 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Security is a Systems Problem
May 20, 2026We take the position that agent security must be approached as a systems problem: the AI model powering the agent must be treated as an untrusted component, and security invariants must be enforced at the system level. Through this lens, efforts to increase model robustness (the dominant viewpoint in the community) are insufficient on their own. Instead, we must complement existing efforts with techniques from the systems security domain. Based on our experience as cybersecurity researchers in operating systems, networks, formal methods, and adversarial machine learning, we articulate a set of core principles, grounded in decades of systems security research, that provide a foundation for designing agentic systems with predictable guarantees. As evidence, we analyze eleven representative real-world attacks on agents and discuss how systems principles, if realized, could have prevented these attacks. We also identify the research challenges that stand in the way of implementing these principles in agents.
Undetectable Backdoors in Model Parameters: Hiding Sparse Secrets in High Dimensions
May 05, 2026We present Sparse Backdoor, a supply-chain attack that plants a \emph{provably undetectable} backdoor in pre-trained image classifiers, including convolutional networks and Vision Transformers. The attack injects a structured sparse perturbation along a randomly chosen direction into a small subset of columns at each fully connected layer, propagating a trigger signal to an adversary-chosen target class, and masks the perturbation with an independent isotropic Gaussian dither. The dither serves a single technical purpose: it induces a clean reference distribution anchored at the pre-trained weights, against which undetectability can be formalized. Under a mild margin condition on the pre-trained classifier, we show that the dithered reference is functionally equivalent to the original classifier. We prove that distinguishing the backdoor-injected model from this reference is at least as hard as Sparse PCA detection, which is computationally infeasible under standard hardness assumptions. The guarantee holds against any probabilistic polynomial-time distinguisher with white-box access to the parameters.
Policy Compiler for Secure Agentic Systems
Feb 19, 2026LLM-based agents are increasingly being deployed in contexts requiring complex authorization policies: customer service protocols, approval workflows, data access restrictions, and regulatory compliance. Embedding these policies in prompts provides no enforcement guarantees. We present PCAS, a Policy Compiler for Agentic Systems that provides deterministic policy enforcement. Enforcing such policies requires tracking information flow across agents, which linear message histories cannot capture. Instead, PCAS models the agentic system state as a dependency graph capturing causal relationships among events such as tool calls, tool results, and messages. Policies are expressed in a Datalog-derived language, as declarative rules that account for transitive information flow and cross-agent provenance. A reference monitor intercepts all actions and blocks violations before execution, providing deterministic enforcement independent of model reasoning. PCAS takes an existing agent implementation and a policy specification, and compiles them into an instrumented system that is policy-compliant by construction, with no security-specific restructuring required. We evaluate PCAS on three case studies: information flow policies for prompt injection defense, approval workflows in a multi-agent pharmacovigilance system, and organizational policies for customer service. On customer service tasks, PCAS improves policy compliance from 48% to 93% across frontier models, with zero policy violations in instrumented runs.
Through the Stealth Lens: Rethinking Attacks and Defenses in RAG
Jun 04, 2025Retrieval-augmented generation (RAG) systems are vulnerable to attacks that inject poisoned passages into the retrieved set, even at low corruption rates. We show that existing attacks are not designed to be stealthy, allowing reliable detection and mitigation. We formalize stealth using a distinguishability-based security game. If a few poisoned passages are designed to control the response, they must differentiate themselves from benign ones, inherently compromising stealth. This motivates the need for attackers to rigorously analyze intermediate signals involved in generation$\unicode{x2014}$such as attention patterns or next-token probability distributions$\unicode{x2014}$to avoid easily detectable traces of manipulation. Leveraging attention patterns, we propose a passage-level score$\unicode{x2014}$the Normalized Passage Attention Score$\unicode{x2014}$used by our Attention-Variance Filter algorithm to identify and filter potentially poisoned passages. This method mitigates existing attacks, improving accuracy by up to $\sim 20 \%$ over baseline defenses. To probe the limits of attention-based defenses, we craft stealthier adaptive attacks that obscure such traces, achieving up to $35 \%$ attack success rate, and highlight the challenges in improving stealth.
MALADE: Orchestration of LLM-powered Agents with Retrieval Augmented Generation for Pharmacovigilance
Aug 03, 2024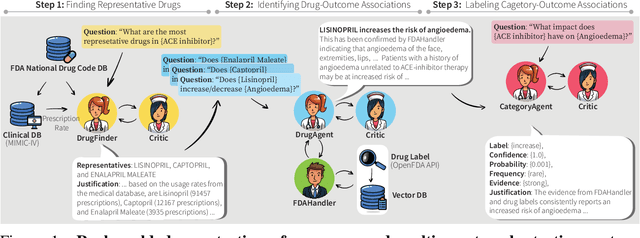
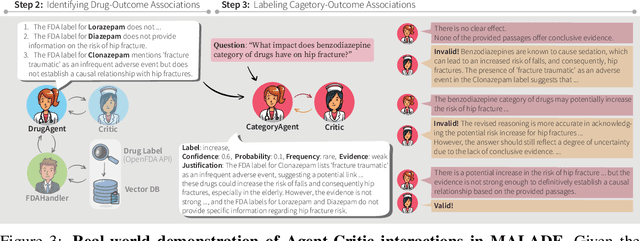
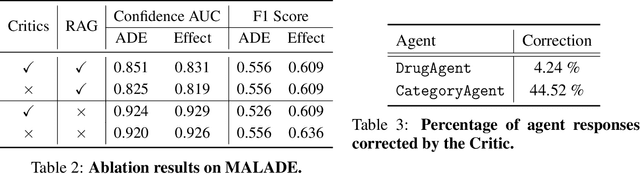
In the era of Large Language Models (LLMs), given their remarkable text understanding and generation abilities, there is an unprecedented opportunity to develop new, LLM-based methods for trustworthy medical knowledge synthesis, extraction and summarization. This paper focuses on the problem of Pharmacovigilance (PhV), where the significance and challenges lie in identifying Adverse Drug Events (ADEs) from diverse text sources, such as medical literature, clinical notes, and drug labels. Unfortunately, this task is hindered by factors including variations in the terminologies of drugs and outcomes, and ADE descriptions often being buried in large amounts of narrative text. We present MALADE, the first effective collaborative multi-agent system powered by LLM with Retrieval Augmented Generation for ADE extraction from drug label data. This technique involves augmenting a query to an LLM with relevant information extracted from text resources, and instructing the LLM to compose a response consistent with the augmented data. MALADE is a general LLM-agnostic architecture, and its unique capabilities are: (1) leveraging a variety of external sources, such as medical literature, drug labels, and FDA tools (e.g., OpenFDA drug information API), (2) extracting drug-outcome association in a structured format along with the strength of the association, and (3) providing explanations for established associations. Instantiated with GPT-4 Turbo or GPT-4o, and FDA drug label data, MALADE demonstrates its efficacy with an Area Under ROC Curve of 0.90 against the OMOP Ground Truth table of ADEs. Our implementation leverages the Langroid multi-agent LLM framework and can be found at https://github.com/jihyechoi77/malade.
Mechanistically Interpreting a Transformer-based 2-SAT Solver: An Axiomatic Approach
Jul 18, 2024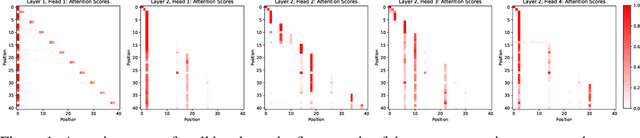

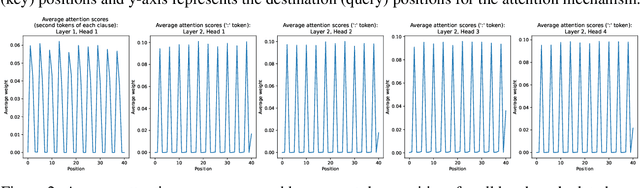

Mechanistic interpretability aims to reverse engineer the computation performed by a neural network in terms of its internal components. Although there is a growing body of research on mechanistic interpretation of neural networks, the notion of a mechanistic interpretation itself is often ad-hoc. Inspired by the notion of abstract interpretation from the program analysis literature that aims to develop approximate semantics for programs, we give a set of axioms that formally characterize a mechanistic interpretation as a description that approximately captures the semantics of the neural network under analysis in a compositional manner. We use these axioms to guide the mechanistic interpretability analysis of a Transformer-based model trained to solve the well-known 2-SAT problem. We are able to reverse engineer the algorithm learned by the model -- the model first parses the input formulas and then evaluates their satisfiability via enumeration of different possible valuations of the Boolean input variables. We also present evidence to support that the mechanistic interpretation of the analyzed model indeed satisfies the stated axioms.
Two Heads are Better than One: Towards Better Adversarial Robustness by Combining Transduction and Rejection
May 27, 2023


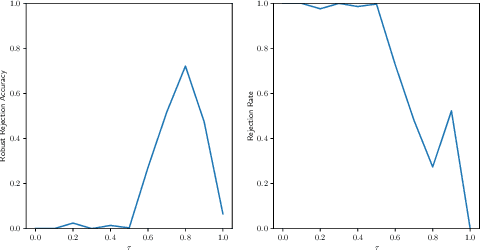
Both transduction and rejection have emerged as important techniques for defending against adversarial perturbations. A recent work by Tram\`er showed that, in the rejection-only case (no transduction), a strong rejection-solution can be turned into a strong (but computationally inefficient) non-rejection solution. This detector-to-classifier reduction has been mostly applied to give evidence that certain claims of strong selective-model solutions are susceptible, leaving the benefits of rejection unclear. On the other hand, a recent work by Goldwasser et al. showed that rejection combined with transduction can give provable guarantees (for certain problems) that cannot be achieved otherwise. Nevertheless, under recent strong adversarial attacks (GMSA, which has been shown to be much more effective than AutoAttack against transduction), Goldwasser et al.'s work was shown to have low performance in a practical deep-learning setting. In this paper, we take a step towards realizing the promise of transduction+rejection in more realistic scenarios. Theoretically, we show that a novel application of Tram\`er's classifier-to-detector technique in the transductive setting can give significantly improved sample-complexity for robust generalization. While our theoretical construction is computationally inefficient, it guides us to identify an efficient transductive algorithm to learn a selective model. Extensive experiments using state of the art attacks (AutoAttack, GMSA) show that our solutions provide significantly better robust accuracy.
Robust Mean Estimation under Coordinate-level Corruption
Feb 10, 2020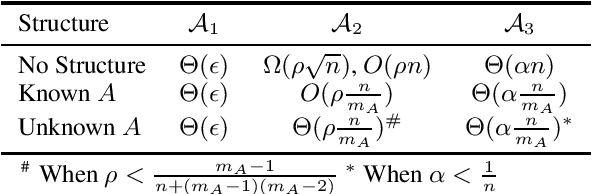
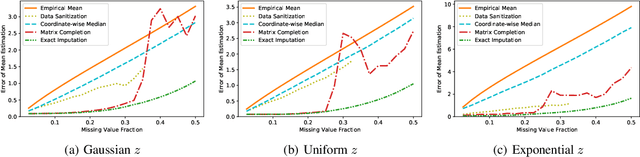
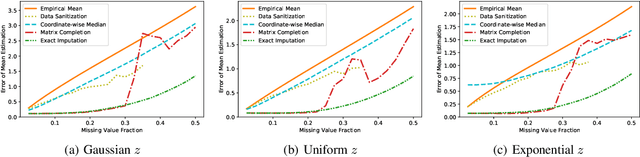
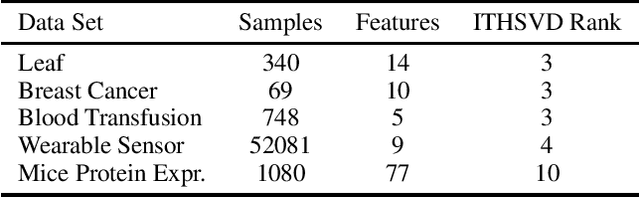
Data corruption, systematic or adversarial, may skew statistical estimation severely. Recent work provides computationally efficient estimators that nearly match the information-theoretic optimal statistic. Yet the corruption model they consider measures sample-level corruption and is not fine-grained enough for many real-world applications. In this paper, we propose a coordinate-level metric of distribution shift over high-dimensional settings with n coordinates. We introduce and analyze robust mean estimation techniques against an adversary who may hide individual coordinates of samples while being bounded by that metric. We show that for structured distribution settings, methods that leverage structure to fill in missing entries before mean estimation can improve the estimation accuracy by a factor of approximately n compared to structure-agnostic methods. We also leverage recent progress in matrix completion to obtain estimators for recovering the true mean of the samples in settings of unknown structure. We demonstrate with real-world data that our methods can capture the dependencies across attributes and provide accurate mean estimation even in high-magnitude corruption settings.