 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLKV: Efficiently Scaling up Large Embedding Model Training with Disk-based Key-Value Storage
Apr 02, 2025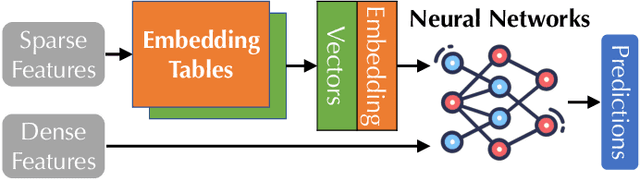
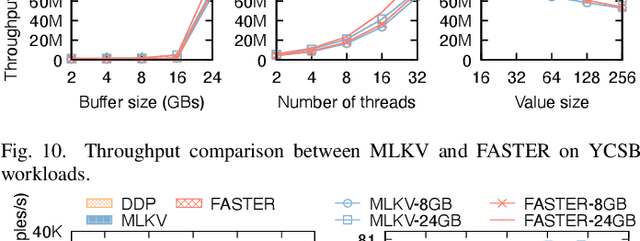
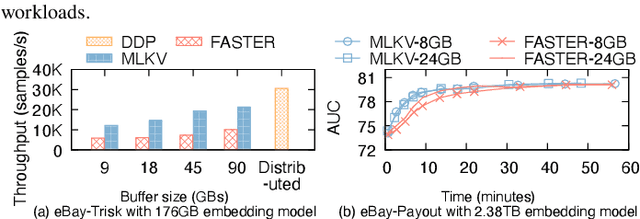

Many modern machine learning (ML) methods rely on embedding models to learn vector representations (embeddings) for a set of entities (embedding tables). As increasingly diverse ML applications utilize embedding models and embedding tables continue to grow in size and number, there has been a surge in the ad-hoc development of specialized frameworks targeted to train large embedding models for specific tasks. Although the scalability issues that arise in different embedding model training tasks are similar, each of these frameworks independently reinvents and customizes storage components for specific tasks, leading to substantial duplicated engineering efforts in both development and deployment. This paper presents MLKV, an efficient, extensible, and reusable data storage framework designed to address the scalability challenges in embedding model training, specifically data stall and staleness. MLKV augments disk-based key-value storage by democratizing optimizations that were previously exclusive to individual specialized frameworks and provides easy-to-use interfaces for embedding model training tasks. Extensive experiments on open-source workloads, as well as applications in eBay's payment transaction risk detection and seller payment risk detection, show that MLKV outperforms offloading strategies built on top of industrial-strength key-value stores by 1.6-12.6x. MLKV is open-source at https://github.com/llm-db/MLKV.
Armada: Memory-Efficient Distributed Training of Large-Scale Graph Neural Networks
Feb 25, 2025We study distributed training of Graph Neural Networks (GNNs) on billion-scale graphs that are partitioned across machines. Efficient training in this setting relies on min-edge-cut partitioning algorithms, which minimize cross-machine communication due to GNN neighborhood sampling. Yet, min-edge-cut partitioning over large graphs remains a challenge: State-of-the-art (SoTA) offline methods (e.g., METIS) are effective, but they require orders of magnitude more memory and runtime than GNN training itself, while computationally efficient algorithms (e.g., streaming greedy approaches) suffer from increased edge cuts. Thus, in this work we introduce Armada, a new end-to-end system for distributed GNN training whose key contribution is GREM, a novel min-edge-cut partitioning algorithm that can efficiently scale to large graphs. GREM builds on streaming greedy approaches with one key addition: prior vertex assignments are continuously refined during streaming, rather than frozen after an initial greedy selection. Our theoretical analysis and experimental results show that this refinement is critical to minimizing edge cuts and enables GREM to reach partition quality comparable to METIS but with 8-65x less memory and 8-46x faster. Given a partitioned graph, Armada leverages a new disaggregated architecture for distributed GNN training to further improve efficiency; we find that on common cloud machines, even with zero communication, GNN neighborhood sampling and feature loading bottleneck training. Disaggregation allows Armada to independently allocate resources for these operations and ensure that expensive GPUs remain saturated with computation. We evaluate Armada against SoTA systems for distributed GNN training and find that the disaggregated architecture leads to runtime improvements up to 4.5x and cost reductions up to 3.1x.
Fundamental Challenges in Evaluating Text2SQL Solutions and Detecting Their Limitations
Jan 30, 2025
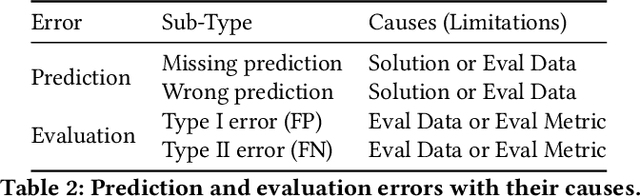
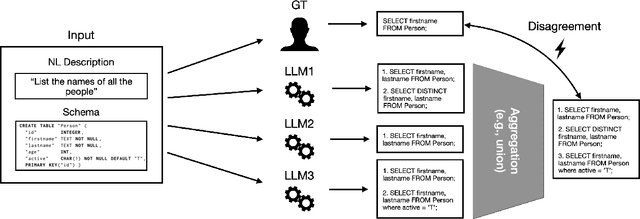
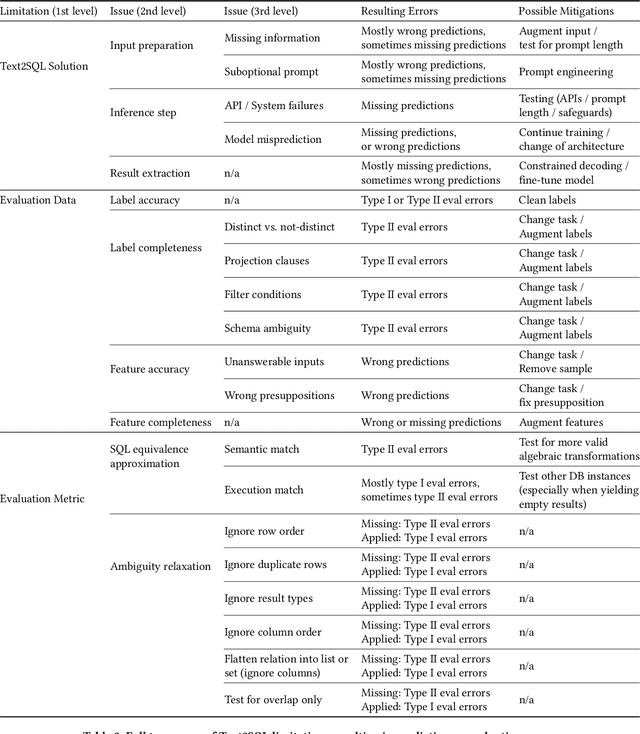
In this work, we dive into the fundamental challenges of evaluating Text2SQL solutions and highlight potential failure causes and the potential risks of relying on aggregate metrics in existing benchmarks. We identify two largely unaddressed limitations in current open benchmarks: (1) data quality issues in the evaluation data, mainly attributed to the lack of capturing the probabilistic nature of translating a natural language description into a structured query (e.g., NL ambiguity), and (2) the bias introduced by using different match functions as approximations for SQL equivalence. To put both limitations into context, we propose a unified taxonomy of all Text2SQL limitations that can lead to both prediction and evaluation errors. We then motivate the taxonomy by providing a survey of Text2SQL limitations using state-of-the-art Text2SQL solutions and benchmarks. We describe the causes of limitations with real-world examples and propose potential mitigation solutions for each category in the taxonomy. We conclude by highlighting the open challenges encountered when deploying such mitigation strategies or attempting to automatically apply the taxonomy.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024

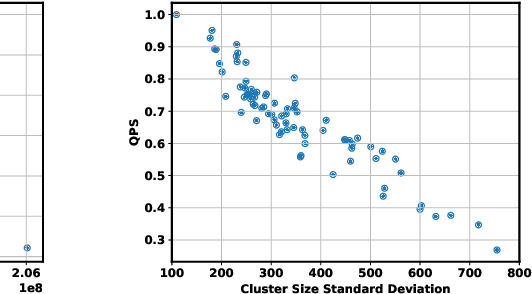

The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
TSDS: Data Selection for Task-Specific Model Finetuning
Oct 23, 2024



Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present TSDS (Task-Specific Data Selection), a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task. To do so, we formulate data selection for task-specific finetuning as an optimization problem with a distribution alignment loss based on optimal transport to capture the discrepancy between the selected data and the target distribution. In addition, we add a regularizer to encourage the diversity of the selected data and incorporate kernel density estimation into the regularizer to reduce the negative effects of near-duplicates among the candidate data. We connect our optimization problem to nearest neighbor search and design efficient algorithms to compute the optimal solution based on approximate nearest neighbor search techniques. We evaluate our method on data selection for both continued pretraining and instruction tuning of language models. We show that instruction tuning using data selected by our method with a 1% selection ratio often outperforms using the full dataset and beats the baseline selection methods by 1.5 points in F1 score on average.
Data Selection for Task-Specific Model Finetuning
Oct 15, 2024Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task. To do so, we formulate data selection for task-specific finetuning as an optimization problem with a distribution alignment loss based on optimal transport to capture the discrepancy between the selected data and the target distribution. In addition, we add a regularizer to encourage the diversity of the selected data and incorporate kernel density estimation into the regularizer to reduce the negative effects of near-duplicates among the candidate data. We connect our optimization problem to nearest neighbor search and design efficient algorithms to compute the optimal solution based on approximate nearest neighbor search techniques. We evaluate our method on data selection for both continued pretraining and instruction tuning of language models. We show that instruction tuning using data selected by our method with a 1% selection ratio often outperforms using the full dataset and beats the baseline selection methods by 1.5 points in F1 score on average.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning
May 28, 2023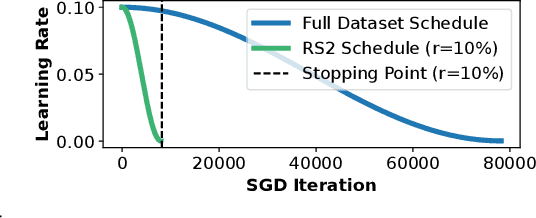
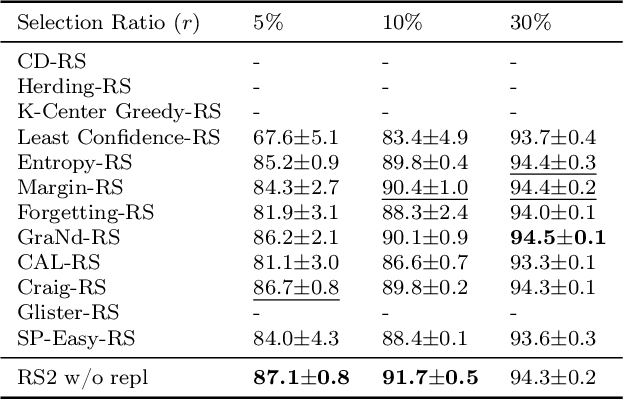
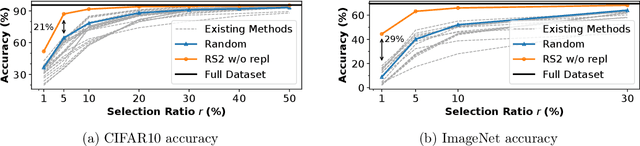
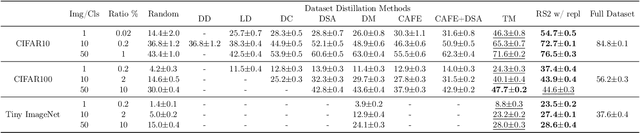
Methods for carefully selecting or generating a small set of training data to learn from, i.e., data pruning, coreset selection, and data distillation, have been shown to be effective in reducing the ever-increasing cost of training neural networks. Behind this success are rigorously designed strategies for identifying informative training examples out of large datasets. However, these strategies come with additional computational costs associated with subset selection or data distillation before training begins, and furthermore, many are shown to even under-perform random sampling in high data compression regimes. As such, many data pruning, coreset selection, or distillation methods may not reduce 'time-to-accuracy', which has become a critical efficiency measure of training deep neural networks over large datasets. In this work, we revisit a powerful yet overlooked random sampling strategy to address these challenges and introduce an approach called Repeated Sampling of Random Subsets (RSRS or RS2), where we randomly sample the subset of training data for each epoch of model training. We test RS2 against thirty state-of-the-art data pruning and data distillation methods across four datasets including ImageNet. Our results demonstrate that RS2 significantly reduces time-to-accuracy compared to existing techniques. For example, when training on ImageNet in the high-compression regime (using less than 10% of the dataset each epoch), RS2 yields accuracy improvements up to 29% compared to competing pruning methods while offering a runtime reduction of 7x. Beyond the above meta-study, we provide a convergence analysis for RS2 and discuss its generalization capability. The primary goal of our work is to establish RS2 as a competitive baseline for future data selection or distillation techniques aimed at efficient training.
Growing and Serving Large Open-domain Knowledge Graphs
May 16, 2023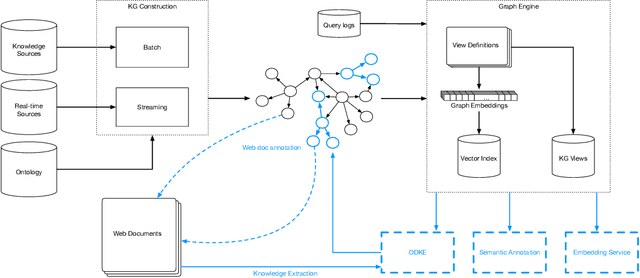
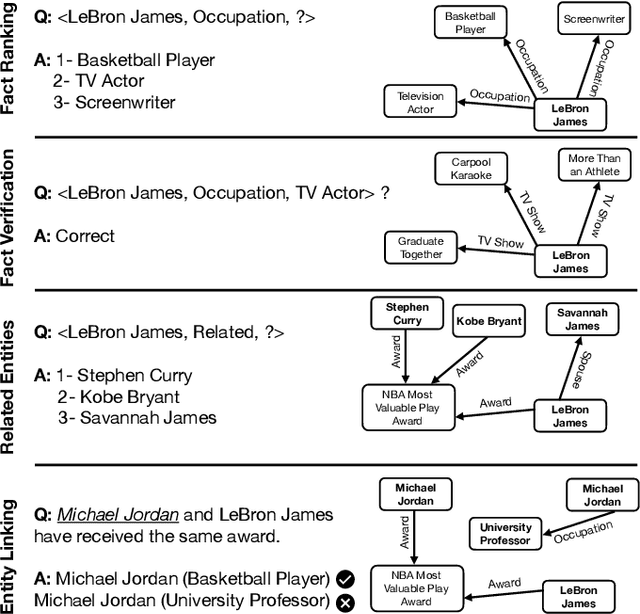
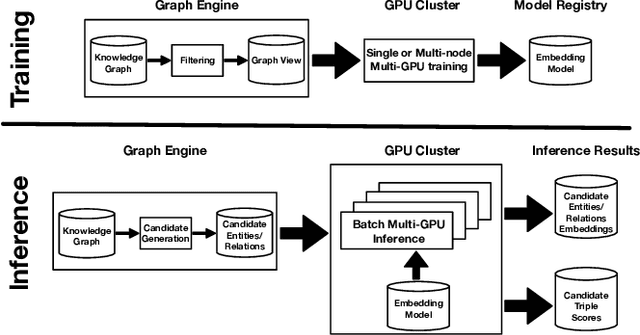
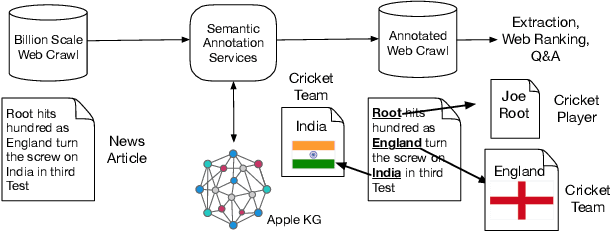
Applications of large open-domain knowledge graphs (KGs) to real-world problems pose many unique challenges. In this paper, we present extensions to Saga our platform for continuous construction and serving of knowledge at scale. In particular, we describe a pipeline for training knowledge graph embeddings that powers key capabilities such as fact ranking, fact verification, a related entities service, and support for entity linking. We then describe how our platform, including graph embeddings, can be leveraged to create a Semantic Annotation service that links unstructured Web documents to entities in our KG. Semantic annotation of the Web effectively expands our knowledge graph with edges to open-domain Web content which can be used in various search and ranking problems. Finally, we leverage annotated Web documents to drive Open-domain Knowledge Extraction. This targeted extraction framework identifies important coverage issues in the KG, then finds relevant data sources for target entities on the Web and extracts missing information to enrich the KG. Finally, we describe adaptations to our knowledge platform needed to construct and serve private personal knowledge on-device. This includes private incremental KG construction, cross-device knowledge sync, and global knowledge enrichment.
High-Throughput Vector Similarity Search in Knowledge Graphs
Apr 04, 2023



There is an increasing adoption of machine learning for encoding data into vectors to serve online recommendation and search use cases. As a result, recent data management systems propose augmenting query processing with online vector similarity search. In this work, we explore vector similarity search in the context of Knowledge Graphs (KGs). Motivated by the tasks of finding related KG queries and entities for past KG query workloads, we focus on hybrid vector similarity search (hybrid queries for short) where part of the query corresponds to vector similarity search and part of the query corresponds to predicates over relational attributes associated with the underlying data vectors. For example, given past KG queries for a song entity, we want to construct new queries for new song entities whose vector representations are close to the vector representation of the entity in the past KG query. But entities in a KG also have non-vector attributes such as a song associated with an artist, a genre, and a release date. Therefore, suggested entities must also satisfy query predicates over non-vector attributes beyond a vector-based similarity predicate. While these tasks are central to KGs, our contributions are generally applicable to hybrid queries. In contrast to prior works that optimize online queries, we focus on enabling efficient batch processing of past hybrid query workloads. We present our system, HQI, for high-throughput batch processing of hybrid queries. We introduce a workload-aware vector data partitioning scheme to tailor the vector index layout to the given workload and describe a multi-query optimization technique to reduce the overhead of vector similarity computations. We evaluate our methods on industrial workloads and demonstrate that HQI yields a 31x improvement in throughput for finding related KG queries compared to existing hybrid query processing approaches.