 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Invariants in Deep Neural Networks
Apr 29, 2019
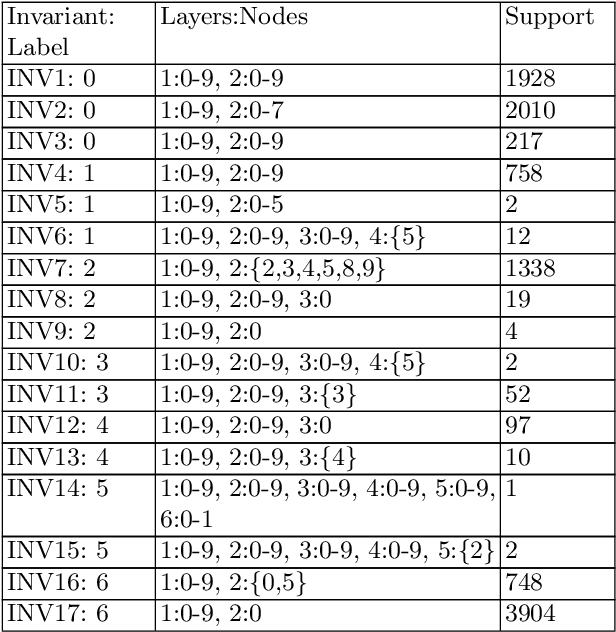


We present techniques for automatically inferring invariant properties of feed-forward neural networks. Our insight is that feed forward networks should be able to learn a decision logic that is captured in the activation patterns of its neurons. We propose to extract such decision patterns that can be considered as invariants of the network with respect to a certain output behavior. We present techniques to extract input invariants as convex predicates on the input space, and layer invariants that represent features captured in the hidden layers. We apply the techniques on the networks for the MNIST and ACASXU applications. Our experiments highlight the use of invariants in a variety of applications, such as explainability, providing robustness guarantees, detecting adversaries, simplifying proofs and network distillation.