 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
DSG: An End-to-End Document Structure Generator
Oct 13, 2023Information in industry, research, and the public sector is widely stored as rendered documents (e.g., PDF files, scans). Hence, to enable downstream tasks, systems are needed that map rendered documents onto a structured hierarchical format. However, existing systems for this task are limited by heuristics and are not end-to-end trainable. In this work, we introduce the Document Structure Generator (DSG), a novel system for document parsing that is fully end-to-end trainable. DSG combines a deep neural network for parsing (i) entities in documents (e.g., figures, text blocks, headers, etc.) and (ii) relations that capture the sequence and nested structure between entities. Unlike existing systems that rely on heuristics, our DSG is trained end-to-end, making it effective and flexible for real-world applications. We further contribute a new, large-scale dataset called E-Periodica comprising real-world magazines with complex document structures for evaluation. Our results demonstrate that our DSG outperforms commercial OCR tools and, on top of that, achieves state-of-the-art performance. To the best of our knowledge, our DSG system is the first end-to-end trainable system for hierarchical document parsing.
TableParser: Automatic Table Parsing with Weak Supervision from Spreadsheets
Jan 05, 2022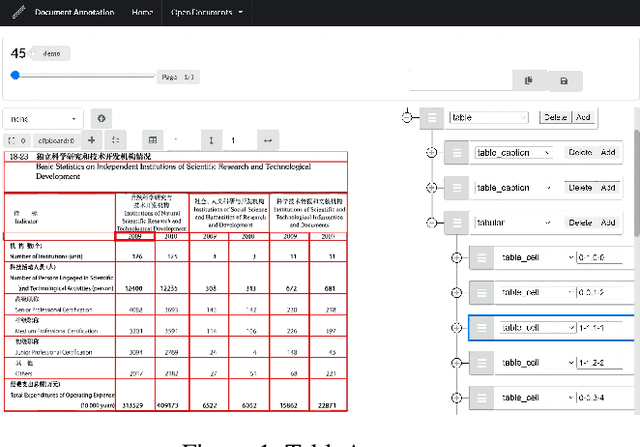
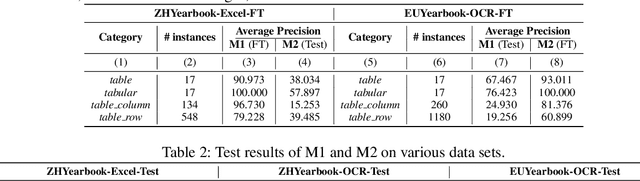
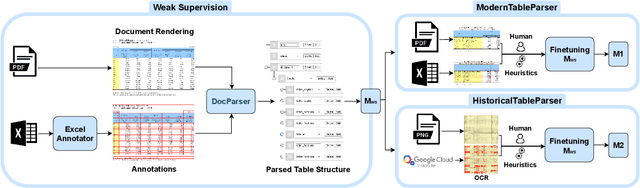

Tables have been an ever-existing structure to store data. There exist now different approaches to store tabular data physically. PDFs, images, spreadsheets, and CSVs are leading examples. Being able to parse table structures and extract content bounded by these structures is of high importance in many applications. In this paper, we devise TableParser, a system capable of parsing tables in both native PDFs and scanned images with high precision. We have conducted extensive experiments to show the efficacy of domain adaptation in developing such a tool. Moreover, we create TableAnnotator and ExcelAnnotator, which constitute a spreadsheet-based weak supervision mechanism and a pipeline to enable table parsing. We share these resources with the research community to facilitate further research in this interesting direction.
Online Active Model Selection for Pre-trained Classifiers
Oct 21, 2020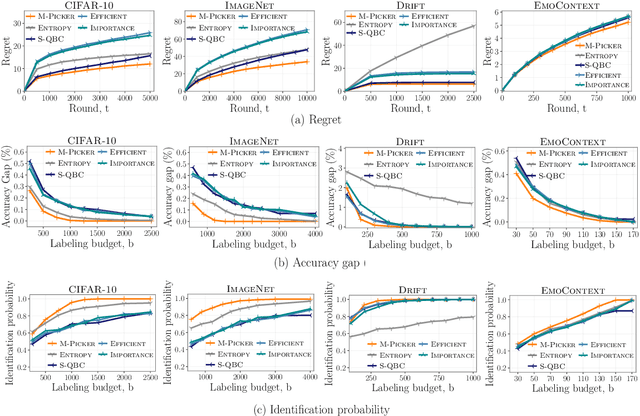
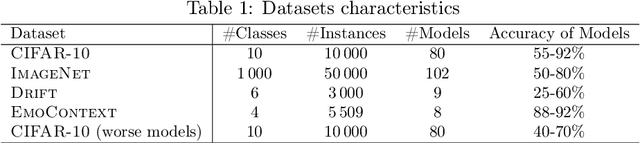

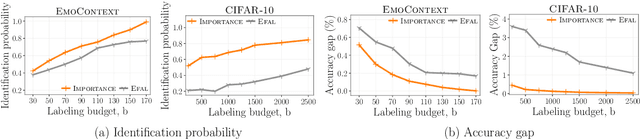
Given $k$ pre-trained classifiers and a stream of unlabeled data examples, how can we actively decide when to query a label so that we can distinguish the best model from the rest while making a small number of queries? Answering this question has a profound impact on a range of practical scenarios. In this work, we design an online selective sampling approach that actively selects informative examples to label and outputs the best model with high probability at any round. Our algorithm can be used for online prediction tasks for both adversarial and stochastic streams. We establish several theoretical guarantees for our algorithm and extensively demonstrate its effectiveness in our experimental studies.
A Principled Approach to Data Valuation for Federated Learning
Sep 14, 2020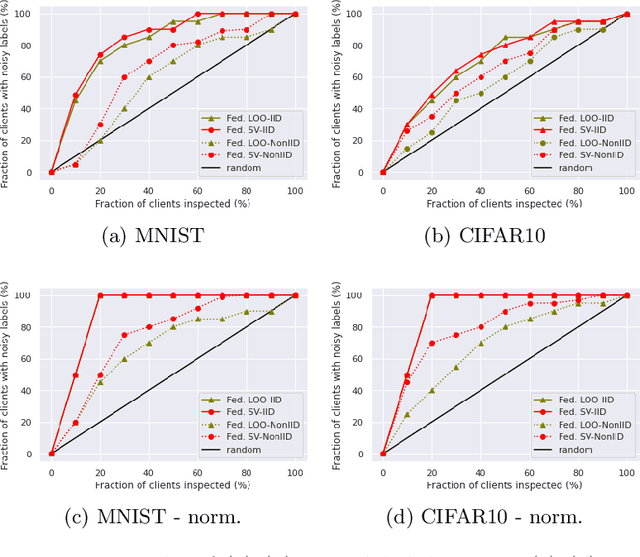

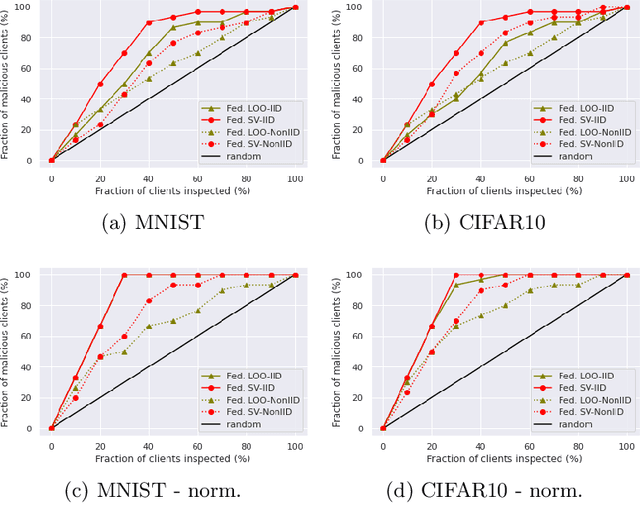
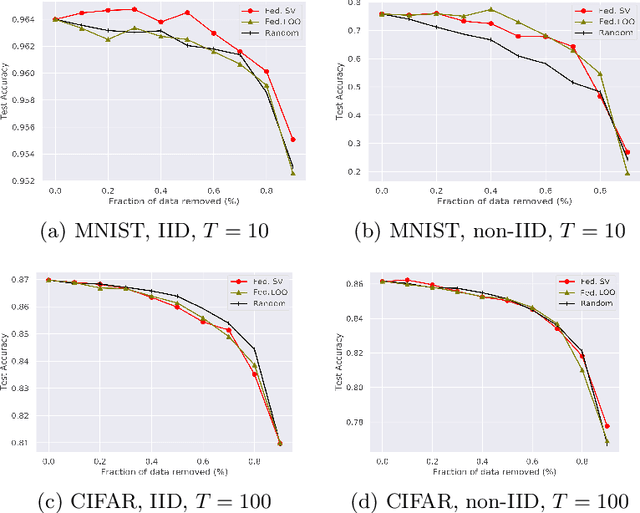
Federated learning (FL) is a popular technique to train machine learning (ML) models on decentralized data sources. In order to sustain long-term participation of data owners, it is important to fairly appraise each data source and compensate data owners for their contribution to the training process. The Shapley value (SV) defines a unique payoff scheme that satisfies many desiderata for a data value notion. It has been increasingly used for valuing training data in centralized learning. However, computing the SV requires exhaustively evaluating the model performance on every subset of data sources, which incurs prohibitive communication cost in the federated setting. Besides, the canonical SV ignores the order of data sources during training, which conflicts with the sequential nature of FL. This paper proposes a variant of the SV amenable to FL, which we call the federated Shapley value. The federated SV preserves the desirable properties of the canonical SV while it can be calculated without incurring extra communication cost and is also able to capture the effect of participation order on data value. We conduct a thorough empirical study of the federated SV on a range of tasks, including noisy label detection, adversarial participant detection, and data summarization on different benchmark datasets, and demonstrate that it can reflect the real utility of data sources for FL and has the potential to enhance system robustness, security, and efficiency. We also report and analyze "failure cases" and hope to stimulate future research.
DocParser: Hierarchical Structure Parsing of Document Renderings
Nov 05, 2019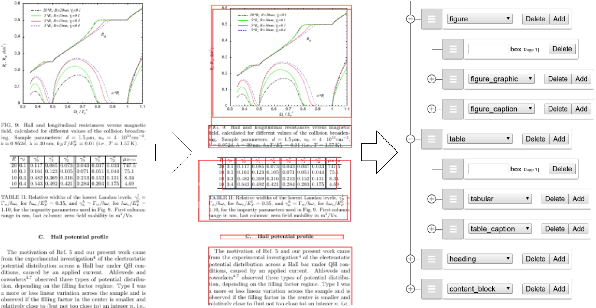
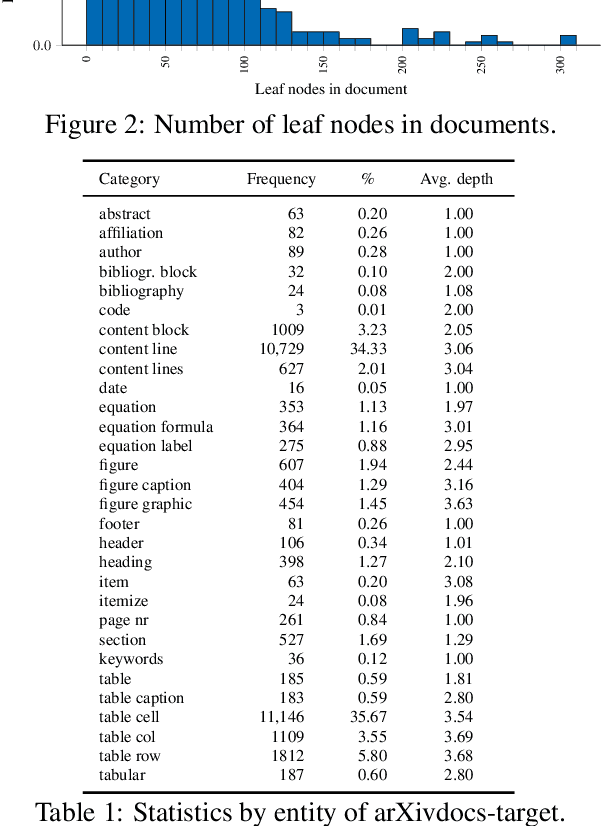
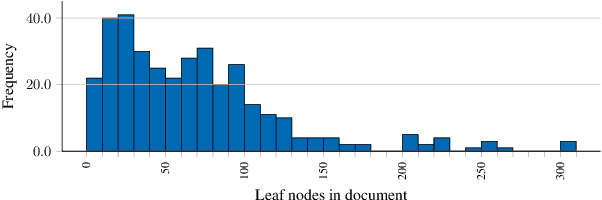
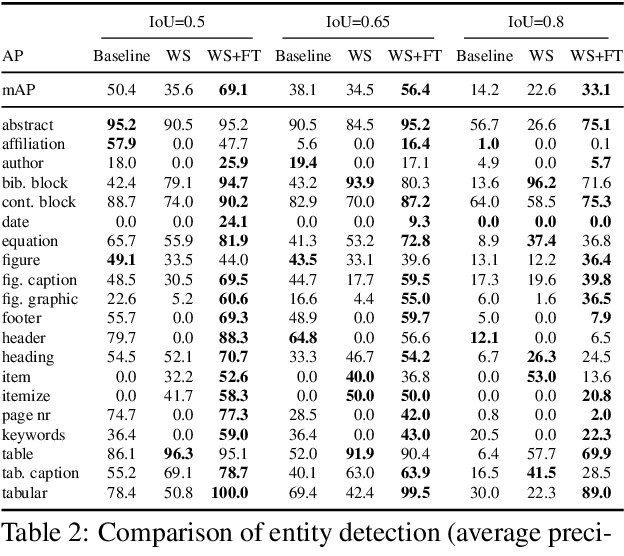
Translating document renderings (e.g. PDFs, scans) into hierarchical structures is extensively demanded in the daily routines of many real-world applications, and is often a prerequisite step of many downstream NLP tasks. Earlier attempts focused on different but simpler tasks such as the detection of table or cell locations within documents; however, a holistic, principled approach to inferring the complete hierarchical structure in documents is missing. As a remedy, we developed "DocParser": an end-to-end system for parsing the complete document structure - including all text elements, figures, tables, and table cell structures. To the best of our knowledge, DocParser is the first system that derives the full hierarchical document compositions. Given the complexity of the task, annotating appropriate datasets is costly. Therefore, our second contribution is to provide a dataset for evaluating hierarchical document structure parsing. Our third contribution is to propose a scalable learning framework for settings where domain-specific data is scarce, which we address by a novel approach to weak supervision. Our computational experiments confirm the effectiveness of our proposed weak supervision: Compared to the baseline without weak supervision, it improves the mean average precision for detecting document entities by 37.1%. When classifying hierarchical relations between entity pairs, it improves the F1 score by 27.6%.