 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Model Selection for Large Language Models
Oct 10, 2025We introduce LLM SELECTOR, the first framework for active model selection of Large Language Models (LLMs). Unlike prior evaluation and benchmarking approaches that rely on fully annotated datasets, LLM SELECTOR efficiently identifies the best LLM with limited annotations. In particular, for any given task, LLM SELECTOR adaptively selects a small set of queries to annotate that are most informative about the best model for the task. To further reduce annotation cost, we leverage a judge-based oracle annotation model. Through extensive experiments on 6 benchmarks with 151 LLMs, we show that LLM SELECTOR reduces annotation costs by up to 59.62% when selecting the best and near-best LLM for the task.
When three experiments are better than two: Avoiding intractable correlated aleatoric uncertainty by leveraging a novel bias--variance tradeoff
Sep 04, 2025Real-world experimental scenarios are characterized by the presence of heteroskedastic aleatoric uncertainty, and this uncertainty can be correlated in batched settings. The bias--variance tradeoff can be used to write the expected mean squared error between a model distribution and a ground-truth random variable as the sum of an epistemic uncertainty term, the bias squared, and an aleatoric uncertainty term. We leverage this relationship to propose novel active learning strategies that directly reduce the bias between experimental rounds, considering model systems both with and without noise. Finally, we investigate methods to leverage historical data in a quadratic manner through the use of a novel cobias--covariance relationship, which naturally proposes a mechanism for batching through an eigendecomposition strategy. When our difference-based method leveraging the cobias--covariance relationship is utilized in a batched setting (with a quadratic estimator), we outperform a number of canonical methods including BALD and Least Confidence.
All models are wrong, some are useful: Model Selection with Limited Labels
Oct 17, 2024



With the multitude of pretrained models available thanks to the advancements in large-scale supervised and self-supervised learning, choosing the right model is becoming increasingly pivotal in the machine learning lifecycle. However, much like the training process, choosing the best pretrained off-the-shelf model for raw, unlabeled data is a labor-intensive task. To overcome this, we introduce MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. Given a pool of unlabeled target data, MODEL SELECTOR samples a small subset of highly informative examples for labeling, in order to efficiently identify the best pretrained model for deployment on this target dataset. Through extensive experiments, we demonstrate that MODEL SELECTOR drastically reduces the need for labeled data while consistently picking the best or near-best performing model. Across 18 model collections on 16 different datasets, comprising over 1,500 pretrained models, MODEL SELECTOR reduces the labeling cost by up to 94.15% to identify the best model compared to the cost of the strongest baseline. Our results further highlight the robustness of MODEL SELECTOR in model selection, as it reduces the labeling cost by up to 72.41% when selecting a near-best model, whose accuracy is only within 1% of the best model.
(Implicit) Ensembles of Ensembles: Epistemic Uncertainty Collapse in Large Models
Sep 04, 2024Epistemic uncertainty is crucial for safety-critical applications and out-of-distribution detection tasks. Yet, we uncover a paradoxical phenomenon in deep learning models: an epistemic uncertainty collapse as model complexity increases, challenging the assumption that larger models invariably offer better uncertainty quantification. We propose that this stems from implicit ensembling within large models. To support this hypothesis, we demonstrate epistemic uncertainty collapse empirically across various architectures, from explicit ensembles of ensembles and simple MLPs to state-of-the-art vision models, including ResNets and Vision Transformers -- for the latter, we examine implicit ensemble extraction and decompose larger models into diverse sub-models, recovering epistemic uncertainty. We provide theoretical justification for these phenomena and explore their implications for uncertainty estimation.
Min P Sampling: Balancing Creativity and Coherence at High Temperature
Jul 01, 2024Large Language Models (LLMs) generate longform text by successively sampling the next token based on the probability distribution of the token vocabulary at each decoding step. Current popular truncation sampling methods such as top-$p$ sampling, also known as nucleus sampling, often struggle to balance coherence and creativity in generating text, particularly when using higher temperatures. To address this issue, we propose min-$p$, a dynamic truncation sampling method, that establishes a minimum base percentage threshold for tokens, which the scales according to the probability of the top candidate token. Through experiments on several benchmarks, such as GPQA, GSM8K and AlpacaEval Creative Writing, we demonstrate that min-$p$ improves the coherence and quality of generated text even at high temperatures, while also facilitating more creative and diverse outputs compared to top-$p$ and other sampling methods. As of writing, min-$p$ has been adopted by multiple open-source LLM implementations, and have been independently assessed by members of the open-source LLM community, further validating its practical utility and potential.
The Benefits and Risks of Transductive Approaches for AI Fairness
Jun 17, 2024



Recently, transductive learning methods, which leverage holdout sets during training, have gained popularity for their potential to improve speed, accuracy, and fairness in machine learning models. Despite this, the composition of the holdout set itself, particularly the balance of sensitive sub-groups, has been largely overlooked. Our experiments on CIFAR and CelebA datasets show that compositional changes in the holdout set can substantially influence fairness metrics. Imbalanced holdout sets exacerbate existing disparities, while balanced holdouts can mitigate issues introduced by imbalanced training data. These findings underline the necessity of constructing holdout sets that are both diverse and representative.
CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training
Jun 15, 2024Selecting high-quality data for pre-training is crucial in shaping the downstream task performance of language models. A major challenge lies in identifying this optimal subset, a problem generally considered intractable, thus necessitating scalable and effective heuristics. In this work, we propose a data selection method, CoLoR-Filter (Conditional Loss Reduction Filtering), which leverages an empirical Bayes-inspired approach to derive a simple and computationally efficient selection criterion based on the relative loss values of two auxiliary models. In addition to the modeling rationale, we evaluate CoLoR-Filter empirically on two language modeling tasks: (1) selecting data from C4 for domain adaptation to evaluation on Books and (2) selecting data from C4 for a suite of downstream multiple-choice question answering tasks. We demonstrate favorable scaling both as we subselect more aggressively and using small auxiliary models to select data for large target models. As one headline result, CoLoR-Filter data selected using a pair of 150m parameter auxiliary models can train a 1.2b parameter target model to match a 1.2b parameter model trained on 25b randomly selected tokens with 25x less data for Books and 11x less data for the downstream tasks. Code: https://github.com/davidbrandfonbrener/color-filter-olmo Filtered data: https://huggingface.co/datasets/davidbrandfonbrener/color-filtered-c4
Advancing Deep Active Learning & Data Subset Selection: Unifying Principles with Information-Theory Intuitions
Jan 09, 2024
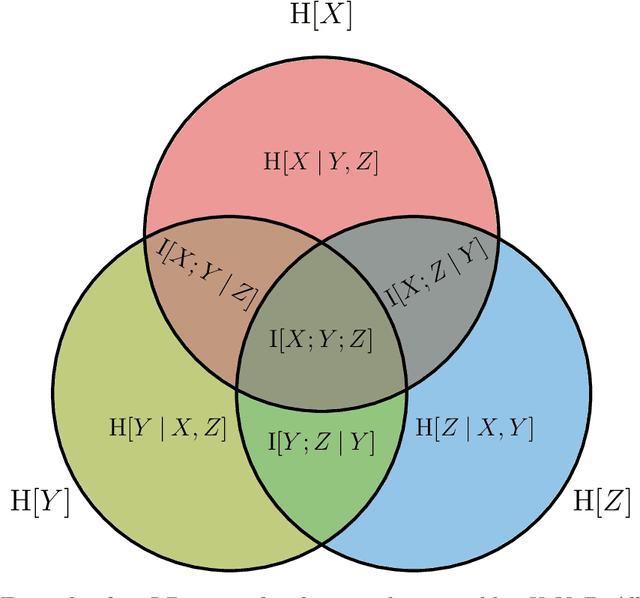


At its core, this thesis aims to enhance the practicality of deep learning by improving the label and training efficiency of deep learning models. To this end, we investigate data subset selection techniques, specifically active learning and active sampling, grounded in information-theoretic principles. Active learning improves label efficiency, while active sampling enhances training efficiency. Supervised deep learning models often require extensive training with labeled data. Label acquisition can be expensive and time-consuming, and training large models is resource-intensive, hindering the adoption outside academic research and ``big tech.'' Existing methods for data subset selection in deep learning often rely on heuristics or lack a principled information-theoretic foundation. In contrast, this thesis examines several objectives for data subset selection and their applications within deep learning, striving for a more principled approach inspired by information theory. We begin by disentangling epistemic and aleatoric uncertainty in single forward-pass deep neural networks, which provides helpful intuitions and insights into different forms of uncertainty and their relevance for data subset selection. We then propose and investigate various approaches for active learning and data subset selection in (Bayesian) deep learning. Finally, we relate various existing and proposed approaches to approximations of information quantities in weight or prediction space. Underpinning this work is a principled and practical notation for information-theoretic quantities that includes both random variables and observed outcomes. This thesis demonstrates the benefits of working from a unified perspective and highlights the potential impact of our contributions to the practical application of deep learning.
Prediction-Oriented Bayesian Active Learning
Apr 17, 2023



Information-theoretic approaches to active learning have traditionally focused on maximising the information gathered about the model parameters, most commonly by optimising the BALD score. We highlight that this can be suboptimal from the perspective of predictive performance. For example, BALD lacks a notion of an input distribution and so is prone to prioritise data of limited relevance. To address this we propose the expected predictive information gain (EPIG), an acquisition function that measures information gain in the space of predictions rather than parameters. We find that using EPIG leads to stronger predictive performance compared with BALD across a range of datasets and models, and thus provides an appealing drop-in replacement.
Does `Deep Learning on a Data Diet' reproduce? Overall yes, but GraNd at Initialization does not
Mar 26, 2023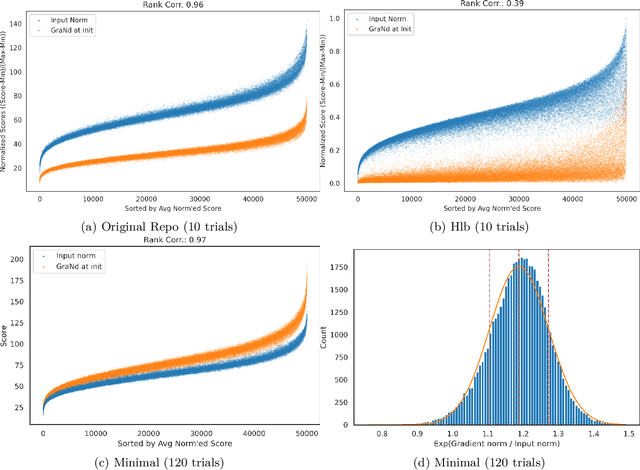
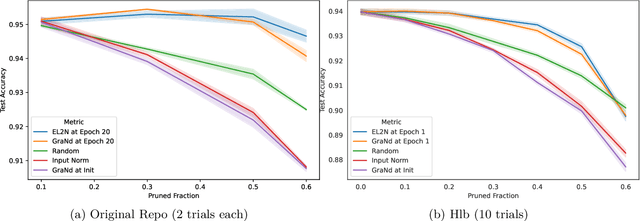
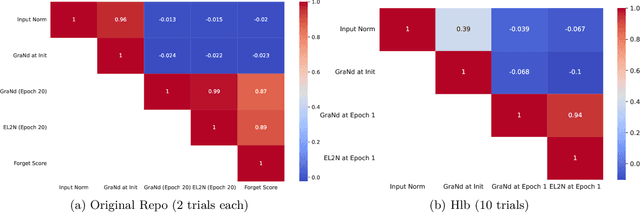
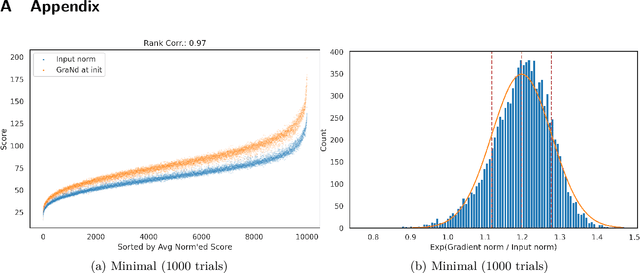
The paper 'Deep Learning on a Data Diet' by Paul et al. (2021) introduces two innovative metrics for pruning datasets during the training of neural networks. While we are able to replicate the results for the EL2N score at epoch 20, the same cannot be said for the GraNd score at initialization. The GraNd scores later in training provide useful pruning signals, however. The GraNd score at initialization calculates the average gradient norm of an input sample across multiple randomly initialized models before any training has taken place. Our analysis reveals a strong correlation between the GraNd score at initialization and the input norm of a sample, suggesting that the latter could have been a cheap new baseline for data pruning. Unfortunately, neither the GraNd score at initialization nor the input norm surpasses random pruning in performance. This contradicts one of the findings in Paul et al. (2021). We were unable to reproduce their CIFAR-10 results using both an updated version of the original JAX repository and in a newly implemented PyTorch codebase. An investigation of the underlying JAX/FLAX code from 2021 surfaced a bug in the checkpoint restoring code that was fixed in April 2021 (https://github.com/google/flax/commit/28fbd95500f4bf2f9924d2560062fa50e919b1a5).