 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMETS: Coordinated Multi-Destination Video Transmission with In-Network Rate Adaptation
Jan 26, 2026Large-scale video streaming events attract millions of simultaneous viewers, stressing existing delivery infrastructures. Client-driven adaptation reacts slowly to shared congestion, while server-based coordination introduces scalability bottlenecks and single points of failure. We present COMETS, a coordinated multi-destination video transmission framework that leverages information-centric networking principles such as request aggregation and in-network state awareness to enable scalable, fair, and adaptive rate control. COMETS introduces a novel range-interest protocol and distributed in-network decision process that aligns video quality across receiver groups while minimizing redundant transmissions. To achieve this, we develop a lightweight distributed optimization framework that guides per-hop quality adaptation without centralized control. Extensive emulation shows that COMETS consistently improves bandwidth utilization, fairness, and user-perceived quality of experience over DASH, MoQ, and ICN baselines, particularly under high concurrency. The results highlight COMETS as a practical, deployable approach for next-generation scalable video delivery.
* Accepted to appear in IEEE Transactions on Multimedia (2026)
Make a Video Call with LLM: A Measurement Campaign over Five Mainstream Apps
Oct 01, 2025In 2025, Large Language Model (LLM) services have launched a new feature -- AI video chat -- allowing users to interact with AI agents via real-time video communication (RTC), just like chatting with real people. Despite its significance, no systematic study has characterized the performance of existing AI video chat systems. To address this gap, this paper proposes a comprehensive benchmark with carefully designed metrics across four dimensions: quality, latency, internal mechanisms, and system overhead. Using custom testbeds, we further evaluate five mainstream AI video chatbots with this benchmark. This work provides the research community a baseline of real-world performance and identifies unique system bottlenecks. In the meantime, our benchmarking results also open up several research questions for future optimizations of AI video chatbots.
Explaining Deep Learning-Based Networked Systems
Oct 09, 2019
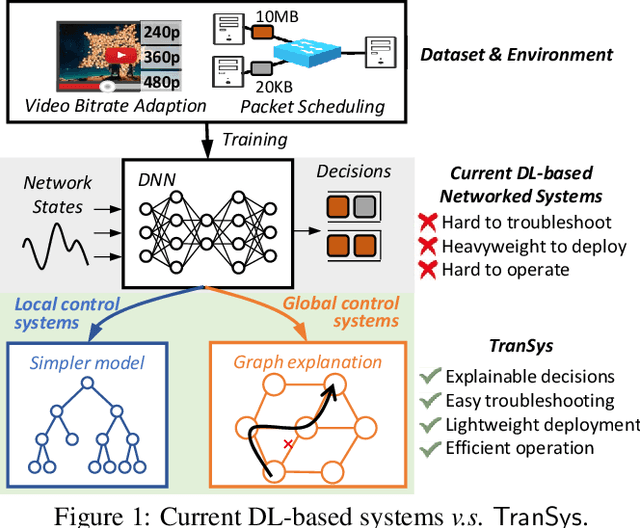

While deep learning (DL)-based networked systems have shown great potential in various applications, a key drawback is that Deep Neural Networks (DNNs) in DL are blackboxes and nontransparent for network operators. The lack of interpretability makes DL-based networked systems challenging to operate and troubleshoot, which further prevents DL-based networked systems from deploying in practice. In this paper, we propose TranSys, a novel framework to explain DL-based networked systems for practical deployment. Transys categorizes current DL-based networked systems and introduces different explanation methods based on decision tree and hypergraph to effectively explain DL-based networked systems. TranSys can explain the DNN policies in the form of decision trees and highlight critical components based on analysis over hypergraph. We evaluate TranSys over several typical DL-based networked systems and demonstrate that Transys can provide human-readable explanations for network operators. We also present three use cases of Transys, which could (i) help network operators troubleshoot DL-based networked systems, (ii) improve the decision latency and resource consumption of DL-based networked systems by ~10x on different metrics, and (iii) provide suggestions on daily operations for network operators when incidences occur.
Learning Scheduling Algorithms for Data Processing Clusters
Oct 12, 2018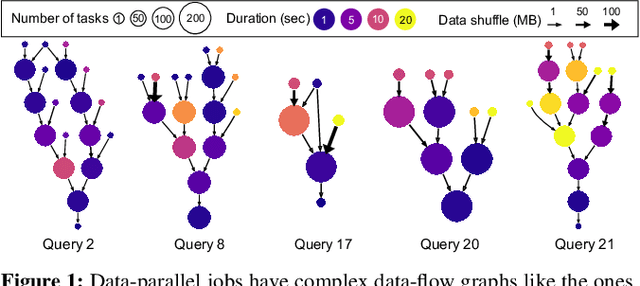

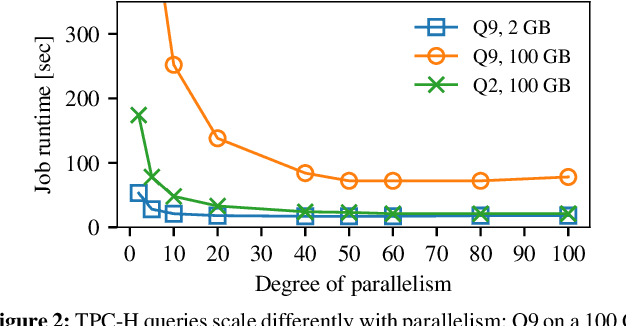

Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs' dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.