 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Model Selection for Large Language Models
Oct 10, 2025We introduce LLM SELECTOR, the first framework for active model selection of Large Language Models (LLMs). Unlike prior evaluation and benchmarking approaches that rely on fully annotated datasets, LLM SELECTOR efficiently identifies the best LLM with limited annotations. In particular, for any given task, LLM SELECTOR adaptively selects a small set of queries to annotate that are most informative about the best model for the task. To further reduce annotation cost, we leverage a judge-based oracle annotation model. Through extensive experiments on 6 benchmarks with 151 LLMs, we show that LLM SELECTOR reduces annotation costs by up to 59.62% when selecting the best and near-best LLM for the task.
Evaluating the Limits of Large Language Models in Multilingual Legal Reasoning
Sep 26, 2025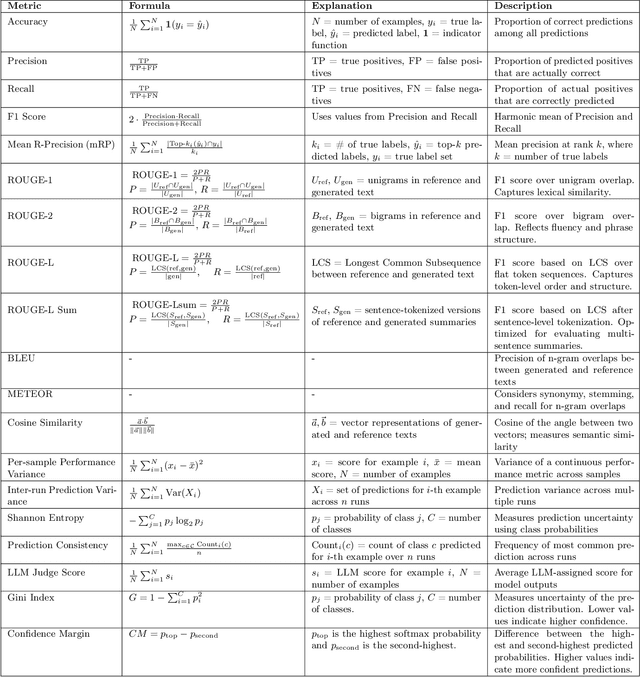
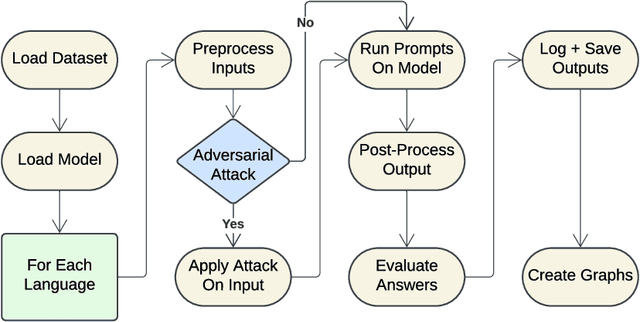

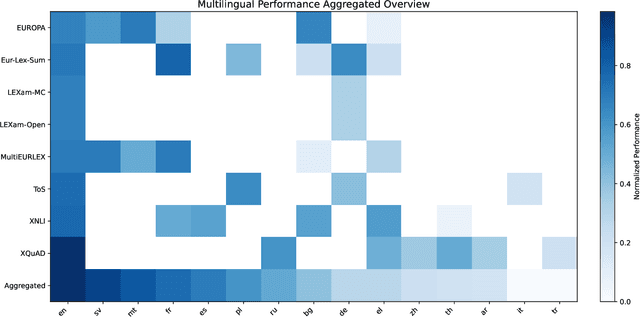
In an era dominated by Large Language Models (LLMs), understanding their capabilities and limitations, especially in high-stakes fields like law, is crucial. While LLMs such as Meta's LLaMA, OpenAI's ChatGPT, Google's Gemini, DeepSeek, and other emerging models are increasingly integrated into legal workflows, their performance in multilingual, jurisdictionally diverse, and adversarial contexts remains insufficiently explored. This work evaluates LLaMA and Gemini on multilingual legal and non-legal benchmarks, and assesses their adversarial robustness in legal tasks through character and word-level perturbations. We use an LLM-as-a-Judge approach for human-aligned evaluation. We moreover present an open-source, modular evaluation pipeline designed to support multilingual, task-diverse benchmarking of any combination of LLMs and datasets, with a particular focus on legal tasks, including classification, summarization, open questions, and general reasoning. Our findings confirm that legal tasks pose significant challenges for LLMs with accuracies often below 50% on legal reasoning benchmarks such as LEXam, compared to over 70% on general-purpose tasks like XNLI. In addition, while English generally yields more stable results, it does not always lead to higher accuracy. Prompt sensitivity and adversarial vulnerability is also shown to persist across languages. Finally, a correlation is found between the performance of a language and its syntactic similarity to English. We also observe that LLaMA is weaker than Gemini, with the latter showing an average advantage of about 24 percentage points across the same task. Despite improvements in newer LLMs, challenges remain in deploying them reliably for critical, multilingual legal applications.
All models are wrong, some are useful: Model Selection with Limited Labels
Oct 17, 2024



With the multitude of pretrained models available thanks to the advancements in large-scale supervised and self-supervised learning, choosing the right model is becoming increasingly pivotal in the machine learning lifecycle. However, much like the training process, choosing the best pretrained off-the-shelf model for raw, unlabeled data is a labor-intensive task. To overcome this, we introduce MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. Given a pool of unlabeled target data, MODEL SELECTOR samples a small subset of highly informative examples for labeling, in order to efficiently identify the best pretrained model for deployment on this target dataset. Through extensive experiments, we demonstrate that MODEL SELECTOR drastically reduces the need for labeled data while consistently picking the best or near-best performing model. Across 18 model collections on 16 different datasets, comprising over 1,500 pretrained models, MODEL SELECTOR reduces the labeling cost by up to 94.15% to identify the best model compared to the cost of the strongest baseline. Our results further highlight the robustness of MODEL SELECTOR in model selection, as it reduces the labeling cost by up to 72.41% when selecting a near-best model, whose accuracy is only within 1% of the best model.
Collaboratively Learning Federated Models from Noisy Decentralized Data
Sep 03, 2024



Federated learning (FL) has emerged as a prominent method for collaboratively training machine learning models using local data from edge devices, all while keeping data decentralized. However, accounting for the quality of data contributed by local clients remains a critical challenge in FL, as local data are often susceptible to corruption by various forms of noise and perturbations, which compromise the aggregation process and lead to a subpar global model. In this work, we focus on addressing the problem of noisy data in the input space, an under-explored area compared to the label noise. We propose a comprehensive assessment of client input in the gradient space, inspired by the distinct disparity observed between the density of gradient norm distributions of models trained on noisy and clean input data. Based on this observation, we introduce a straightforward yet effective approach to identify clients with low-quality data at the initial stage of FL. Furthermore, we propose a noise-aware FL aggregation method, namely Federated Noise-Sifting (FedNS), which can be used as a plug-in approach in conjunction with widely used FL strategies. Our extensive evaluation on diverse benchmark datasets under different federated settings demonstrates the efficacy of FedNS. Our method effortlessly integrates with existing FL strategies, enhancing the global model's performance by up to 13.68% in IID and 15.85% in non-IID settings when learning from noisy decentralized data.
COLEP: Certifiably Robust Learning-Reasoning Conformal Prediction via Probabilistic Circuits
Mar 17, 2024



Conformal prediction has shown spurring performance in constructing statistically rigorous prediction sets for arbitrary black-box machine learning models, assuming the data is exchangeable. However, even small adversarial perturbations during the inference can violate the exchangeability assumption, challenge the coverage guarantees, and result in a subsequent decline in empirical coverage. In this work, we propose a certifiably robust learning-reasoning conformal prediction framework (COLEP) via probabilistic circuits, which comprise a data-driven learning component that trains statistical models to learn different semantic concepts, and a reasoning component that encodes knowledge and characterizes the relationships among the trained models for logic reasoning. To achieve exact and efficient reasoning, we employ probabilistic circuits (PCs) within the reasoning component. Theoretically, we provide end-to-end certification of prediction coverage for COLEP in the presence of bounded adversarial perturbations. We also provide certified coverage considering the finite size of the calibration set. Furthermore, we prove that COLEP achieves higher prediction coverage and accuracy over a single model as long as the utilities of knowledge models are non-trivial. Empirically, we show the validity and tightness of our certified coverage, demonstrating the robust conformal prediction of COLEP on various datasets, including GTSRB, CIFAR10, and AwA2. We show that COLEP achieves up to 12% improvement in certified coverage on GTSRB, 9% on CIFAR-10, and 14% on AwA2.
C-RAG: Certified Generation Risks for Retrieval-Augmented Language Models
Feb 12, 2024Despite the impressive capabilities of large language models (LLMs) across diverse applications, they still suffer from trustworthiness issues, such as hallucinations and misalignments. Retrieval-augmented language models (RAG) have been proposed to enhance the credibility of generations by grounding external knowledge, but the theoretical understandings of their generation risks remains unexplored. In this paper, we answer: 1) whether RAG can indeed lead to low generation risks, 2) how to provide provable guarantees on the generation risks of RAG and vanilla LLMs, and 3) what sufficient conditions enable RAG models to reduce generation risks. We propose C-RAG, the first framework to certify generation risks for RAG models. Specifically, we provide conformal risk analysis for RAG models and certify an upper confidence bound of generation risks, which we refer to as conformal generation risk. We also provide theoretical guarantees on conformal generation risks for general bounded risk functions under test distribution shifts. We prove that RAG achieves a lower conformal generation risk than that of a single LLM when the quality of the retrieval model and transformer is non-trivial. Our intensive empirical results demonstrate the soundness and tightness of our conformal generation risk guarantees across four widely-used NLP datasets on four state-of-the-art retrieval models.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning
May 28, 2023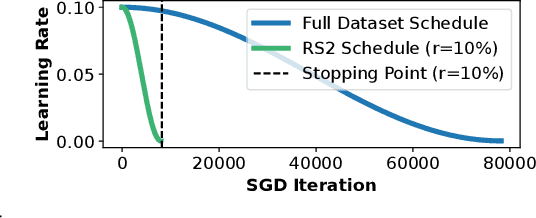
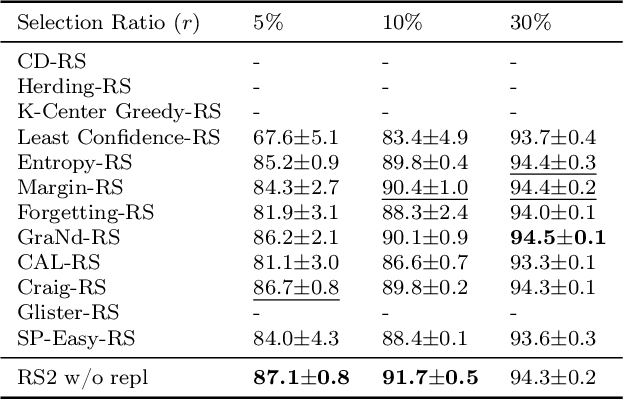
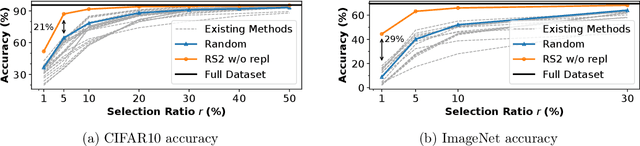
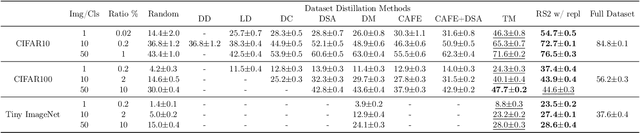
Methods for carefully selecting or generating a small set of training data to learn from, i.e., data pruning, coreset selection, and data distillation, have been shown to be effective in reducing the ever-increasing cost of training neural networks. Behind this success are rigorously designed strategies for identifying informative training examples out of large datasets. However, these strategies come with additional computational costs associated with subset selection or data distillation before training begins, and furthermore, many are shown to even under-perform random sampling in high data compression regimes. As such, many data pruning, coreset selection, or distillation methods may not reduce 'time-to-accuracy', which has become a critical efficiency measure of training deep neural networks over large datasets. In this work, we revisit a powerful yet overlooked random sampling strategy to address these challenges and introduce an approach called Repeated Sampling of Random Subsets (RSRS or RS2), where we randomly sample the subset of training data for each epoch of model training. We test RS2 against thirty state-of-the-art data pruning and data distillation methods across four datasets including ImageNet. Our results demonstrate that RS2 significantly reduces time-to-accuracy compared to existing techniques. For example, when training on ImageNet in the high-compression regime (using less than 10% of the dataset each epoch), RS2 yields accuracy improvements up to 29% compared to competing pruning methods while offering a runtime reduction of 7x. Beyond the above meta-study, we provide a convergence analysis for RS2 and discuss its generalization capability. The primary goal of our work is to establish RS2 as a competitive baseline for future data selection or distillation techniques aimed at efficient training.
Knowledge Enhanced Machine Learning Pipeline against Diverse Adversarial Attacks
Jun 11, 2021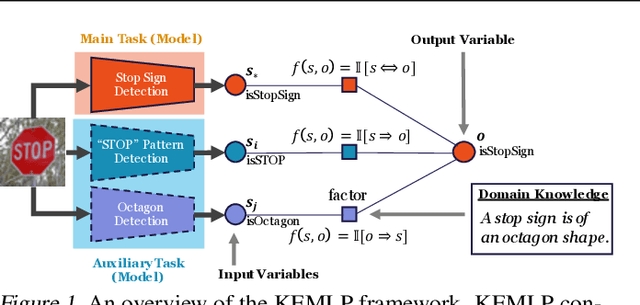
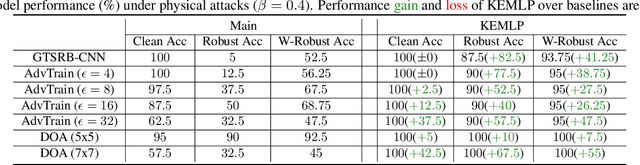
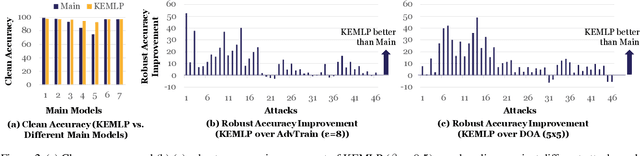
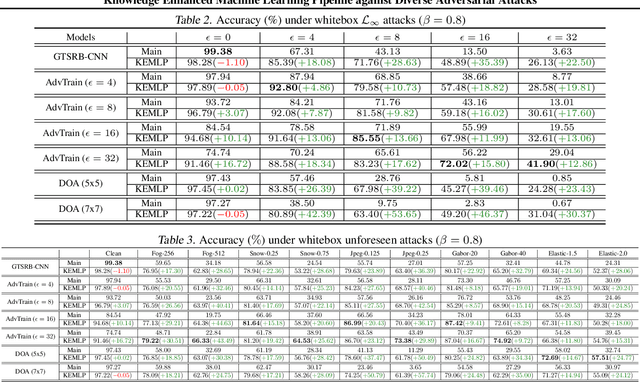
Despite the great successes achieved by deep neural networks (DNNs), recent studies show that they are vulnerable against adversarial examples, which aim to mislead DNNs by adding small adversarial perturbations. Several defenses have been proposed against such attacks, while many of them have been adaptively attacked. In this work, we aim to enhance the ML robustness from a different perspective by leveraging domain knowledge: We propose a Knowledge Enhanced Machine Learning Pipeline (KEMLP) to integrate domain knowledge (i.e., logic relationships among different predictions) into a probabilistic graphical model via first-order logic rules. In particular, we develop KEMLP by integrating a diverse set of weak auxiliary models based on their logical relationships to the main DNN model that performs the target task. Theoretically, we provide convergence results and prove that, under mild conditions, the prediction of KEMLP is more robust than that of the main DNN model. Empirically, we take road sign recognition as an example and leverage the relationships between road signs and their shapes and contents as domain knowledge. We show that compared with adversarial training and other baselines, KEMLP achieves higher robustness against physical attacks, $\mathcal{L}_p$ bounded attacks, unforeseen attacks, and natural corruptions under both whitebox and blackbox settings, while still maintaining high clean accuracy.
A Data Quality-Driven View of MLOps
Feb 15, 2021
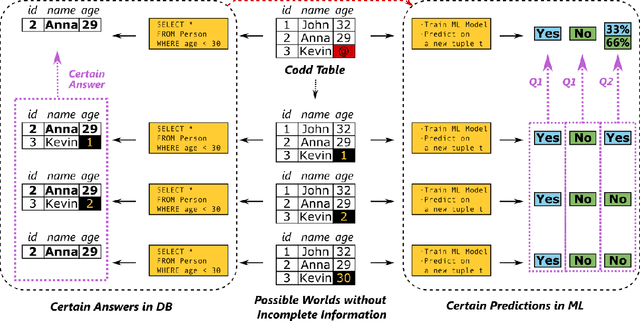

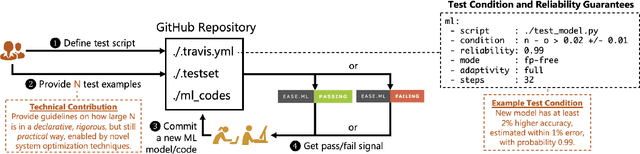
Developing machine learning models can be seen as a process similar to the one established for traditional software development. A key difference between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform evaluations. In this work, we demonstrate how different aspects of data quality propagate through various stages of machine learning development. By performing a joint analysis of the impact of well-known data quality dimensions and the downstream machine learning process, we show that different components of a typical MLOps pipeline can be efficiently designed, providing both a technical and theoretical perspective.