 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Scheduling Algorithms for Data Processing Clusters
Paper and Code
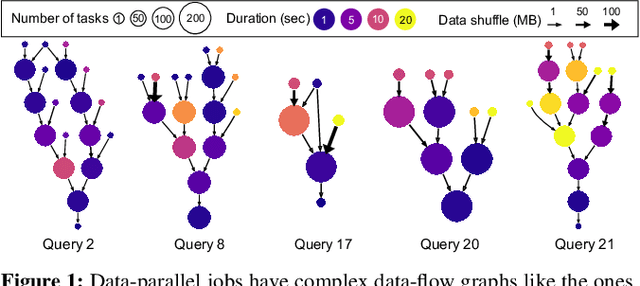

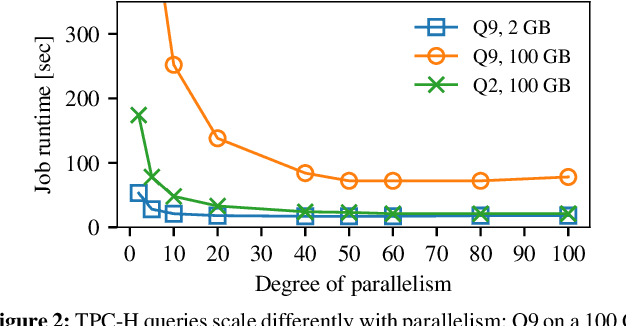

Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs' dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.