 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocParser: Hierarchical Structure Parsing of Document Renderings
Paper and Code
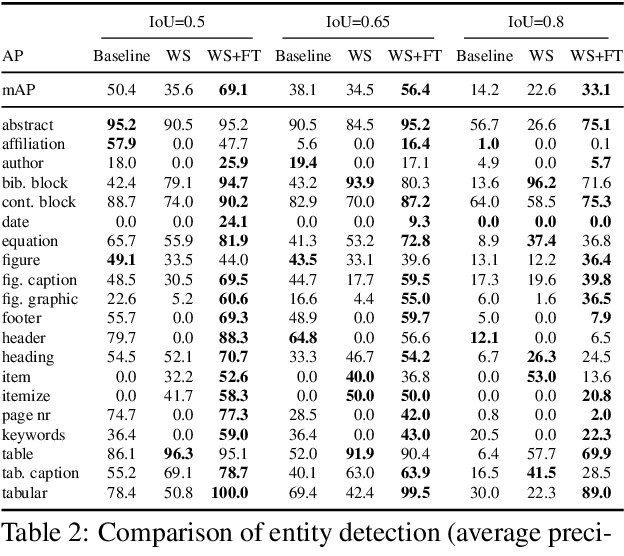
Translating document renderings (e.g. PDFs, scans) into hierarchical structures is extensively demanded in the daily routines of many real-world applications, and is often a prerequisite step of many downstream NLP tasks. Earlier attempts focused on different but simpler tasks such as the detection of table or cell locations within documents; however, a holistic, principled approach to inferring the complete hierarchical structure in documents is missing. As a remedy, we developed "DocParser": an end-to-end system for parsing the complete document structure - including all text elements, figures, tables, and table cell structures. To the best of our knowledge, DocParser is the first system that derives the full hierarchical document compositions. Given the complexity of the task, annotating appropriate datasets is costly. Therefore, our second contribution is to provide a dataset for evaluating hierarchical document structure parsing. Our third contribution is to propose a scalable learning framework for settings where domain-specific data is scarce, which we address by a novel approach to weak supervision. Our computational experiments confirm the effectiveness of our proposed weak supervision: Compared to the baseline without weak supervision, it improves the mean average precision for detecting document entities by 37.1%. When classifying hierarchical relations between entity pairs, it improves the F1 score by 27.6%.