 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlinthawk: A Two-Tiered Architecture for High-Throughput LLM Inference
Jan 20, 2025



Large Language Models (LLM) have revolutionized natural language processing, but their inference demands substantial resources, while under-utilizing high-end accelerators like GPUs. A major bottleneck arises from the attention mechanism, which requires storing large key-value caches, limiting the maximum achievable throughput way below the available computing resources. Current approaches attempt to mitigate this issue through memory-efficient attention and paging mechanisms, but remained constrained by the assumption that all operations must be performed on high-end accelerators. In this work, we propose Glinthawk, a two-tiered architecture that decouples the attention mechanism from the rest of the Transformer model. This approach allows the memory requirements for attention to scale independently, enabling larger batch sizes and more efficient use of the high-end accelerators. We prototype Glinthawk with NVIDIA T4 GPUs as one tier and standard CPU VMs as the other. Compared to a traditional single-tier setup, it improves throughput by $5.9\times$ and reduces cost of generation by $2.8\times$. For longer sequence lengths, it achieves $16.3\times$ throughput improvement at $2.4\times$ less cost. Our evaluation shows that this architecture can tolerate moderate network latency with minimal performance degradation, making it highly effective for latency-tolerant, throughput-oriented applications such as batch processing. We shared our prototype publicly at \url{https://github.com/microsoft/glinthawk}.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022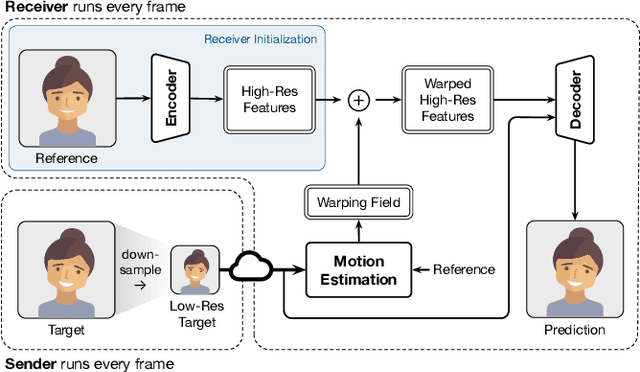
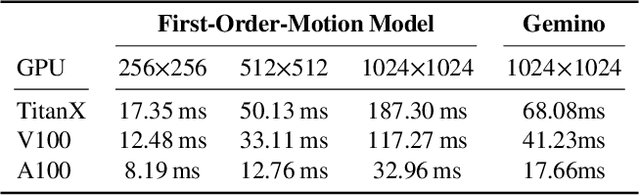


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
Parallelization Techniques for Verifying Neural Networks
Apr 26, 2020
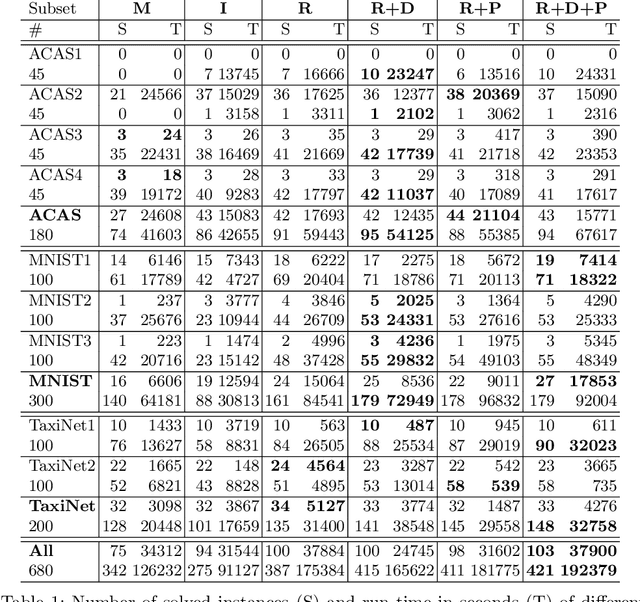


Inspired by recent successes with parallel optimization techniques for solving Boolean satisfiability, we investigate a set of strategies and heuristics that aim to leverage parallel computing to improve the scalability of neural network verification. We introduce an algorithm based on partitioning the verification problem in an iterative manner and explore two partitioning strategies, that work by partitioning the input space or by case splitting on the phases of the neuron activations, respectively. We also introduce a highly parallelizable pre-processing algorithm that uses the neuron activation phases to simplify the neural network verification problems. An extensive experimental evaluation shows the benefit of these techniques on both existing benchmarks and new benchmarks from the aviation domain. A preliminary experiment with ultra-scaling our algorithm using a large distributed cloud-based platform also shows promising results.