 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSentry: Mitigating Indirect Prompt Injection in LLM Agents via Temporal Causal Diagnostics and Context Purification
Feb 26, 2026Large language model (LLM) agents increasingly rely on external tools and retrieval systems to autonomously complete complex tasks. However, this design exposes agents to indirect prompt injection (IPI), where attacker-controlled context embedded in tool outputs or retrieved content silently steers agent actions away from user intent. Unlike prompt-based attacks, IPI unfolds over multi-turn trajectories, making malicious control difficult to disentangle from legitimate task execution. Existing inference-time defenses primarily rely on heuristic detection and conservative blocking of high-risk actions, which can prematurely terminate workflows or broadly suppress tool usage under ambiguous multi-turn scenarios. We propose AgentSentry, a novel inference-time detection and mitigation framework for tool-augmented LLM agents. To the best of our knowledge, AgentSentry is the first inference-time defense to model multi-turn IPI as a temporal causal takeover. It localizes takeover points via controlled counterfactual re-executions at tool-return boundaries and enables safe continuation through causally guided context purification that removes attack-induced deviations while preserving task-relevant evidence. We evaluate AgentSentry on the \textsc{AgentDojo} benchmark across four task suites, three IPI attack families, and multiple black-box LLMs. AgentSentry eliminates successful attacks and maintains strong utility under attack, achieving an average Utility Under Attack (UA) of 74.55 %, improving UA by 20.8 to 33.6 percentage points over the strongest baselines without degrading benign performance.
AI-Cybersecurity Education Through Designing AI-based Cyberharassment Detection Lab
May 16, 2024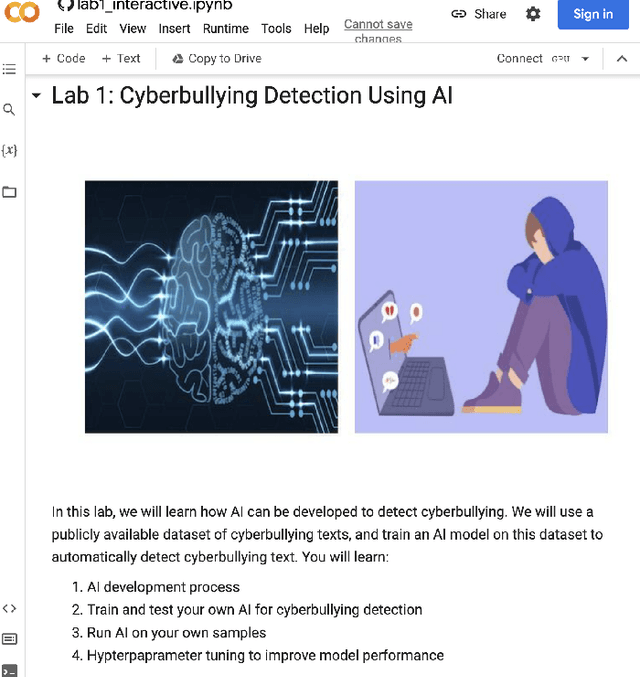


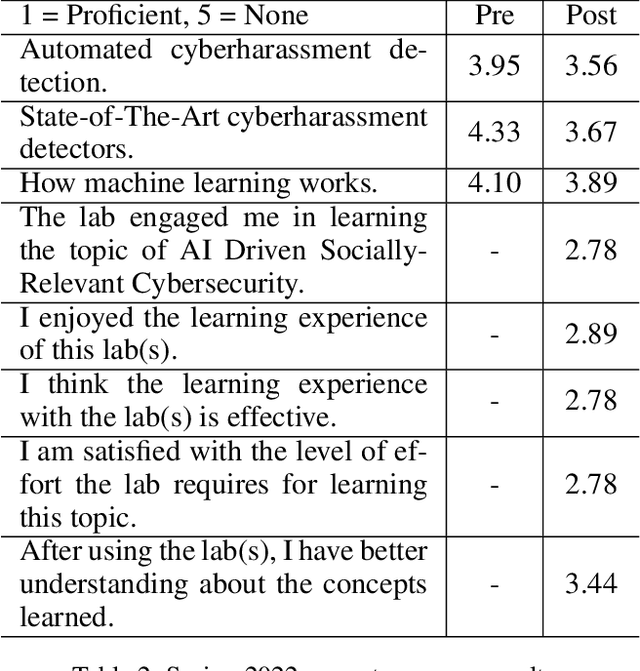
Cyberharassment is a critical, socially relevant cybersecurity problem because of the adverse effects it can have on targeted groups or individuals. While progress has been made in understanding cyber-harassment, its detection, attacks on artificial intelligence (AI) based cyberharassment systems, and the social problems in cyberharassment detectors, little has been done in designing experiential learning educational materials that engage students in this emerging social cybersecurity in the era of AI. Experiential learning opportunities are usually provided through capstone projects and engineering design courses in STEM programs such as computer science. While capstone projects are an excellent example of experiential learning, given the interdisciplinary nature of this emerging social cybersecurity problem, it can be challenging to use them to engage non-computing students without prior knowledge of AI. Because of this, we were motivated to develop a hands-on lab platform that provided experiential learning experiences to non-computing students with little or no background knowledge in AI and discussed the lessons learned in developing this lab. In this lab used by social science students at North Carolina A&T State University across two semesters (spring and fall) in 2022, students are given a detailed lab manual and are to complete a set of well-detailed tasks. Through this process, students learn AI concepts and the application of AI for cyberharassment detection. Using pre- and post-surveys, we asked students to rate their knowledge or skills in AI and their understanding of the concepts learned. The results revealed that the students moderately understood the concepts of AI and cyberharassment.
Moderating Illicit Online Image Promotion for Unsafe User-Generated Content Games Using Large Vision-Language Models
Mar 27, 2024Online user-generated content games (UGCGs) are increasingly popular among children and adolescents for social interaction and more creative online entertainment. However, they pose a heightened risk of exposure to explicit content, raising growing concerns for the online safety of children and adolescents. Despite these concerns, few studies have addressed the issue of illicit image-based promotions of unsafe UGCGs on social media, which can inadvertently attract young users. This challenge arises from the difficulty of obtaining comprehensive training data for UGCG images and the unique nature of these images, which differ from traditional unsafe content. In this work, we take the first step towards studying the threat of illicit promotions of unsafe UGCGs. We collect a real-world dataset comprising 2,924 images that display diverse sexually explicit and violent content used to promote UGCGs by their game creators. Our in-depth studies reveal a new understanding of this problem and the urgent need for automatically flagging illicit UGCG promotions. We additionally create a cutting-edge system, UGCG-Guard, designed to aid social media platforms in effectively identifying images used for illicit UGCG promotions. This system leverages recently introduced large vision-language models (VLMs) and employs a novel conditional prompting strategy for zero-shot domain adaptation, along with chain-of-thought (CoT) reasoning for contextual identification. UGCG-Guard achieves outstanding results, with an accuracy rate of 94% in detecting these images used for the illicit promotion of such games in real-world scenarios.
An Investigation of Large Language Models for Real-World Hate Speech Detection
Jan 07, 2024Hate speech has emerged as a major problem plaguing our social spaces today. While there have been significant efforts to address this problem, existing methods are still significantly limited in effectively detecting hate speech online. A major limitation of existing methods is that hate speech detection is a highly contextual problem, and these methods cannot fully capture the context of hate speech to make accurate predictions. Recently, large language models (LLMs) have demonstrated state-of-the-art performance in several natural language tasks. LLMs have undergone extensive training using vast amounts of natural language data, enabling them to grasp intricate contextual details. Hence, they could be used as knowledge bases for context-aware hate speech detection. However, a fundamental problem with using LLMs to detect hate speech is that there are no studies on effectively prompting LLMs for context-aware hate speech detection. In this study, we conduct a large-scale study of hate speech detection, employing five established hate speech datasets. We discover that LLMs not only match but often surpass the performance of current benchmark machine learning models in identifying hate speech. By proposing four diverse prompting strategies that optimize the use of LLMs in detecting hate speech. Our study reveals that a meticulously crafted reasoning prompt can effectively capture the context of hate speech by fully utilizing the knowledge base in LLMs, significantly outperforming existing techniques. Furthermore, although LLMs can provide a rich knowledge base for the contextual detection of hate speech, suitable prompting strategies play a crucial role in effectively leveraging this knowledge base for efficient detection.
Moderating New Waves of Online Hate with Chain-of-Thought Reasoning in Large Language Models
Dec 22, 2023
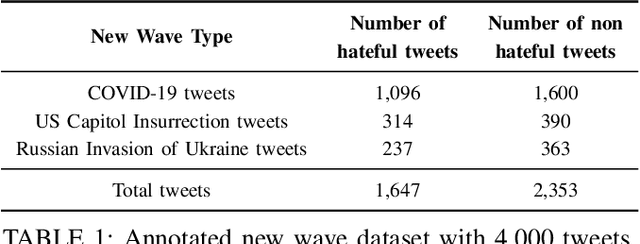
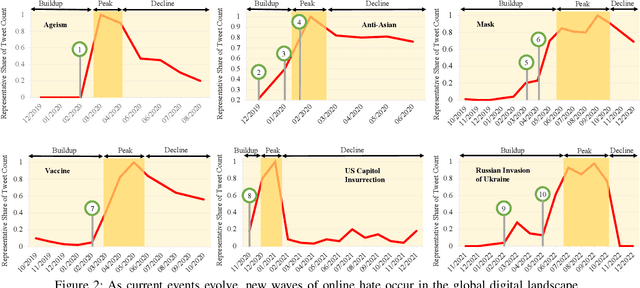

Online hate is an escalating problem that negatively impacts the lives of Internet users, and is also subject to rapid changes due to evolving events, resulting in new waves of online hate that pose a critical threat. Detecting and mitigating these new waves present two key challenges: it demands reasoning-based complex decision-making to determine the presence of hateful content, and the limited availability of training samples hinders updating the detection model. To address this critical issue, we present a novel framework called HATEGUARD for effectively moderating new waves of online hate. HATEGUARD employs a reasoning-based approach that leverages the recently introduced chain-of-thought (CoT) prompting technique, harnessing the capabilities of large language models (LLMs). HATEGUARD further achieves prompt-based zero-shot detection by automatically generating and updating detection prompts with new derogatory terms and targets in new wave samples to effectively address new waves of online hate. To demonstrate the effectiveness of our approach, we compile a new dataset consisting of tweets related to three recently witnessed new waves: the 2022 Russian invasion of Ukraine, the 2021 insurrection of the US Capitol, and the COVID-19 pandemic. Our studies reveal crucial longitudinal patterns in these new waves concerning the evolution of events and the pressing need for techniques to rapidly update existing moderation tools to counteract them. Comparative evaluations against state-of-the-art tools illustrate the superiority of our framework, showcasing a substantial 22.22% to 83.33% improvement in detecting the three new waves of online hate. Our work highlights the severe threat posed by the emergence of new waves of online hate and represents a paradigm shift in addressing this threat practically.
Multi-level Distillation of Semantic Knowledge for Pre-training Multilingual Language Model
Nov 02, 2022



Pre-trained multilingual language models play an important role in cross-lingual natural language understanding tasks. However, existing methods did not focus on learning the semantic structure of representation, and thus could not optimize their performance. In this paper, we propose Multi-level Multilingual Knowledge Distillation (MMKD), a novel method for improving multilingual language models. Specifically, we employ a teacher-student framework to adopt rich semantic representation knowledge in English BERT. We propose token-, word-, sentence-, and structure-level alignment objectives to encourage multiple levels of consistency between source-target pairs and correlation similarity between teacher and student models. We conduct experiments on cross-lingual evaluation benchmarks including XNLI, PAWS-X, and XQuAD. Experimental results show that MMKD outperforms other baseline models of similar size on XNLI and XQuAD and obtains comparable performance on PAWS-X. Especially, MMKD obtains significant performance gains on low-resource languages.
Understanding and Measuring Robustness of Multimodal Learning
Dec 28, 2021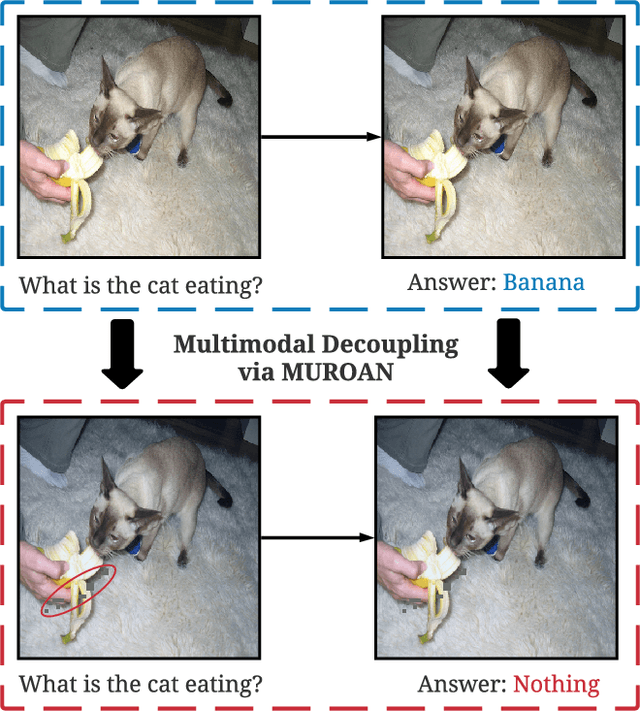

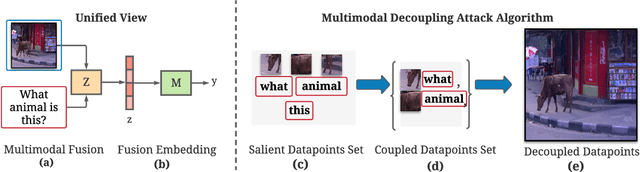

The modern digital world is increasingly becoming multimodal. Although multimodal learning has recently revolutionized the state-of-the-art performance in multimodal tasks, relatively little is known about the robustness of multimodal learning in an adversarial setting. In this paper, we introduce a comprehensive measurement of the adversarial robustness of multimodal learning by focusing on the fusion of input modalities in multimodal models, via a framework called MUROAN (MUltimodal RObustness ANalyzer). We first present a unified view of multimodal models in MUROAN and identify the fusion mechanism of multimodal models as a key vulnerability. We then introduce a new type of multimodal adversarial attacks called decoupling attack in MUROAN that aims to compromise multimodal models by decoupling their fused modalities. We leverage the decoupling attack of MUROAN to measure several state-of-the-art multimodal models and find that the multimodal fusion mechanism in all these models is vulnerable to decoupling attacks. We especially demonstrate that, in the worst case, the decoupling attack of MUROAN achieves an attack success rate of 100% by decoupling just 1.16% of the input space. Finally, we show that traditional adversarial training is insufficient to improve the robustness of multimodal models with respect to decoupling attacks. We hope our findings encourage researchers to pursue improving the robustness of multimodal learning.
CARTL: Cooperative Adversarially-Robust Transfer Learning
Jun 12, 2021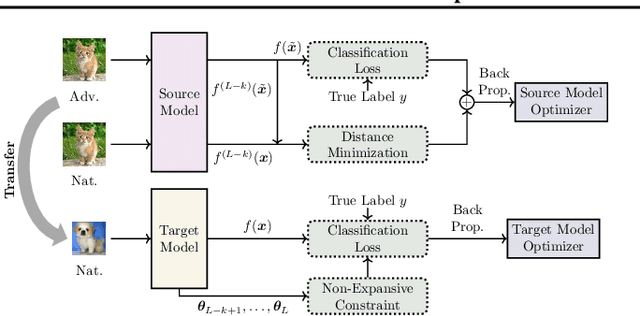
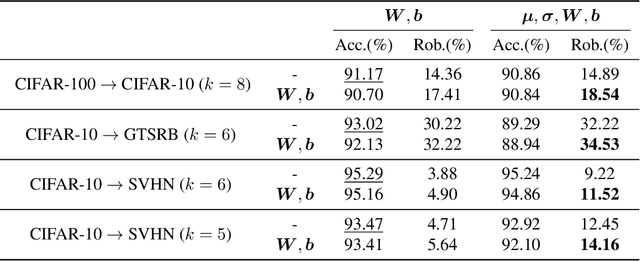
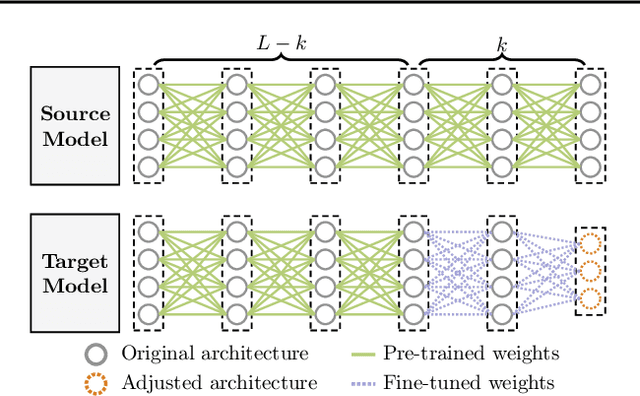
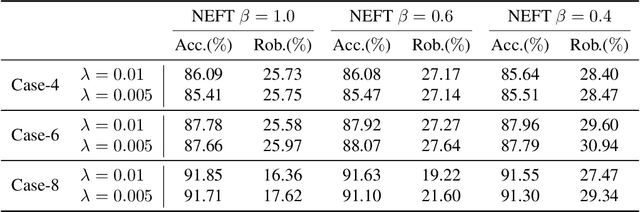
Transfer learning eases the burden of training a well-performed model from scratch, especially when training data is scarce and computation power is limited. In deep learning, a typical strategy for transfer learning is to freeze the early layers of a pre-trained model and fine-tune the rest of its layers on the target domain. Previous work focuses on the accuracy of the transferred model but neglects the transfer of adversarial robustness. In this work, we first show that transfer learning improves the accuracy on the target domain but degrades the inherited robustness of the target model. To address such a problem, we propose a novel cooperative adversarially-robust transfer learning (CARTL) by pre-training the model via feature distance minimization and fine-tuning the pre-trained model with non-expansive fine-tuning for target domain tasks. Empirical results show that CARTL improves the inherited robustness by about 28% at most compared with the baseline with the same degree of accuracy. Furthermore, we study the relationship between the batch normalization (BN) layers and the robustness in the context of transfer learning, and we reveal that freezing BN layers can further boost the robustness transfer.
Multi-level Knowledge Distillation
Dec 01, 2020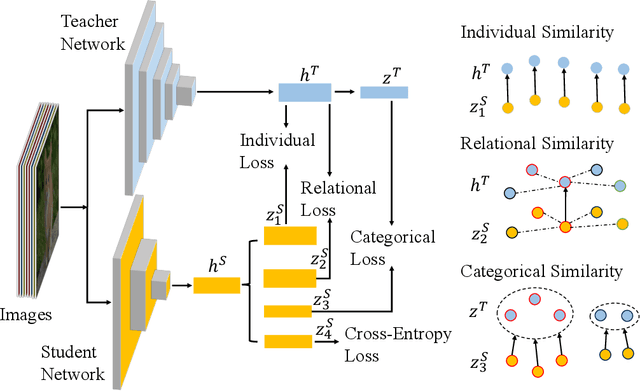
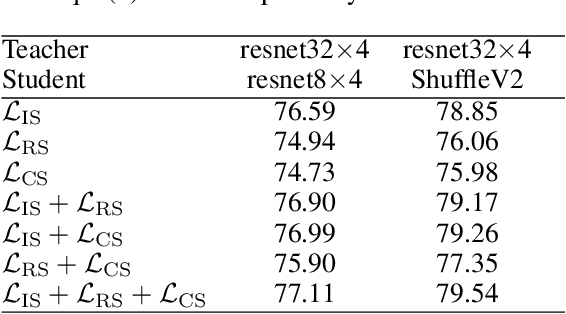
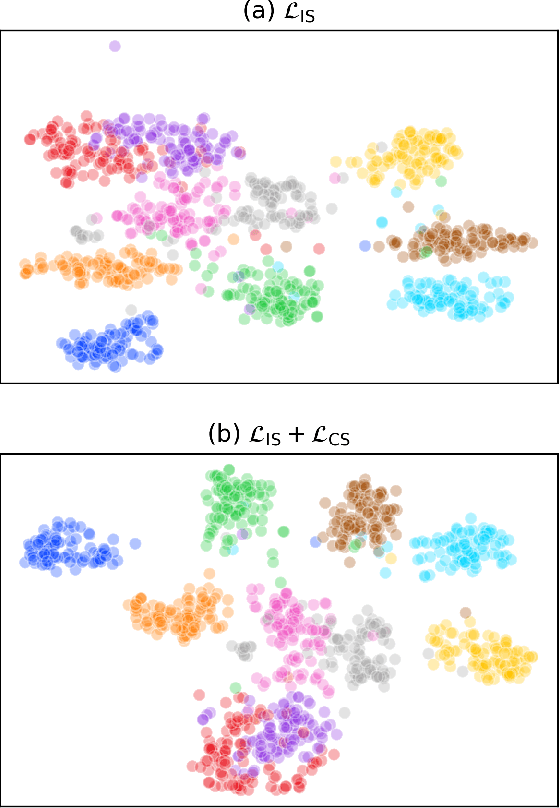
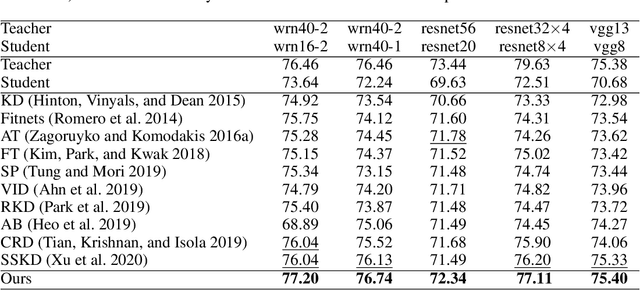
Knowledge distillation has become an important technique for model compression and acceleration. The conventional knowledge distillation approaches aim to transfer knowledge from teacher to student networks by minimizing the KL-divergence between their probabilistic outputs, which only consider the mutual relationship between individual representations of teacher and student networks. Recently, the contrastive loss-based knowledge distillation is proposed to enable a student to learn the instance discriminative knowledge of a teacher by mapping the same image close and different images far away in the representation space. However, all of these methods ignore that the teacher's knowledge is multi-level, e.g., individual, relational and categorical level. These different levels of knowledge cannot be effectively captured by only one kind of supervisory signal. Here, we introduce Multi-level Knowledge Distillation (MLKD) to transfer richer representational knowledge from teacher to student networks. MLKD employs three novel teacher-student similarities: individual similarity, relational similarity, and categorical similarity, to encourage the student network to learn sample-wise, structure-wise and category-wise knowledge in the teacher network. Experiments demonstrate that MLKD outperforms other state-of-the-art methods on both similar-architecture and cross-architecture tasks. We further show that MLKD can improve the transferability of learned representations in the student network.
Explaining Deep Learning-Based Networked Systems
Oct 09, 2019
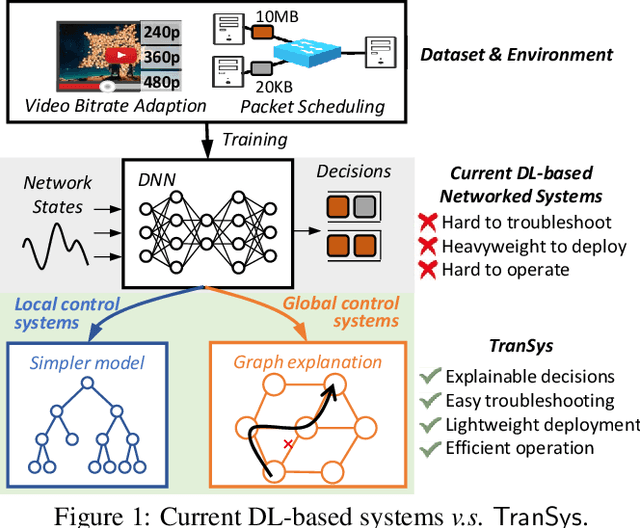
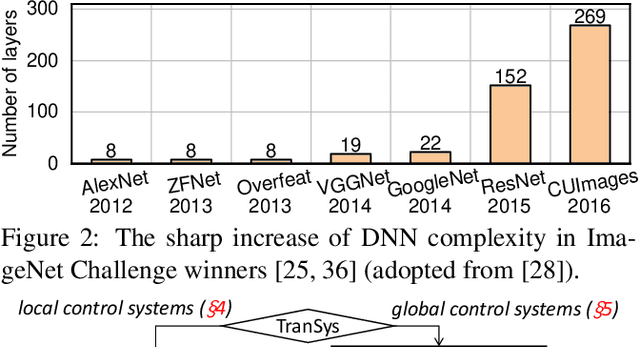

While deep learning (DL)-based networked systems have shown great potential in various applications, a key drawback is that Deep Neural Networks (DNNs) in DL are blackboxes and nontransparent for network operators. The lack of interpretability makes DL-based networked systems challenging to operate and troubleshoot, which further prevents DL-based networked systems from deploying in practice. In this paper, we propose TranSys, a novel framework to explain DL-based networked systems for practical deployment. Transys categorizes current DL-based networked systems and introduces different explanation methods based on decision tree and hypergraph to effectively explain DL-based networked systems. TranSys can explain the DNN policies in the form of decision trees and highlight critical components based on analysis over hypergraph. We evaluate TranSys over several typical DL-based networked systems and demonstrate that Transys can provide human-readable explanations for network operators. We also present three use cases of Transys, which could (i) help network operators troubleshoot DL-based networked systems, (ii) improve the decision latency and resource consumption of DL-based networked systems by ~10x on different metrics, and (iii) provide suggestions on daily operations for network operators when incidences occur.