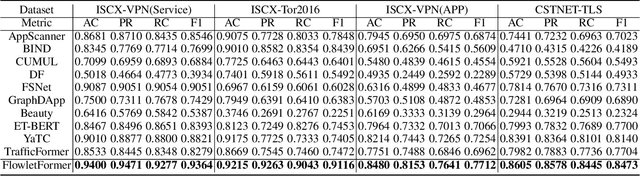
Network traffic classification using pre-training models has shown promising results, but existing methods struggle to capture packet structural characteristics, flow-level behaviors, hierarchical protocol semantics, and inter-packet contextual relationships. To address these challenges, we propose FlowletFormer, a BERT-based pre-training model specifically designed for network traffic analysis. FlowletFormer introduces a Coherent Behavior-Aware Traffic Representation Model for segmenting traffic into semantically meaningful units, a Protocol Stack Alignment-Based Embedding Layer to capture multilayer protocol semantics, and Field-Specific and Context-Aware Pretraining Tasks to enhance both inter-packet and inter-flow learning. Experimental results demonstrate that FlowletFormer significantly outperforms existing methods in the effectiveness of traffic representation, classification accuracy, and few-shot learning capability. Moreover, by effectively integrating domain-specific network knowledge, FlowletFormer shows better comprehension of the principles of network transmission (e.g., stateful connections of TCP), providing a more robust and trustworthy framework for traffic analysis.
Homogeneous Keys, Heterogeneous Values: Exploiting Local KV Cache Asymmetry for Long-Context LLMs
Jun 04, 2025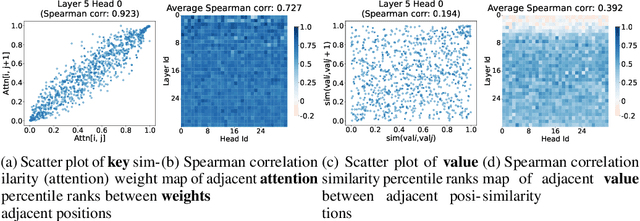
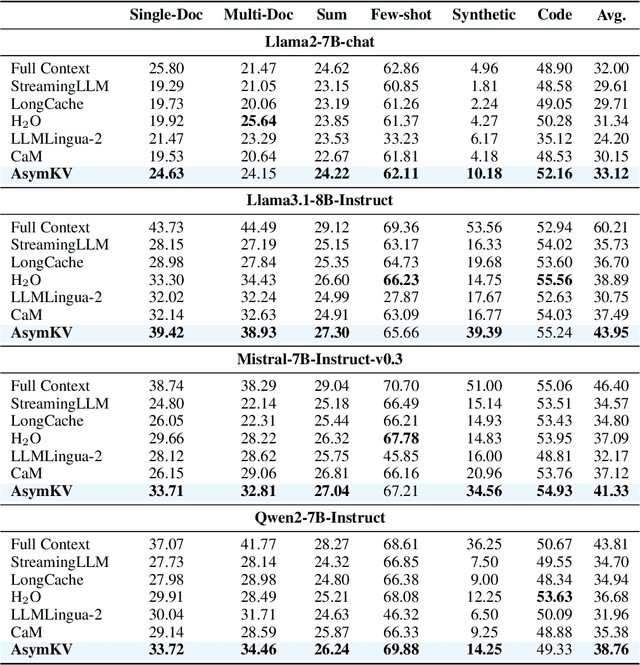
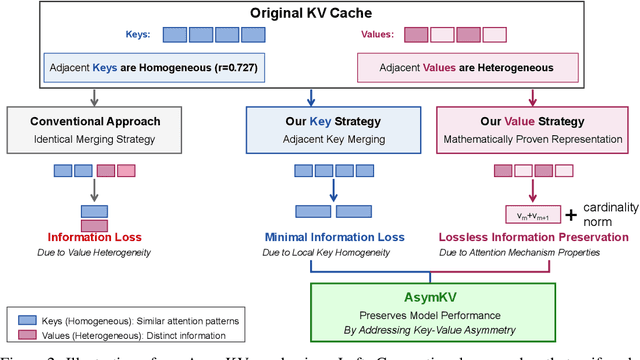
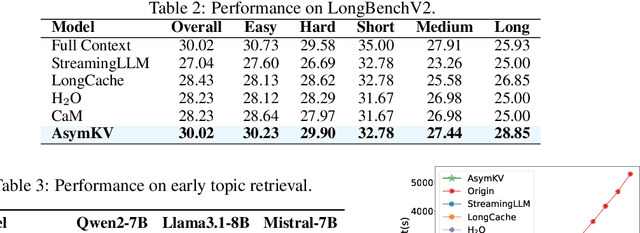
Recent advances in Large Language Models (LLMs) have highlighted the critical importance of extending context length, yet the quadratic complexity of attention mechanisms poses significant challenges for efficient long-context modeling. KV cache compression has emerged as a key approach to address this challenge. Through extensive empirical analysis, we reveal a fundamental yet previously overlooked asymmetry in KV caches: while adjacent keys receive similar attention weights (local homogeneity), adjacent values demonstrate distinct heterogeneous distributions. This key-value asymmetry reveals a critical limitation in existing compression methods that treat keys and values uniformly. To address the limitation, we propose a training-free compression framework (AsymKV) that combines homogeneity-based key merging with a mathematically proven lossless value compression. Extensive experiments demonstrate that AsymKV consistently outperforms existing long-context methods across various tasks and base models. For example, on LLaMA3.1-8B, AsymKV achieves an average score of 43.95 on LongBench, surpassing SOTA methods like H$_2$O (38.89) by a large margin.
Brain-on-Switch: Towards Advanced Intelligent Network Data Plane via NN-Driven Traffic Analysis at Line-Speed
Mar 17, 2024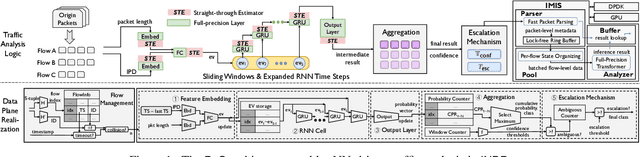
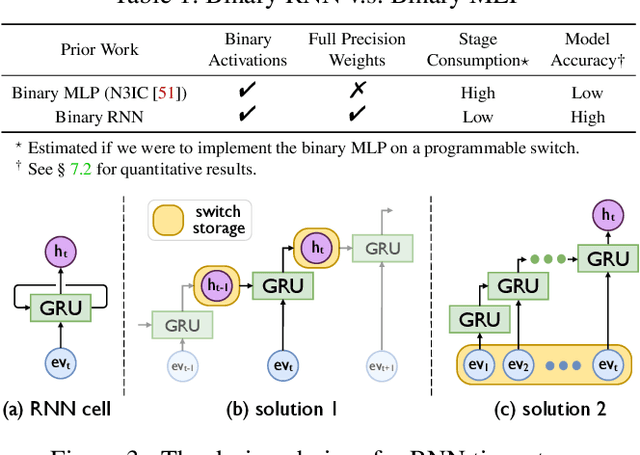
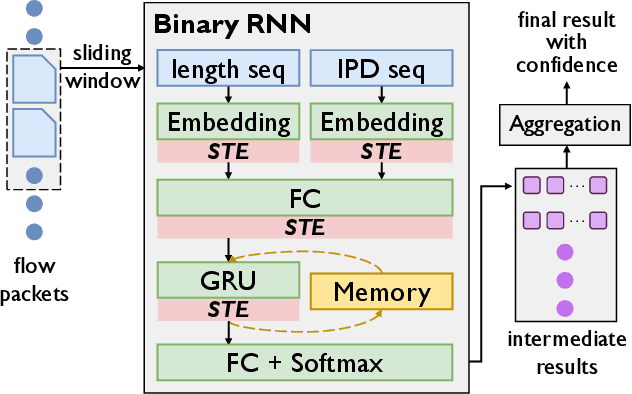
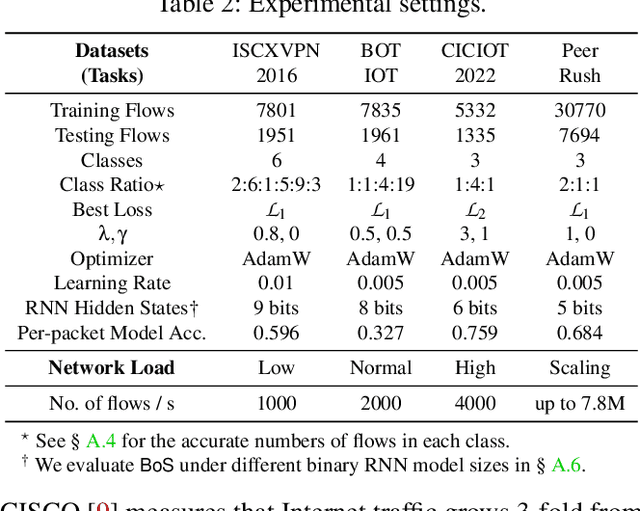
The emerging programmable networks sparked significant research on Intelligent Network Data Plane (INDP), which achieves learning-based traffic analysis at line-speed. Prior art in INDP focus on deploying tree/forest models on the data plane. We observe a fundamental limitation in tree-based INDP approaches: although it is possible to represent even larger tree/forest tables on the data plane, the flow features that are computable on the data plane are fundamentally limited by hardware constraints. In this paper, we present BoS to push the boundaries of INDP by enabling Neural Network (NN) driven traffic analysis at line-speed. Many types of NNs (such as Recurrent Neural Network (RNN), and transformers) that are designed to work with sequential data have advantages over tree-based models, because they can take raw network data as input without complex feature computations on the fly. However, the challenge is significant: the recurrent computation scheme used in RNN inference is fundamentally different from the match-action paradigm used on the network data plane. BoS addresses this challenge by (i) designing a novel data plane friendly RNN architecture that can execute unlimited RNN time steps with limited data plane stages, effectively achieving line-speed RNN inference; and (ii) complementing the on-switch RNN model with an off-switch transformer-based traffic analysis module to further boost the overall performance. We implement a prototype of BoS using a P4 programmable switch as our data plane, and extensively evaluate it over multiple traffic analysis tasks. The results show that BoS outperforms state-of-the-art in both analysis accuracy and scalability.
Pencil: Private and Extensible Collaborative Learning without the Non-Colluding Assumption
Mar 17, 2024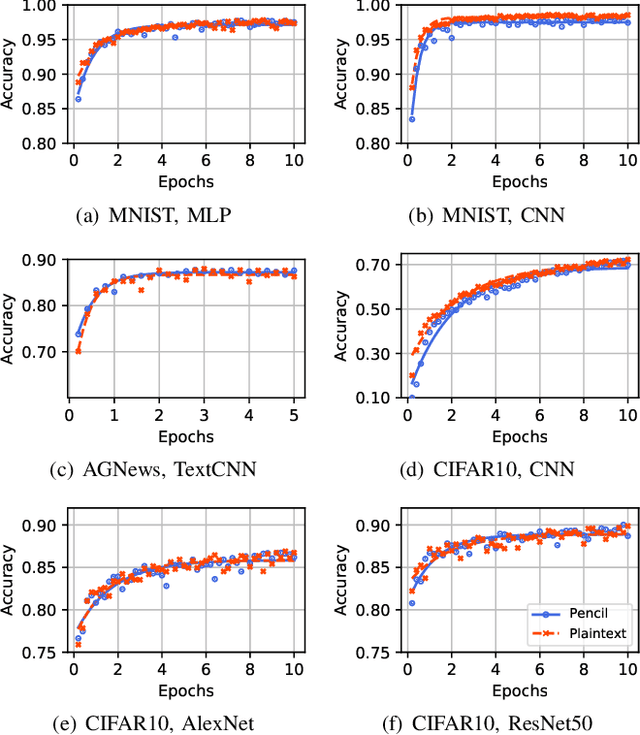
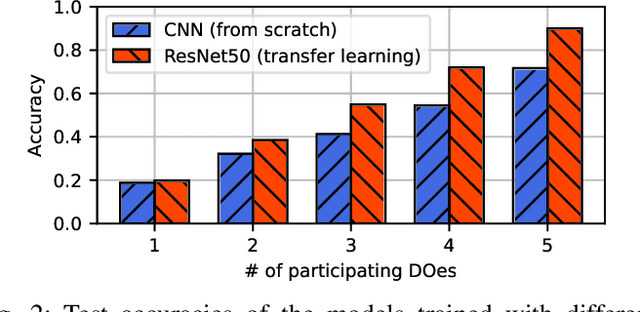


The escalating focus on data privacy poses significant challenges for collaborative neural network training, where data ownership and model training/deployment responsibilities reside with distinct entities. Our community has made substantial contributions to addressing this challenge, proposing various approaches such as federated learning (FL) and privacy-preserving machine learning based on cryptographic constructs like homomorphic encryption (HE) and secure multiparty computation (MPC). However, FL completely overlooks model privacy, and HE has limited extensibility (confined to only one data provider). While the state-of-the-art MPC frameworks provide reasonable throughput and simultaneously ensure model/data privacy, they rely on a critical non-colluding assumption on the computing servers, and relaxing this assumption is still an open problem. In this paper, we present Pencil, the first private training framework for collaborative learning that simultaneously offers data privacy, model privacy, and extensibility to multiple data providers, without relying on the non-colluding assumption. Our fundamental design principle is to construct the n-party collaborative training protocol based on an efficient two-party protocol, and meanwhile ensuring that switching to different data providers during model training introduces no extra cost. We introduce several novel cryptographic protocols to realize this design principle and conduct a rigorous security and privacy analysis. Our comprehensive evaluations of Pencil demonstrate that (i) models trained in plaintext and models trained privately using Pencil exhibit nearly identical test accuracies; (ii) The training overhead of Pencil is greatly reduced: Pencil achieves 10 ~ 260x higher throughput and 2 orders of magnitude less communication than prior art; (iii) Pencil is resilient against both existing and adaptive (white-box) attacks.
* Network and Distributed System Security Symposium (NDSS) 2024
Aggregation Weighting of Federated Learning via Generalization Bound Estimation
Nov 10, 2023

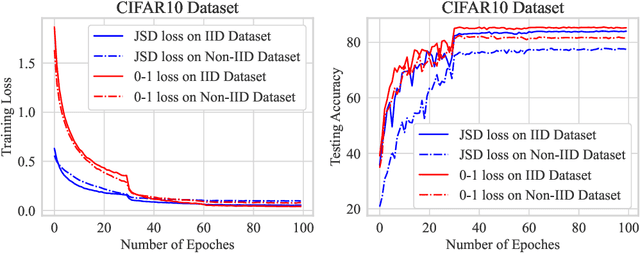

Federated Learning (FL) typically aggregates client model parameters using a weighting approach determined by sample proportions. However, this naive weighting method may lead to unfairness and degradation in model performance due to statistical heterogeneity and the inclusion of noisy data among clients. Theoretically, distributional robustness analysis has shown that the generalization performance of a learning model with respect to any shifted distribution is bounded. This motivates us to reconsider the weighting approach in federated learning. In this paper, we replace the aforementioned weighting method with a new strategy that considers the generalization bounds of each local model. Specifically, we estimate the upper and lower bounds of the second-order origin moment of the shifted distribution for the current local model, and then use these bounds disagreements as the aggregation proportions for weightings in each communication round. Experiments demonstrate that the proposed weighting strategy significantly improves the performance of several representative FL algorithms on benchmark datasets.
FERN: Leveraging Graph Attention Networks for Failure Evaluation and Robust Network Design
May 30, 2023



Robust network design, which aims to guarantee network availability under various failure scenarios while optimizing performance/cost objectives, has received significant attention. Existing approaches often rely on model-based mixed-integer optimization that is hard to scale or employ deep learning to solve specific engineering problems yet with limited generalizability. In this paper, we show that failure evaluation provides a common kernel to improve the tractability and scalability of existing solutions. By providing a neural network function approximation of this common kernel using graph attention networks, we develop a unified learning-based framework, FERN, for scalable Failure Evaluation and Robust Network design. FERN represents rich problem inputs as a graph and captures both local and global views by attentively performing feature extraction from the graph. It enables a broad range of robust network design problems, including robust network validation, network upgrade optimization, and fault-tolerant traffic engineering that are discussed in this paper, to be recasted with respect to the common kernel and thus computed efficiently using neural networks and over a small set of critical failure scenarios. Extensive experiments on real-world network topologies show that FERN can efficiently and accurately identify key failure scenarios for both OSPF and optimal routing scheme, and generalizes well to different topologies and input traffic patterns. It can speed up multiple robust network design problems by more than 80x, 200x, 10x, respectively with negligible performance gap.
A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021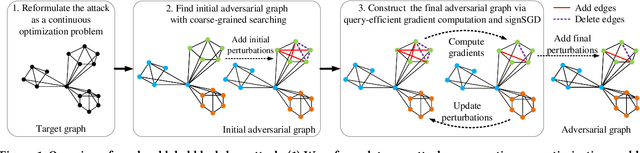
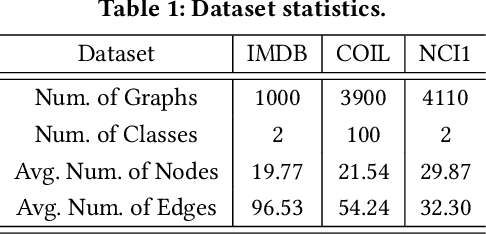
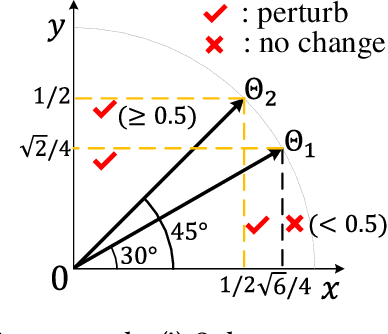
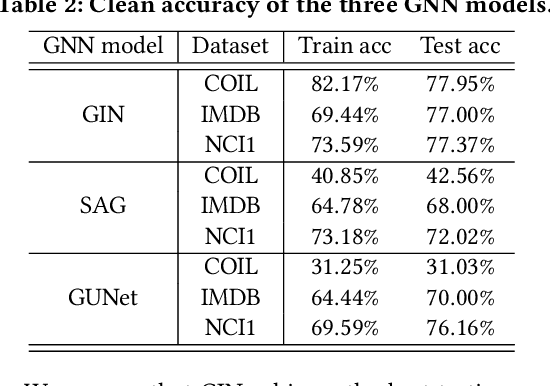
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.
Optimal Multi-Manipulator Arm Placement for Maximal Dexterity during Robotics Surgery
Apr 13, 2021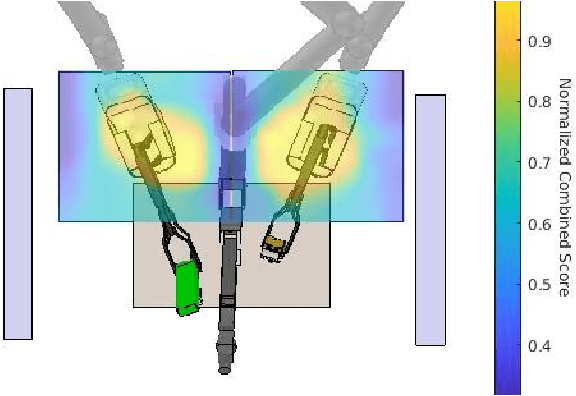
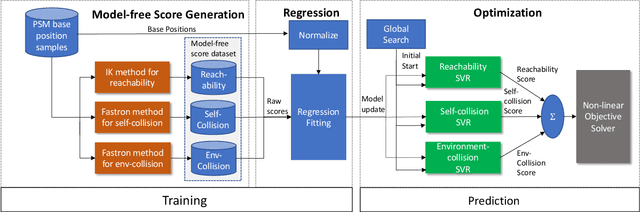
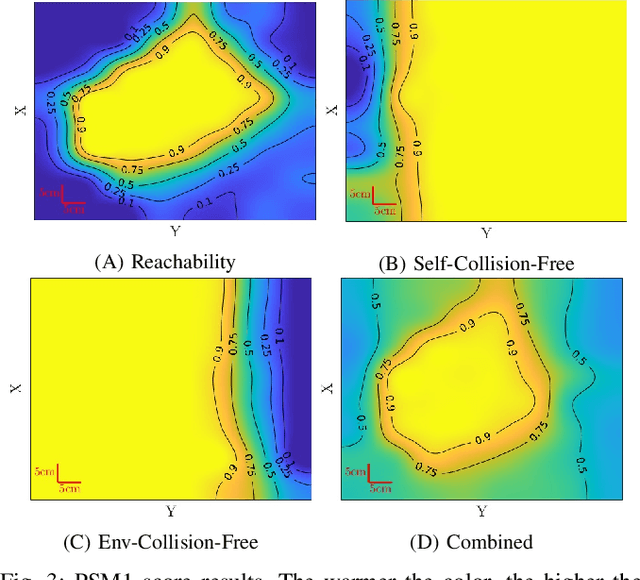
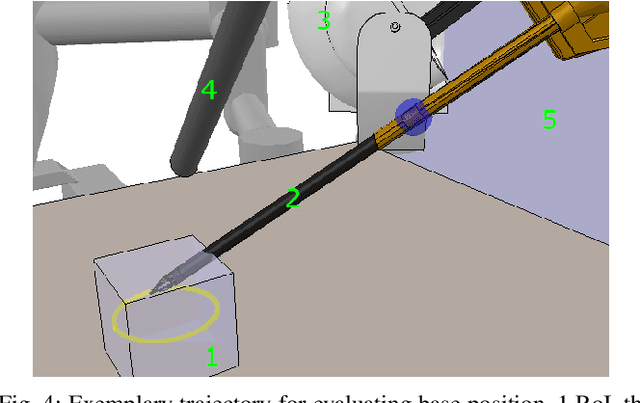
Robot arm placements are oftentimes a limitation in surgical preoperative procedures, relying on trained staff to evaluate and decide on the optimal positions for the arms. Given new and different patient anatomies, it can be challenging to make an informed choice, leading to more frequently colliding arms or limited manipulator workspaces. In this paper, we develop a method to generate the optimal manipulator base positions for the multi-port da Vinci surgical system that minimizes self-collision and environment-collision, and maximizes the surgeon's reachability inside the patient. Scoring functions are defined for each criterion so that they may be optimized over. Since for multi-manipulator setups, a large number of free parameters are available to adjust the base positioning of each arm, a challenge becomes how one can expediently assess possible setups. We thus also propose methods that perform fast queries of each measure with the use of a proxy collision-checker. We then develop an optimization method to determine the optimal position using the scoring functions. We evaluate the optimality of the base positions for the robot arms on canonical trajectories, and show that the solution yielded by the optimization program can satisfy each criterion. The metrics and optimization strategy are generalizable to other surgical robotic platforms so that patient-side manipulator positioning may be optimized and solved.