 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Selecting Few-Shot Examples for LLM-based Code Vulnerability Detection
Oct 31, 2025Large language models (LLMs) have demonstrated impressive capabilities for many coding tasks, including summarization, translation, completion, and code generation. However, detecting code vulnerabilities remains a challenging task for LLMs. An effective way to improve LLM performance is in-context learning (ICL) - providing few-shot examples similar to the query, along with correct answers, can improve an LLM's ability to generate correct solutions. However, choosing the few-shot examples appropriately is crucial to improving model performance. In this paper, we explore two criteria for choosing few-shot examples for ICL used in the code vulnerability detection task. The first criterion considers if the LLM (consistently) makes a mistake or not on a sample with the intuition that LLM performance on a sample is informative about its usefulness as a few-shot example. The other criterion considers similarity of the examples with the program under query and chooses few-shot examples based on the $k$-nearest neighbors to the given sample. We perform evaluations to determine the benefits of these criteria individually as well as under various combinations, using open-source models on multiple datasets.
Worst-Case Symbolic Constraints Analysis and Generalisation with Large Language Models
Jun 09, 2025Large language models (LLMs) have been successfully applied to a variety of coding tasks, including code generation, completion, and repair. However, more complex symbolic reasoning tasks remain largely unexplored by LLMs. This paper investigates the capacity of LLMs to reason about worst-case executions in programs through symbolic constraints analysis, aiming to connect LLMs and symbolic reasoning approaches. Specifically, we define and address the problem of worst-case symbolic constraints analysis as a measure to assess the comprehension of LLMs. We evaluate the performance of existing LLMs on this novel task and further improve their capabilities through symbolic reasoning-guided fine-tuning, grounded in SMT (Satisfiability Modulo Theories) constraint solving and supported by a specially designed dataset of symbolic constraints. Experimental results show that our solver-aligned model, WARP-1.0-3B, consistently surpasses size-matched and even much larger baselines, demonstrating that a 3B LLM can recover the very constraints that pin down an algorithm's worst-case behaviour through reinforcement learning methods. These findings suggest that LLMs are capable of engaging in deeper symbolic reasoning, supporting a closer integration between neural network-based learning and formal methods for rigorous program analysis.
Scenario-based Compositional Verification of Autonomous Systems with Neural Perception
Apr 29, 2025Recent advances in deep learning have enabled the development of autonomous systems that use deep neural networks for perception. Formal verification of these systems is challenging due to the size and complexity of the perception DNNs as well as hard-to-quantify, changing environment conditions. To address these challenges, we propose a probabilistic verification framework for autonomous systems based on the following key concepts: (1) Scenario-based Modeling: We decompose the task (e.g., car navigation) into a composition of scenarios, each representing a different environment condition. (2) Probabilistic Abstractions: For each scenario, we build a compact abstraction of perception based on the DNN's performance on an offline dataset that represents the scenario's environment condition. (3) Symbolic Reasoning and Acceleration: The abstractions enable efficient compositional verification of the autonomous system via symbolic reasoning and a novel acceleration proof rule that bounds the error probability of the system under arbitrary variations of environment conditions. We illustrate our approach on two case studies: an experimental autonomous system that guides airplanes on taxiways using high-dimensional perception DNNs and a simulation model of an F1Tenth autonomous car using LiDAR observations.
Mechanistically Interpreting a Transformer-based 2-SAT Solver: An Axiomatic Approach
Jul 18, 2024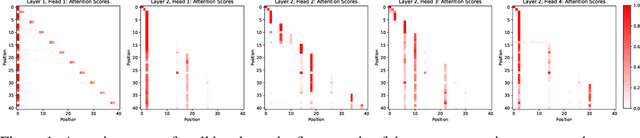

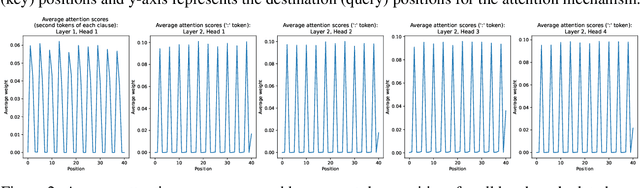

Mechanistic interpretability aims to reverse engineer the computation performed by a neural network in terms of its internal components. Although there is a growing body of research on mechanistic interpretation of neural networks, the notion of a mechanistic interpretation itself is often ad-hoc. Inspired by the notion of abstract interpretation from the program analysis literature that aims to develop approximate semantics for programs, we give a set of axioms that formally characterize a mechanistic interpretation as a description that approximately captures the semantics of the neural network under analysis in a compositional manner. We use these axioms to guide the mechanistic interpretability analysis of a Transformer-based model trained to solve the well-known 2-SAT problem. We are able to reverse engineer the algorithm learned by the model -- the model first parses the input formulas and then evaluates their satisfiability via enumeration of different possible valuations of the Boolean input variables. We also present evidence to support that the mechanistic interpretation of the analyzed model indeed satisfies the stated axioms.
Evaluating Deep Neural Networks in Deployment (A Comparative and Replicability Study)
Jul 11, 2024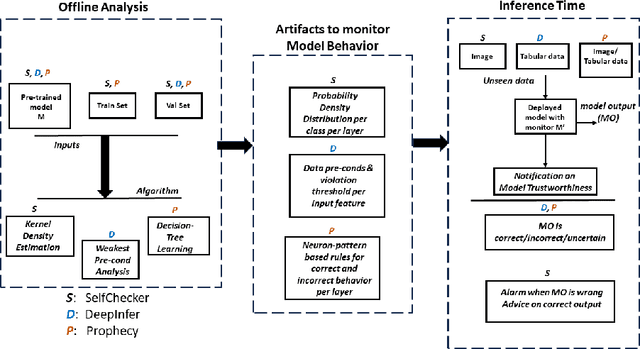
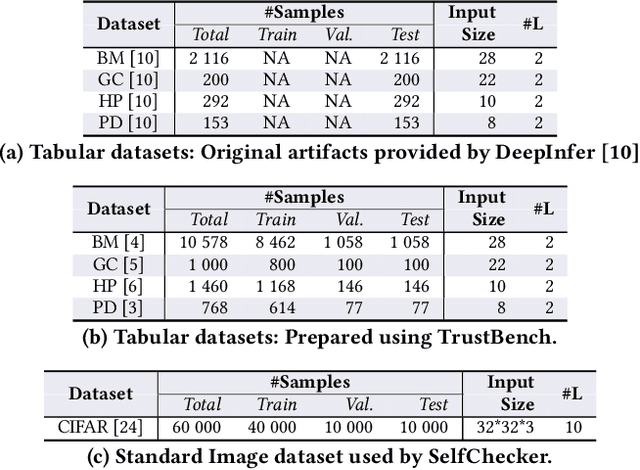
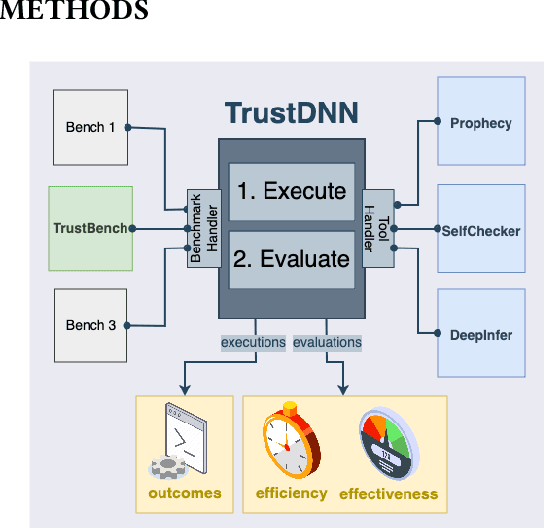
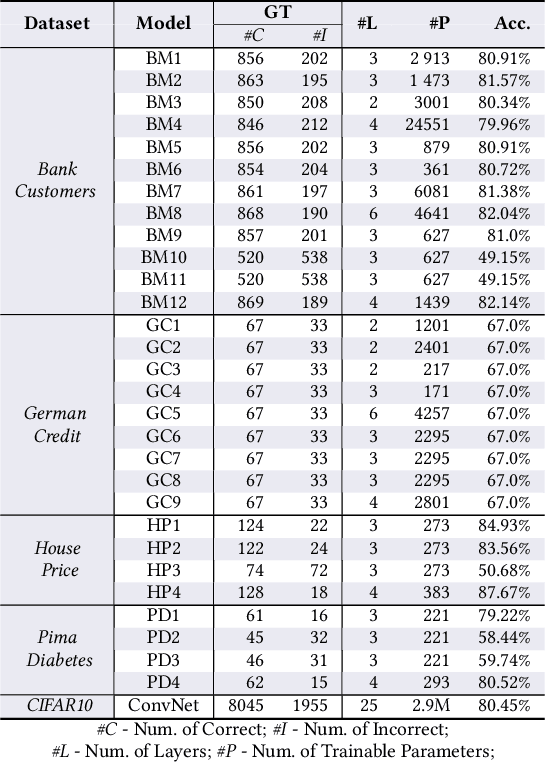
As deep neural networks (DNNs) are increasingly used in safety-critical applications, there is a growing concern for their reliability. Even highly trained, high-performant networks are not 100% accurate. However, it is very difficult to predict their behavior during deployment without ground truth. In this paper, we provide a comparative and replicability study on recent approaches that have been proposed to evaluate the reliability of DNNs in deployment. We find that it is hard to run and reproduce the results for these approaches on their replication packages and even more difficult to run them on artifacts other than their own. Further, it is difficult to compare the effectiveness of the approaches, due to the lack of clearly defined evaluation metrics. Our results indicate that more effort is needed in our research community to obtain sound techniques for evaluating the reliability of neural networks in safety-critical domains. To this end, we contribute an evaluation framework that incorporates the considered approaches and enables evaluation on common benchmarks, using common metrics.
Closed-loop Analysis of Vision-based Autonomous Systems: A Case Study
Feb 06, 2023Deep neural networks (DNNs) are increasingly used in safety-critical autonomous systems as perception components processing high-dimensional image data. Formal analysis of these systems is particularly challenging due to the complexity of the perception DNNs, the sensors (cameras), and the environment conditions. We present a case study applying formal probabilistic analysis techniques to an experimental autonomous system that guides airplanes on taxiways using a perception DNN. We address the above challenges by replacing the camera and the network with a compact probabilistic abstraction built from the confusion matrices computed for the DNN on a representative image data set. We also show how to leverage local, DNN-specific analyses as run-time guards to increase the safety of the overall system. Our findings are applicable to other autonomous systems that use complex DNNs for perception.
An Overview of Structural Coverage Metrics for Testing Neural Networks
Aug 05, 2022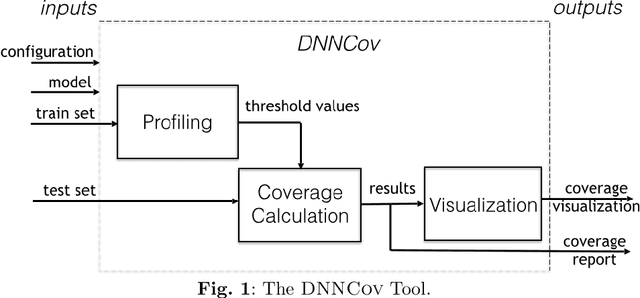
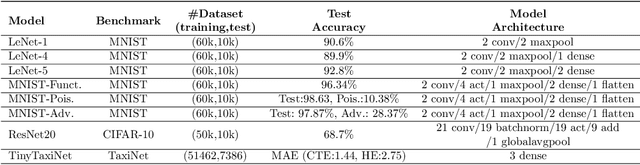
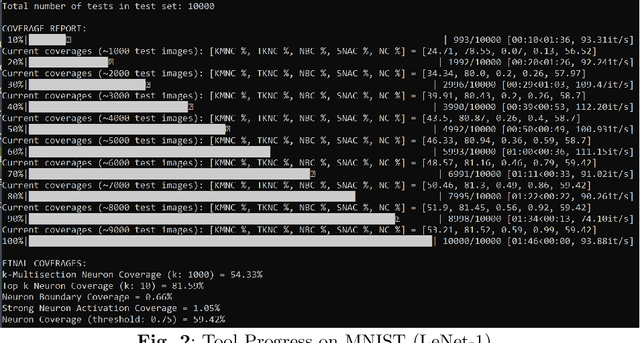
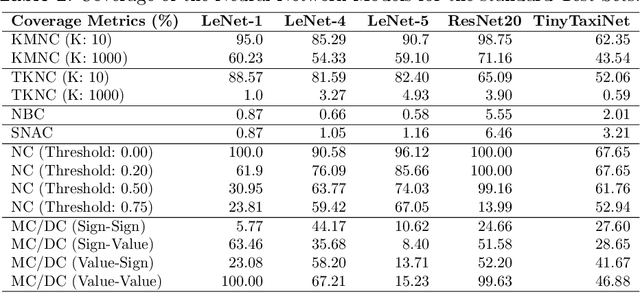
Deep neural network (DNN) models, including those used in safety-critical domains, need to be thoroughly tested to ensure that they can reliably perform well in different scenarios. In this article, we provide an overview of structural coverage metrics for testing DNN models, including neuron coverage (NC), k-multisection neuron coverage (kMNC), top-k neuron coverage (TKNC), neuron boundary coverage (NBC), strong neuron activation coverage (SNAC) and modified condition/decision coverage (MC/DC). We evaluate the metrics on realistic DNN models used for perception tasks (including LeNet-1, LeNet-4, LeNet-5, and ResNet20) as well as on networks used in autonomy (TaxiNet). We also provide a tool, DNNCov, which can measure the testing coverage for all these metrics. DNNCov outputs an informative coverage report to enable researchers and practitioners to assess the adequacy of DNN testing, compare different coverage measures, and to more conveniently inspect the model's internals during testing.
AntidoteRT: Run-time Detection and Correction of Poison Attacks on Neural Networks
Jan 31, 2022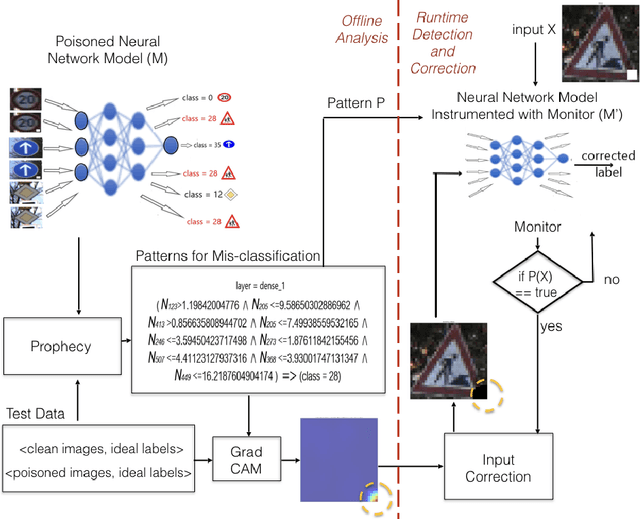



We study backdoor poisoning attacks against image classification networks, whereby an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger causes the classifier to predict some target class. %There are several techniques proposed in the literature that aim to detect the attack but only a few also propose to defend against it, and they typically involve retraining the network which is not always possible in practice. We propose lightweight automated detection and correction techniques against poisoning attacks, which are based on neuron patterns mined from the network using a small set of clean and poisoned test samples with known labels. The patterns built based on the mis-classified samples are used for run-time detection of new poisoned inputs. For correction, we propose an input correction technique that uses a differential analysis to identify the trigger in the detected poisoned images, which is then reset to a neutral color. Our detection and correction are performed at run-time and input level, which is in contrast to most existing work that is focused on offline model-level defenses. We demonstrate that our technique outperforms existing defenses such as NeuralCleanse and STRIP on popular benchmarks such as MNIST, CIFAR-10, and GTSRB against the popular BadNets attack and the more complex DFST attack.
DeepCert: Verification of Contextually Relevant Robustness for Neural Network Image Classifiers
Mar 02, 2021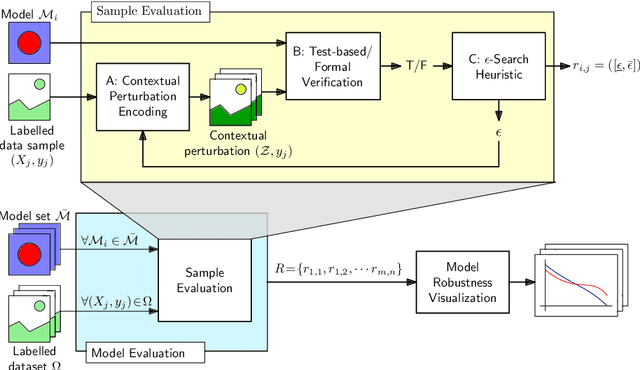
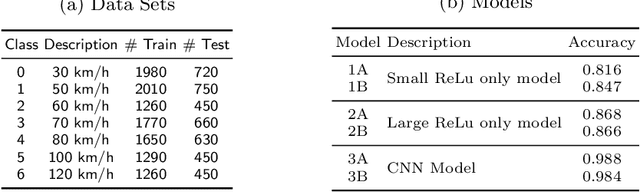


We introduce DeepCert, a tool-supported method for verifying the robustness of deep neural network (DNN) image classifiers to contextually relevant perturbations such as blur, haze, and changes in image contrast. While the robustness of DNN classifiers has been the subject of intense research in recent years, the solutions delivered by this research focus on verifying DNN robustness to small perturbations in the images being classified, with perturbation magnitude measured using established Lp norms. This is useful for identifying potential adversarial attacks on DNN image classifiers, but cannot verify DNN robustness to contextually relevant image perturbations, which are typically not small when expressed with Lp norms. DeepCert addresses this underexplored verification problem by supporting:(1) the encoding of real-world image perturbations; (2) the systematic evaluation of contextually relevant DNN robustness, using both testing and formal verification; (3) the generation of contextually relevant counterexamples; and, through these, (4) the selection of DNN image classifiers suitable for the operational context (i)envisaged when a potentially safety-critical system is designed, or (ii)observed by a deployed system. We demonstrate the effectiveness of DeepCert by showing how it can be used to verify the robustness of DNN image classifiers build for two benchmark datasets (`German Traffic Sign' and `CIFAR-10') to multiple contextually relevant perturbations.
Finding Invariants in Deep Neural Networks
Apr 29, 2019
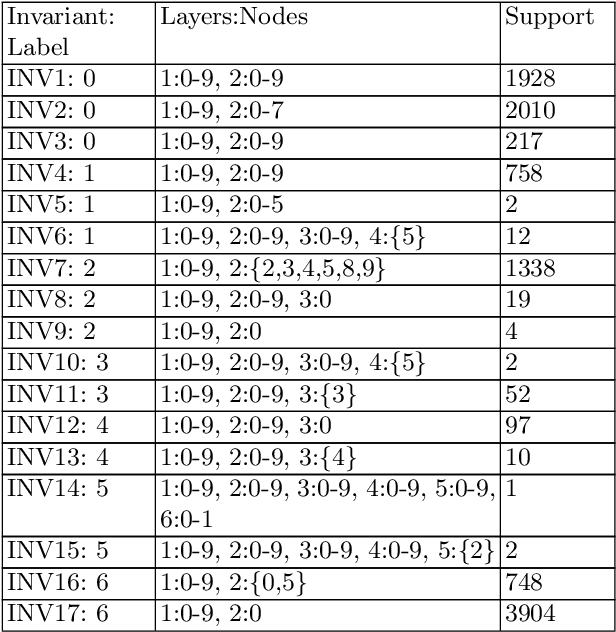


We present techniques for automatically inferring invariant properties of feed-forward neural networks. Our insight is that feed forward networks should be able to learn a decision logic that is captured in the activation patterns of its neurons. We propose to extract such decision patterns that can be considered as invariants of the network with respect to a certain output behavior. We present techniques to extract input invariants as convex predicates on the input space, and layer invariants that represent features captured in the hidden layers. We apply the techniques on the networks for the MNIST and ACASXU applications. Our experiments highlight the use of invariants in a variety of applications, such as explainability, providing robustness guarantees, detecting adversaries, simplifying proofs and network distillation.