 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Model Selection for Large Language Models
Oct 10, 2025We introduce LLM SELECTOR, the first framework for active model selection of Large Language Models (LLMs). Unlike prior evaluation and benchmarking approaches that rely on fully annotated datasets, LLM SELECTOR efficiently identifies the best LLM with limited annotations. In particular, for any given task, LLM SELECTOR adaptively selects a small set of queries to annotate that are most informative about the best model for the task. To further reduce annotation cost, we leverage a judge-based oracle annotation model. Through extensive experiments on 6 benchmarks with 151 LLMs, we show that LLM SELECTOR reduces annotation costs by up to 59.62% when selecting the best and near-best LLM for the task.
All models are wrong, some are useful: Model Selection with Limited Labels
Oct 17, 2024



With the multitude of pretrained models available thanks to the advancements in large-scale supervised and self-supervised learning, choosing the right model is becoming increasingly pivotal in the machine learning lifecycle. However, much like the training process, choosing the best pretrained off-the-shelf model for raw, unlabeled data is a labor-intensive task. To overcome this, we introduce MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. Given a pool of unlabeled target data, MODEL SELECTOR samples a small subset of highly informative examples for labeling, in order to efficiently identify the best pretrained model for deployment on this target dataset. Through extensive experiments, we demonstrate that MODEL SELECTOR drastically reduces the need for labeled data while consistently picking the best or near-best performing model. Across 18 model collections on 16 different datasets, comprising over 1,500 pretrained models, MODEL SELECTOR reduces the labeling cost by up to 94.15% to identify the best model compared to the cost of the strongest baseline. Our results further highlight the robustness of MODEL SELECTOR in model selection, as it reduces the labeling cost by up to 72.41% when selecting a near-best model, whose accuracy is only within 1% of the best model.
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning
May 28, 2023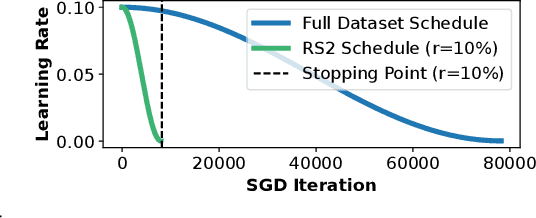
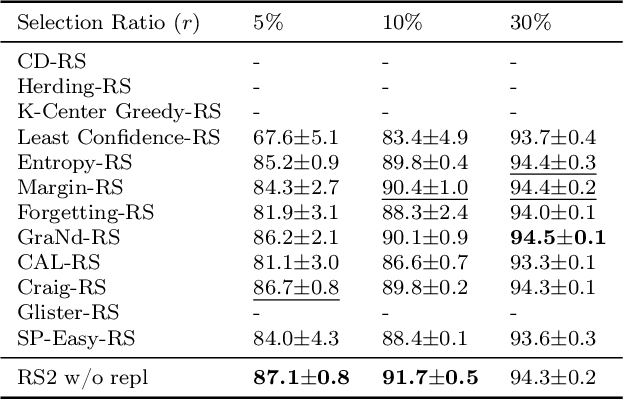
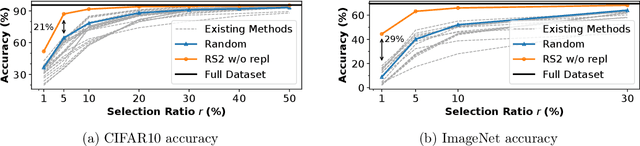
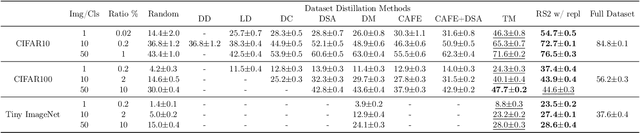
Methods for carefully selecting or generating a small set of training data to learn from, i.e., data pruning, coreset selection, and data distillation, have been shown to be effective in reducing the ever-increasing cost of training neural networks. Behind this success are rigorously designed strategies for identifying informative training examples out of large datasets. However, these strategies come with additional computational costs associated with subset selection or data distillation before training begins, and furthermore, many are shown to even under-perform random sampling in high data compression regimes. As such, many data pruning, coreset selection, or distillation methods may not reduce 'time-to-accuracy', which has become a critical efficiency measure of training deep neural networks over large datasets. In this work, we revisit a powerful yet overlooked random sampling strategy to address these challenges and introduce an approach called Repeated Sampling of Random Subsets (RSRS or RS2), where we randomly sample the subset of training data for each epoch of model training. We test RS2 against thirty state-of-the-art data pruning and data distillation methods across four datasets including ImageNet. Our results demonstrate that RS2 significantly reduces time-to-accuracy compared to existing techniques. For example, when training on ImageNet in the high-compression regime (using less than 10% of the dataset each epoch), RS2 yields accuracy improvements up to 29% compared to competing pruning methods while offering a runtime reduction of 7x. Beyond the above meta-study, we provide a convergence analysis for RS2 and discuss its generalization capability. The primary goal of our work is to establish RS2 as a competitive baseline for future data selection or distillation techniques aimed at efficient training.
Gated Domain Units for Multi-source Domain Generalization
Jun 24, 2022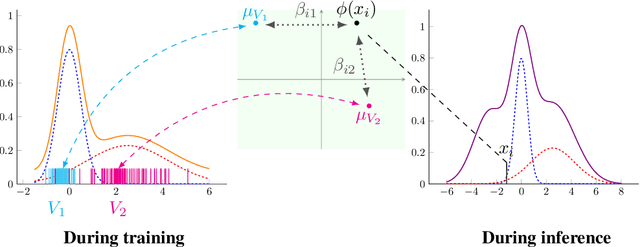

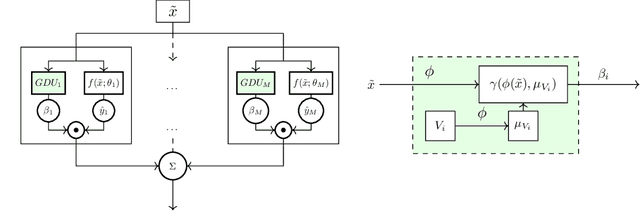
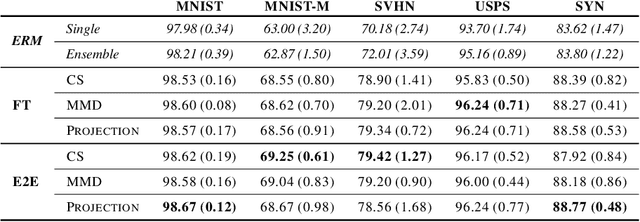
Distribution shift (DS) is a common problem that deteriorates the performance of learning machines. To overcome this problem, we postulate that real-world distributions are composed of elementary distributions that remain invariant across different domains. We call this an invariant elementary distribution (I.E.D.) assumption. This invariance thus enables knowledge transfer to unseen domains. To exploit this assumption in domain generalization (DG), we developed a modular neural network layer that consists of Gated Domain Units (GDUs). Each GDU learns an embedding of an individual elementary domain that allows us to encode the domain similarities during the training. During inference, the GDUs compute similarities between an observation and each of the corresponding elementary distributions which are then used to form a weighted ensemble of learning machines. Because our layer is trained with backpropagation, it can be easily integrated into existing deep learning frameworks. Our evaluation on Digits5, ECG, Camelyon17, iWildCam, and FMoW shows a significant improvement in the performance on out-of-training target domains without any access to data from the target domains. This finding supports the validity of the I.E.D. assumption in real-world data distributions.