 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Based Abductive and Contrastive Explanations for Behaviors of Vision Models
May 07, 2026*Concept-based explanations* offer a promising approach for explaining the predictions of deep neural networks in terms of high-level, human-understandable concepts. However, existing methods either do not establish a causal connection between the concepts and model predictions or are limited in expressivity and only able to infer causal explanations involving single concepts. At the same time, the parallel line of work on *formal abductive and contrastive explanations* computes the minimal set of input features causally relevant for model outcomes but only considers low-level features such as pixels. Merging these two threads, in this work, we propose the notion of *concept-based abductive and contrastive explanations* that capture the minimal sets of high-level concepts causally relevant for model outcomes. We then present a family of algorithms that enumerate all minimal explanations while using *concept erasure* procedures to establish causal relationships. By appropriately aggregating such explanations, we are not only able to understand model predictions on individual images but also on collections of images where the model exhibits a user-specified, common *behavior*. We evaluate our approach on multiple models, datasets, and behaviors, and demonstrate its effectiveness in computing helpful, user-friendly explanations.
Scenario-based Compositional Verification of Autonomous Systems with Neural Perception
Apr 29, 2025Recent advances in deep learning have enabled the development of autonomous systems that use deep neural networks for perception. Formal verification of these systems is challenging due to the size and complexity of the perception DNNs as well as hard-to-quantify, changing environment conditions. To address these challenges, we propose a probabilistic verification framework for autonomous systems based on the following key concepts: (1) Scenario-based Modeling: We decompose the task (e.g., car navigation) into a composition of scenarios, each representing a different environment condition. (2) Probabilistic Abstractions: For each scenario, we build a compact abstraction of perception based on the DNN's performance on an offline dataset that represents the scenario's environment condition. (3) Symbolic Reasoning and Acceleration: The abstractions enable efficient compositional verification of the autonomous system via symbolic reasoning and a novel acceleration proof rule that bounds the error probability of the system under arbitrary variations of environment conditions. We illustrate our approach on two case studies: an experimental autonomous system that guides airplanes on taxiways using high-dimensional perception DNNs and a simulation model of an F1Tenth autonomous car using LiDAR observations.
Evaluating Deep Neural Networks in Deployment (A Comparative and Replicability Study)
Jul 11, 2024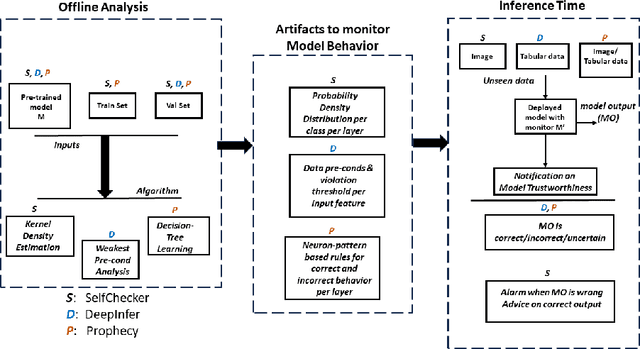
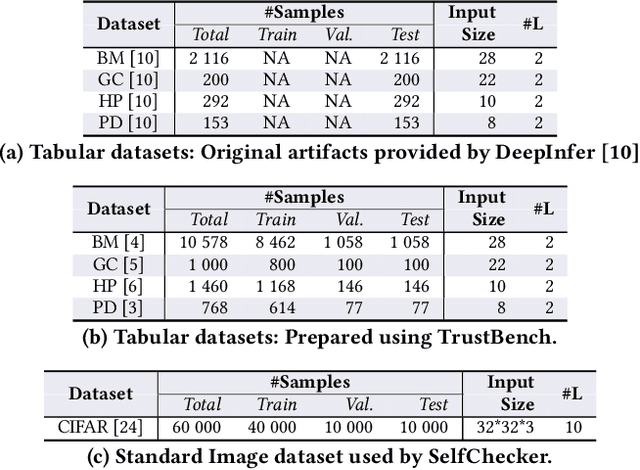
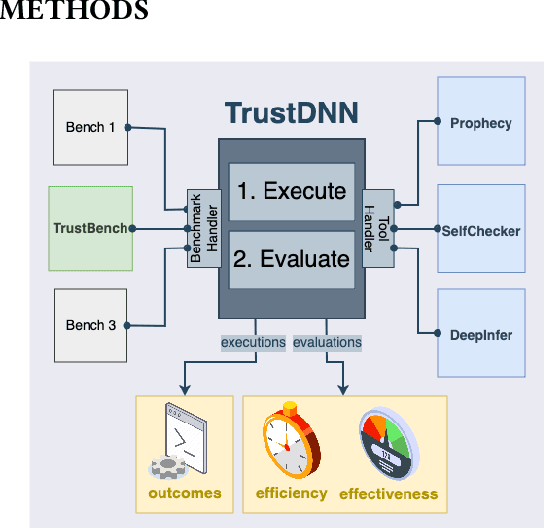
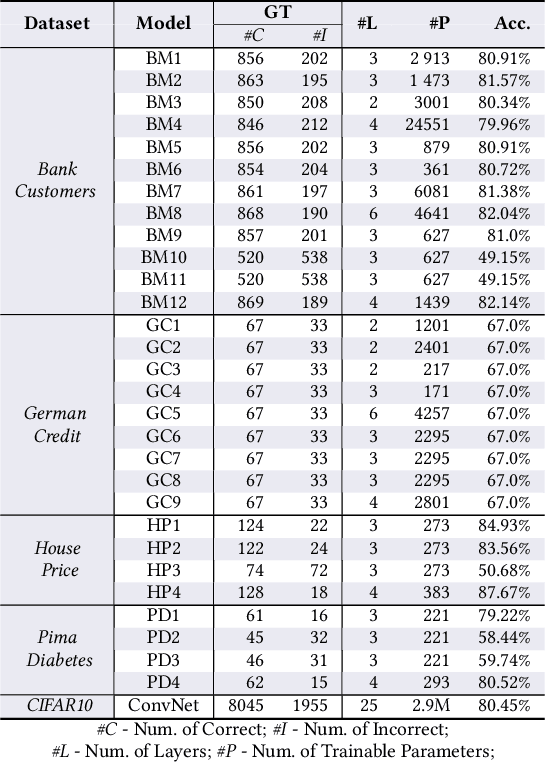
As deep neural networks (DNNs) are increasingly used in safety-critical applications, there is a growing concern for their reliability. Even highly trained, high-performant networks are not 100% accurate. However, it is very difficult to predict their behavior during deployment without ground truth. In this paper, we provide a comparative and replicability study on recent approaches that have been proposed to evaluate the reliability of DNNs in deployment. We find that it is hard to run and reproduce the results for these approaches on their replication packages and even more difficult to run them on artifacts other than their own. Further, it is difficult to compare the effectiveness of the approaches, due to the lack of clearly defined evaluation metrics. Our results indicate that more effort is needed in our research community to obtain sound techniques for evaluating the reliability of neural networks in safety-critical domains. To this end, we contribute an evaluation framework that incorporates the considered approaches and enables evaluation on common benchmarks, using common metrics.
Concept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024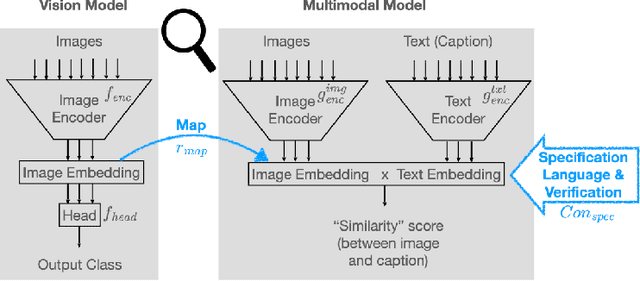
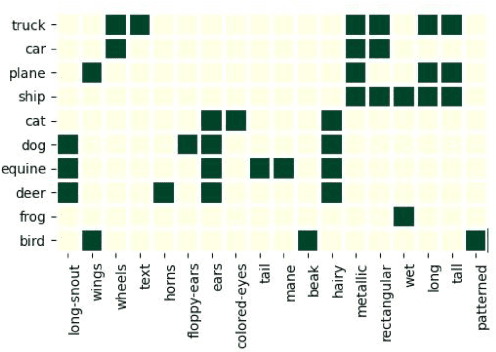
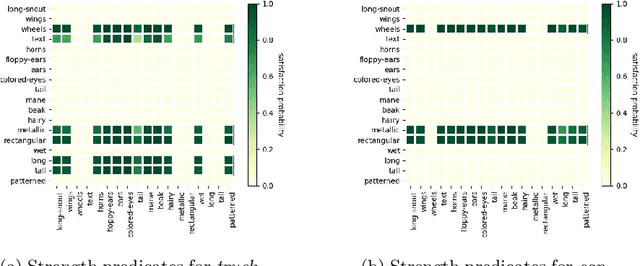
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Assumption Generation for the Verification of Learning-Enabled Autonomous Systems
May 27, 2023Providing safety guarantees for autonomous systems is difficult as these systems operate in complex environments that require the use of learning-enabled components, such as deep neural networks (DNNs) for visual perception. DNNs are hard to analyze due to their size (they can have thousands or millions of parameters), lack of formal specifications (DNNs are typically learnt from labeled data, in the absence of any formal requirements), and sensitivity to small changes in the environment. We present an assume-guarantee style compositional approach for the formal verification of system-level safety properties of such autonomous systems. Our insight is that we can analyze the system in the absence of the DNN perception components by automatically synthesizing assumptions on the DNN behaviour that guarantee the satisfaction of the required safety properties. The synthesized assumptions are the weakest in the sense that they characterize the output sequences of all the possible DNNs that, plugged into the autonomous system, guarantee the required safety properties. The assumptions can be leveraged as run-time monitors over a deployed DNN to guarantee the safety of the overall system; they can also be mined to extract local specifications for use during training and testing of DNNs. We illustrate our approach on a case study taken from the autonomous airplanes domain that uses a complex DNN for perception.
Closed-loop Analysis of Vision-based Autonomous Systems: A Case Study
Feb 06, 2023Deep neural networks (DNNs) are increasingly used in safety-critical autonomous systems as perception components processing high-dimensional image data. Formal analysis of these systems is particularly challenging due to the complexity of the perception DNNs, the sensors (cameras), and the environment conditions. We present a case study applying formal probabilistic analysis techniques to an experimental autonomous system that guides airplanes on taxiways using a perception DNN. We address the above challenges by replacing the camera and the network with a compact probabilistic abstraction built from the confusion matrices computed for the DNN on a representative image data set. We also show how to leverage local, DNN-specific analyses as run-time guards to increase the safety of the overall system. Our findings are applicable to other autonomous systems that use complex DNNs for perception.
An Overview of Structural Coverage Metrics for Testing Neural Networks
Aug 05, 2022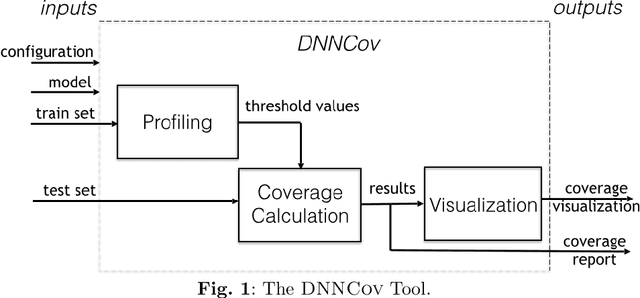
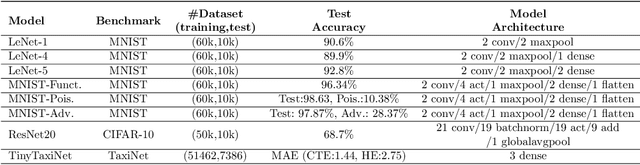
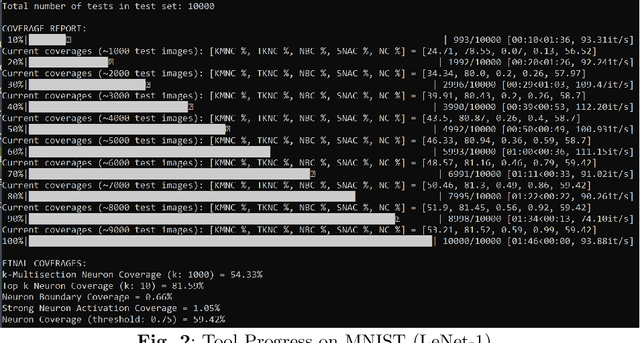
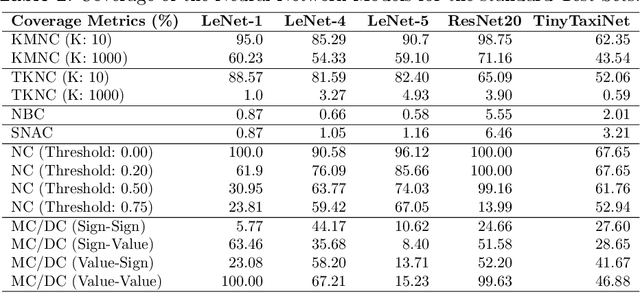
Deep neural network (DNN) models, including those used in safety-critical domains, need to be thoroughly tested to ensure that they can reliably perform well in different scenarios. In this article, we provide an overview of structural coverage metrics for testing DNN models, including neuron coverage (NC), k-multisection neuron coverage (kMNC), top-k neuron coverage (TKNC), neuron boundary coverage (NBC), strong neuron activation coverage (SNAC) and modified condition/decision coverage (MC/DC). We evaluate the metrics on realistic DNN models used for perception tasks (including LeNet-1, LeNet-4, LeNet-5, and ResNet20) as well as on networks used in autonomy (TaxiNet). We also provide a tool, DNNCov, which can measure the testing coverage for all these metrics. DNNCov outputs an informative coverage report to enable researchers and practitioners to assess the adequacy of DNN testing, compare different coverage measures, and to more conveniently inspect the model's internals during testing.
VPN: Verification of Poisoning in Neural Networks
May 08, 2022
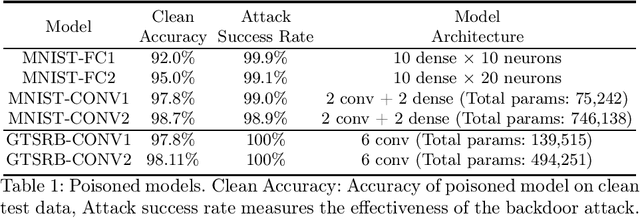
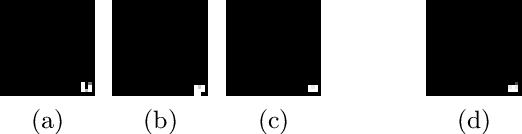
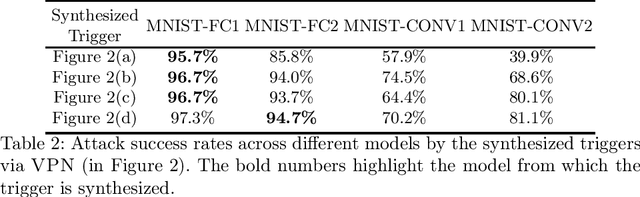
Neural networks are successfully used in a variety of applications, many of them having safety and security concerns. As a result researchers have proposed formal verification techniques for verifying neural network properties. While previous efforts have mainly focused on checking local robustness in neural networks, we instead study another neural network security issue, namely data poisoning. In this case an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger in an input causes the trained model to misclassify to some target class. We show how to formulate the check for data poisoning as a property that can be checked with off-the-shelf verification tools, such as Marabou and nneum, where counterexamples of failed checks constitute the triggers. We further show that the discovered triggers are `transferable' from a small model to a larger, better-trained model, allowing us to analyze state-of-the art performant models trained for image classification tasks.
AntidoteRT: Run-time Detection and Correction of Poison Attacks on Neural Networks
Jan 31, 2022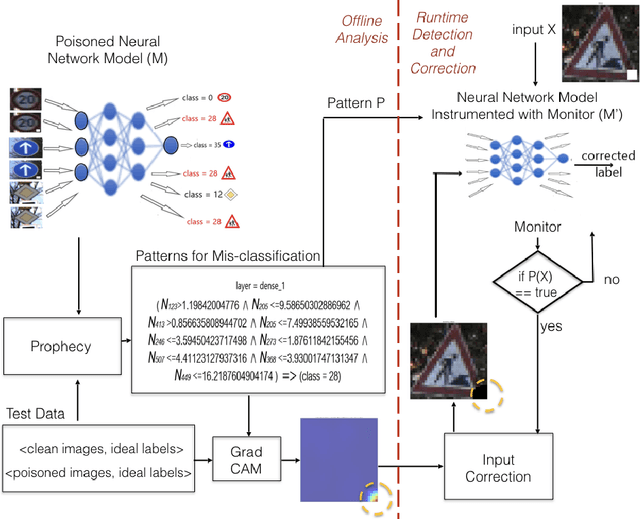



We study backdoor poisoning attacks against image classification networks, whereby an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger causes the classifier to predict some target class. %There are several techniques proposed in the literature that aim to detect the attack but only a few also propose to defend against it, and they typically involve retraining the network which is not always possible in practice. We propose lightweight automated detection and correction techniques against poisoning attacks, which are based on neuron patterns mined from the network using a small set of clean and poisoned test samples with known labels. The patterns built based on the mis-classified samples are used for run-time detection of new poisoned inputs. For correction, we propose an input correction technique that uses a differential analysis to identify the trigger in the detected poisoned images, which is then reset to a neutral color. Our detection and correction are performed at run-time and input level, which is in contrast to most existing work that is focused on offline model-level defenses. We demonstrate that our technique outperforms existing defenses such as NeuralCleanse and STRIP on popular benchmarks such as MNIST, CIFAR-10, and GTSRB against the popular BadNets attack and the more complex DFST attack.
QuantifyML: How Good is my Machine Learning Model?
Oct 25, 2021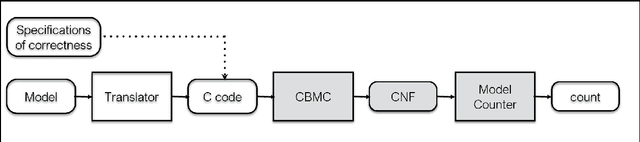
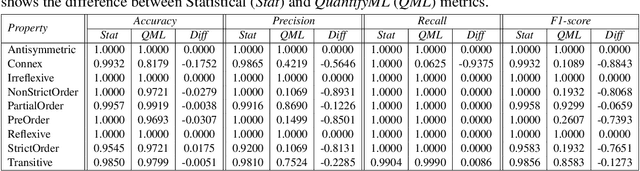
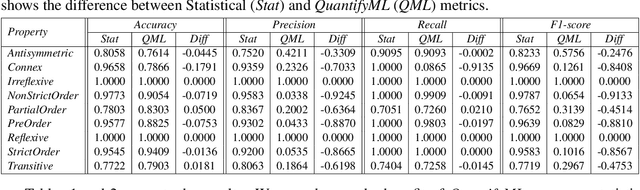
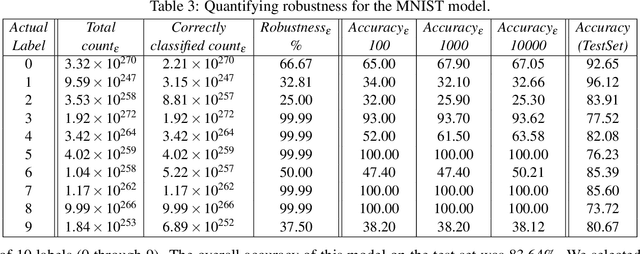
The efficacy of machine learning models is typically determined by computing their accuracy on test data sets. However, this may often be misleading, since the test data may not be representative of the problem that is being studied. With QuantifyML we aim to precisely quantify the extent to which machine learning models have learned and generalized from the given data. Given a trained model, QuantifyML translates it into a C program and feeds it to the CBMC model checker to produce a formula in Conjunctive Normal Form (CNF). The formula is analyzed with off-the-shelf model counters to obtain precise counts with respect to different model behavior. QuantifyML enables i) evaluating learnability by comparing the counts for the outputs to ground truth, expressed as logical predicates, ii) comparing the performance of models built with different machine learning algorithms (decision-trees vs. neural networks), and iii) quantifying the safety and robustness of models.
* In Proceedings FMAS 2021, arXiv:2110.11527