 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Concorde: Fast and Accurate CPU Performance Modeling with Compositional Analytical-ML Fusion
Mar 29, 2025Cycle-level simulators such as gem5 are widely used in microarchitecture design, but they are prohibitively slow for large-scale design space explorations. We present Concorde, a new methodology for learning fast and accurate performance models of microarchitectures. Unlike existing simulators and learning approaches that emulate each instruction, Concorde predicts the behavior of a program based on compact performance distributions that capture the impact of different microarchitectural components. It derives these performance distributions using simple analytical models that estimate bounds on performance induced by each microarchitectural component, providing a simple yet rich representation of a program's performance characteristics across a large space of microarchitectural parameters. Experiments show that Concorde is more than five orders of magnitude faster than a reference cycle-level simulator, with about 2% average Cycles-Per-Instruction (CPI) prediction error across a range of SPEC, open-source, and proprietary benchmarks. This enables rapid design-space exploration and performance sensitivity analyses that are currently infeasible, e.g., in about an hour, we conducted a first-of-its-kind fine-grained performance attribution to different microarchitectural components across a diverse set of programs, requiring nearly 150 million CPI evaluations.
m4: A Learned Flow-level Network Simulator
Mar 03, 2025Flow-level simulation is widely used to model large-scale data center networks due to its scalability. Unlike packet-level simulators that model individual packets, flow-level simulators abstract traffic as continuous flows with dynamically assigned transmission rates. While this abstraction enables orders-of-magnitude speedup, it is inaccurate by omitting critical packet-level effects such as queuing, congestion control, and retransmissions. We present m4, an accurate and scalable flow-level simulator that uses machine learning to learn the dynamics of the network of interest. At the core of m4 lies a novel ML architecture that decomposes state transition computations into distinct spatial and temporal components, each represented by a suitable neural network. To efficiently learn the underlying flow-level dynamics, m4 adds dense supervision signals by predicting intermediate network metrics such as remaining flow size and queue length during training. m4 achieves a speedup of up to 104$\times$ over packet-level simulation. Relative to a traditional flow-level simulation, m4 reduces per-flow estimation errors by 45.3% (mean) and 53.0% (p90). For closed-loop applications, m4 accurately predicts network throughput under various congestion control schemes and workloads.
Savaal: Scalable Concept-Driven Question Generation to Enhance Human Learning
Feb 18, 2025
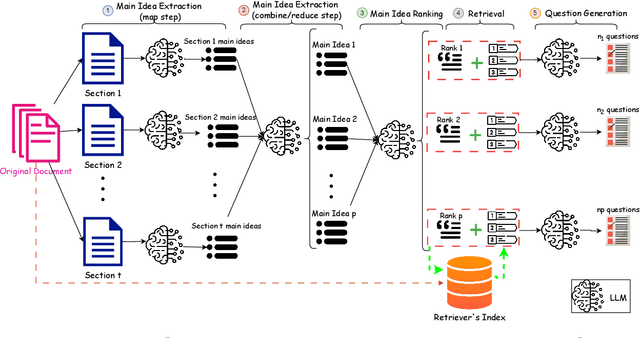


Assessing and enhancing human learning through question-answering is vital, yet automating this process remains challenging. While large language models (LLMs) excel at summarization and query responses, their ability to generate meaningful questions for learners is underexplored. We propose Savaal, a scalable question-generation system with three objectives: (i) scalability, enabling question generation from hundreds of pages of text (ii) depth of understanding, producing questions beyond factual recall to test conceptual reasoning, and (iii) domain-independence, automatically generating questions across diverse knowledge areas. Instead of providing an LLM with large documents as context, Savaal improves results with a three-stage processing pipeline. Our evaluation with 76 human experts on 71 papers and PhD dissertations shows that Savaal generates questions that better test depth of understanding by 6.5X for dissertations and 1.5X for papers compared to a direct-prompting LLM baseline. Notably, as document length increases, Savaal's advantages in higher question quality and lower cost become more pronounced.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024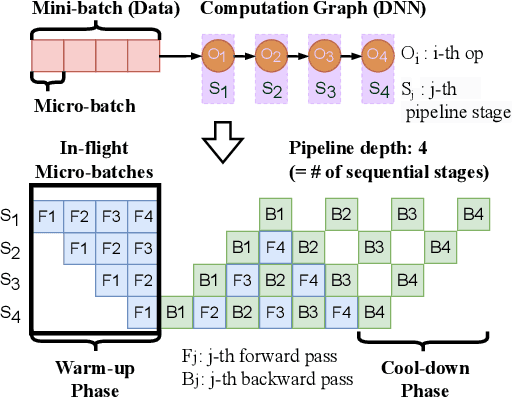

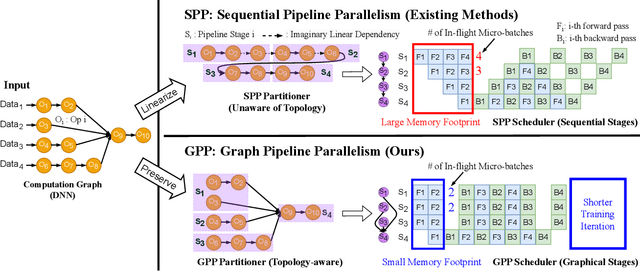
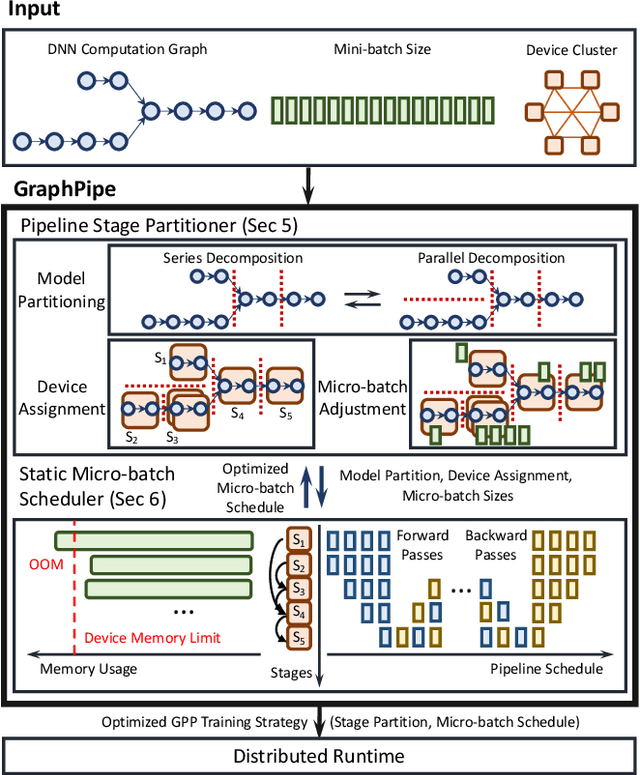
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Reparo: Loss-Resilient Generative Codec for Video Conferencing
May 23, 2023



Loss of packets in video conferencing often results in poor quality and video freezing. Attempting to retransmit the lost packets is usually not practical due to the requirement for real-time playback. Using Forward Error Correction (FEC) to recover the lost packets is challenging since it is difficult to determine the appropriate level of redundancy. In this paper, we propose a framework called Reparo for creating loss-resilient video conferencing using generative deep learning models. Our approach involves generating missing information when a frame or part of a frame is lost. This generation is conditioned on the data received so far, and the model's knowledge of how people look, dress, and interact in the visual world. Our experiments on publicly available video conferencing datasets show that Reparo outperforms state-of-the-art FEC-based video conferencing in terms of both video quality (measured by PSNR) and video freezes.
Locally Constrained Policy Optimization for Online Reinforcement Learning in Non-Stationary Input-Driven Environments
Feb 04, 2023We study online Reinforcement Learning (RL) in non-stationary input-driven environments, where a time-varying exogenous input process affects the environment dynamics. Online RL is challenging in such environments due to catastrophic forgetting (CF). The agent tends to forget prior knowledge as it trains on new experiences. Prior approaches to mitigate this issue assume task labels (which are often not available in practice) or use off-policy methods that can suffer from instability and poor performance. We present Locally Constrained Policy Optimization (LCPO), an on-policy RL approach that combats CF by anchoring policy outputs on old experiences while optimizing the return on current experiences. To perform this anchoring, LCPO locally constrains policy optimization using samples from experiences that lie outside of the current input distribution. We evaluate LCPO in two gym and computer systems environments with a variety of synthetic and real input traces, and find that it outperforms state-of-the-art on-policy and off-policy RL methods in the online setting, while achieving results on-par with an offline agent pre-trained on the whole input trace.
Counterfactual Identifiability of Bijective Causal Models
Feb 04, 2023We study counterfactual identifiability in causal models with bijective generation mechanisms (BGM), a class that generalizes several widely-used causal models in the literature. We establish their counterfactual identifiability for three common causal structures with unobserved confounding, and propose a practical learning method that casts learning a BGM as structured generative modeling. Learned BGMs enable efficient counterfactual estimation and can be obtained using a variety of deep conditional generative models. We evaluate our techniques in a visual task and demonstrate its application in a real-world video streaming simulation task.
FactorJoin: A New Cardinality Estimation Framework for Join Queries
Dec 11, 2022
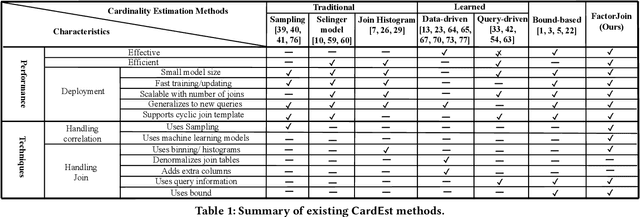
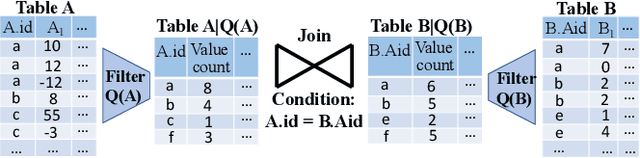
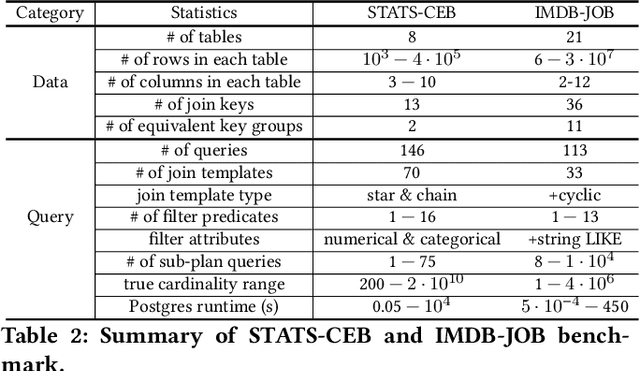
Cardinality estimation is one of the most fundamental and challenging problems in query optimization. Neither classical nor learning-based methods yield satisfactory performance when estimating the cardinality of the join queries. They either rely on simplified assumptions leading to ineffective cardinality estimates or build large models to understand the data distributions, leading to long planning times and a lack of generalizability across queries. In this paper, we propose a new framework FactorJoin for estimating join queries. FactorJoin combines the idea behind the classical join-histogram method to efficiently handle joins with the learning-based methods to accurately capture attribute correlation. Specifically, FactorJoin scans every table in a DB and builds single-table conditional distributions during an offline preparation phase. When a join query comes, FactorJoin translates it into a factor graph model over the learned distributions to effectively and efficiently estimate its cardinality. Unlike existing learning-based methods, FactorJoin does not need to de-normalize joins upfront or require executed query workloads to train the model. Since it only relies on single-table statistics, FactorJoin has small space overhead and is extremely easy to train and maintain. In our evaluation, FactorJoin can produce more effective estimates than the previous state-of-the-art learning-based methods, with 40x less estimation latency, 100x smaller model size, and 100x faster training speed at comparable or better accuracy. In addition, FactorJoin can estimate 10,000 sub-plan queries within one second to optimize the query plan, which is very close to the traditional cardinality estimators in commercial DBMS.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022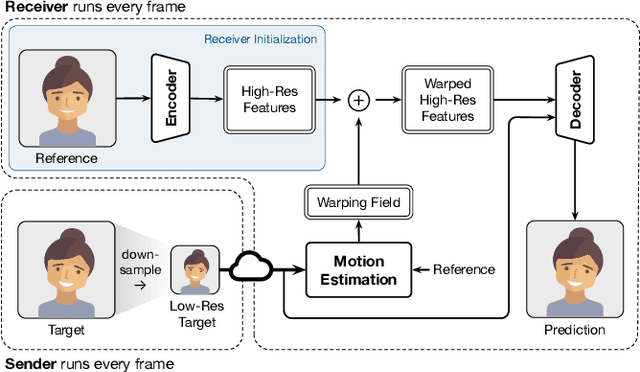
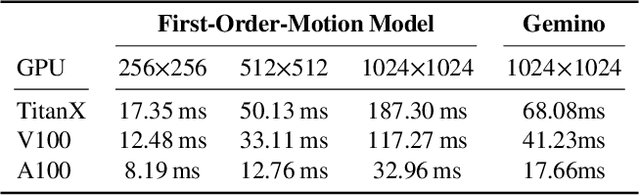


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.