 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistically Interpreting a Transformer-based 2-SAT Solver: An Axiomatic Approach
Paper and Code
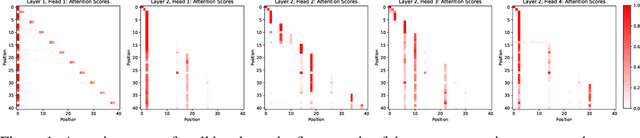

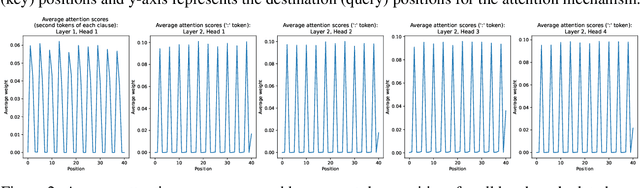

Mechanistic interpretability aims to reverse engineer the computation performed by a neural network in terms of its internal components. Although there is a growing body of research on mechanistic interpretation of neural networks, the notion of a mechanistic interpretation itself is often ad-hoc. Inspired by the notion of abstract interpretation from the program analysis literature that aims to develop approximate semantics for programs, we give a set of axioms that formally characterize a mechanistic interpretation as a description that approximately captures the semantics of the neural network under analysis in a compositional manner. We use these axioms to guide the mechanistic interpretability analysis of a Transformer-based model trained to solve the well-known 2-SAT problem. We are able to reverse engineer the algorithm learned by the model -- the model first parses the input formulas and then evaluates their satisfiability via enumeration of different possible valuations of the Boolean input variables. We also present evidence to support that the mechanistic interpretation of the analyzed model indeed satisfies the stated axioms.