 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPN: Verification of Poisoning in Neural Networks
Paper and Code

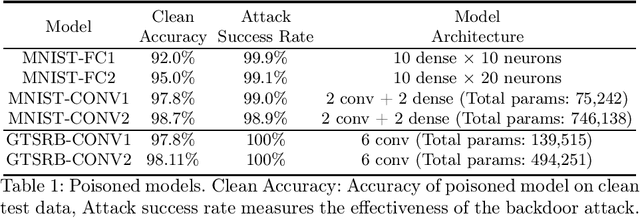
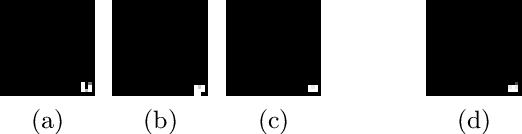
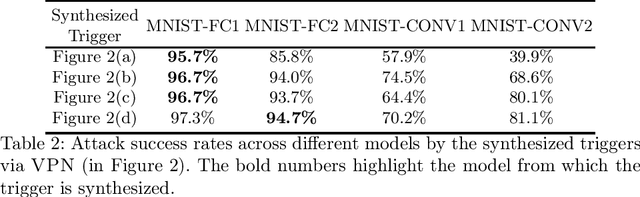
Neural networks are successfully used in a variety of applications, many of them having safety and security concerns. As a result researchers have proposed formal verification techniques for verifying neural network properties. While previous efforts have mainly focused on checking local robustness in neural networks, we instead study another neural network security issue, namely data poisoning. In this case an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger in an input causes the trained model to misclassify to some target class. We show how to formulate the check for data poisoning as a property that can be checked with off-the-shelf verification tools, such as Marabou and nneum, where counterexamples of failed checks constitute the triggers. We further show that the discovered triggers are `transferable' from a small model to a larger, better-trained model, allowing us to analyze state-of-the art performant models trained for image classification tasks.