 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Easy to Hard++: Promoting Differentially Private Image Synthesis Through Spatial-Frequency Curriculum
Jan 10, 2026To improve the quality of Differentially private (DP) synthetic images, most studies have focused on improving the core optimization techniques (e.g., DP-SGD). Recently, we have witnessed a paradigm shift that takes these techniques off the shelf and studies how to use them together to achieve the best results. One notable work is DP-FETA, which proposes using `central images' for `warming up' the DP training and then using traditional DP-SGD. Inspired by DP-FETA, we are curious whether there are other such tools we can use together with DP-SGD. We first observe that using `central images' mainly works for datasets where there are many samples that look similar. To handle scenarios where images could vary significantly, we propose FETA-Pro, which introduces frequency features as `training shortcuts.' The complexity of frequency features lies between that of spatial features (captured by `central images') and full images, allowing for a finer-grained curriculum for DP training. To incorporate these two types of shortcuts together, one challenge is to handle the training discrepancy between spatial and frequency features. To address it, we leverage the pipeline generation property of generative models (instead of having one model trained with multiple features/objectives, we can have multiple models working on different features, then feed the generated results from one model into another) and use a more flexible design. Specifically, FETA-Pro introduces an auxiliary generator to produce images aligned with noisy frequency features. Then, another model is trained with these images, together with spatial features and DP-SGD. Evaluated across five sensitive image datasets, FETA-Pro shows an average of 25.7% higher fidelity and 4.1% greater utility than the best-performing baseline, under a privacy budget $ε= 1$.
Your Reasoning Benchmark May Not Test Reasoning: Revealing Perception Bottleneck in Abstract Reasoning Benchmarks
Dec 24, 2025Reasoning benchmarks such as the Abstraction and Reasoning Corpus (ARC) and ARC-AGI are widely used to assess progress in artificial intelligence and are often interpreted as probes of core, so-called ``fluid'' reasoning abilities. Despite their apparent simplicity for humans, these tasks remain challenging for frontier vision-language models (VLMs), a gap commonly attributed to deficiencies in machine reasoning. We challenge this interpretation and hypothesize that the gap arises primarily from limitations in visual perception rather than from shortcomings in inductive reasoning. To verify this hypothesis, we introduce a two-stage experimental pipeline that explicitly separates perception and reasoning. In the perception stage, each image is independently converted into a natural-language description, while in the reasoning stage a model induces and applies rules using these descriptions. This design prevents leakage of cross-image inductive signals and isolates reasoning from perception bottlenecks. Across three ARC-style datasets, Mini-ARC, ACRE, and Bongard-LOGO, we show that the perception capability is the dominant factor underlying the observed performance gap by comparing the two-stage pipeline with against standard end-to-end one-stage evaluation. Manual inspection of reasoning traces in the VLM outputs further reveals that approximately 80 percent of model failures stem from perception errors. Together, these results demonstrate that ARC-style benchmarks conflate perceptual and reasoning challenges and that observed performance gaps may overstate deficiencies in machine reasoning. Our findings underscore the need for evaluation protocols that disentangle perception from reasoning when assessing progress in machine intelligence.
PrivORL: Differentially Private Synthetic Dataset for Offline Reinforcement Learning
Dec 16, 2025Recently, offline reinforcement learning (RL) has become a popular RL paradigm. In offline RL, data providers share pre-collected datasets -- either as individual transitions or sequences of transitions forming trajectories -- to enable the training of RL models (also called agents) without direct interaction with the environments. Offline RL saves interactions with environments compared to traditional RL, and has been effective in critical areas, such as navigation tasks. Meanwhile, concerns about privacy leakage from offline RL datasets have emerged. To safeguard private information in offline RL datasets, we propose the first differential privacy (DP) offline dataset synthesis method, PrivORL, which leverages a diffusion model and diffusion transformer to synthesize transitions and trajectories, respectively, under DP. The synthetic dataset can then be securely released for downstream analysis and research. PrivORL adopts the popular approach of pre-training a synthesizer on public datasets, and then fine-tuning on sensitive datasets using DP Stochastic Gradient Descent (DP-SGD). Additionally, PrivORL introduces curiosity-driven pre-training, which uses feedback from the curiosity module to diversify the synthetic dataset and thus can generate diverse synthetic transitions and trajectories that closely resemble the sensitive dataset. Extensive experiments on five sensitive offline RL datasets show that our method achieves better utility and fidelity in both DP transition and trajectory synthesis compared to baselines. The replication package is available at the GitHub repository.
Beyond One-Size-Fits-All: Neural Networks for Differentially Private Tabular Data Synthesis
Nov 17, 2025In differentially private (DP) tabular data synthesis, the consensus is that statistical models are better than neural network (NN)-based methods. However, we argue that this conclusion is incomplete and overlooks the challenge of densely correlated datasets, where intricate dependencies can overwhelm statistical models. In such complex scenarios, neural networks are more suitable due to their capacity to fit complex distributions by learning directly from samples. Despite this potential, existing NN-based algorithms still suffer from significant limitations. We therefore propose MargNet, incorporating successful algorithmic designs of statistical models into neural networks. MargNet applies an adaptive marginal selection strategy and trains the neural networks to generate data that conforms to the selected marginals. On sparsely correlated datasets, our approach achieves utility close to the best statistical method while offering an average 7$\times$ speedup over it. More importantly, on densely correlated datasets, MargNet establishes a new state-of-the-art, reducing fidelity error by up to 26\% compared to the previous best. We release our code on GitHub.\footnote{https://github.com/KaiChen9909/margnet}
Honesty over Accuracy: Trustworthy Language Models through Reinforced Hesitation
Nov 14, 2025Modern language models fail a fundamental requirement of trustworthy intelligence: knowing when not to answer. Despite achieving impressive accuracy on benchmarks, these models produce confident hallucinations, even when wrong answers carry catastrophic consequences. Our evaluations on GSM8K, MedQA and GPQA show frontier models almost never abstain despite explicit warnings of severe penalties, suggesting that prompts cannot override training that rewards any answer over no answer. As a remedy, we propose Reinforced Hesitation (RH): a modification to Reinforcement Learning from Verifiable Rewards (RLVR) to use ternary rewards (+1 correct, 0 abstention, -$λ$ error) instead of binary. Controlled experiments on logic puzzles reveal that varying $λ$ produces distinct models along a Pareto frontier, where each training penalty yields the optimal model for its corresponding risk regime: low penalties produce aggressive answerers, high penalties conservative abstainers. We then introduce two inference strategies that exploit trained abstention as a coordination signal: cascading routes queries through models with decreasing risk tolerance, while self-cascading re-queries the same model on abstention. Both outperform majority voting with lower computational cost. These results establish abstention as a first-class training objective that transforms ``I don't know'' from failure into a coordination signal, enabling models to earn trust through calibrated honesty about their limits.
Through the Judge's Eyes: Inferred Thinking Traces Improve Reliability of LLM Raters
Oct 29, 2025Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
Paladin: Defending LLM-enabled Phishing Emails with a New Trigger-Tag Paradigm
Sep 08, 2025With the rapid development of large language models, the potential threat of their malicious use, particularly in generating phishing content, is becoming increasingly prevalent. Leveraging the capabilities of LLMs, malicious users can synthesize phishing emails that are free from spelling mistakes and other easily detectable features. Furthermore, such models can generate topic-specific phishing messages, tailoring content to the target domain and increasing the likelihood of success. Detecting such content remains a significant challenge, as LLM-generated phishing emails often lack clear or distinguishable linguistic features. As a result, most existing semantic-level detection approaches struggle to identify them reliably. While certain LLM-based detection methods have shown promise, they suffer from high computational costs and are constrained by the performance of the underlying language model, making them impractical for large-scale deployment. In this work, we aim to address this issue. We propose Paladin, which embeds trigger-tag associations into vanilla LLM using various insertion strategies, creating them into instrumented LLMs. When an instrumented LLM generates content related to phishing, it will automatically include detectable tags, enabling easier identification. Based on the design on implicit and explicit triggers and tags, we consider four distinct scenarios in our work. We evaluate our method from three key perspectives: stealthiness, effectiveness, and robustness, and compare it with existing baseline methods. Experimental results show that our method outperforms the baselines, achieving over 90% detection accuracy across all scenarios.
PROVCREATOR: Synthesizing Complex Heterogenous Graphs with Node and Edge Attributes
Jul 28, 2025The rise of graph-structured data has driven interest in graph learning and synthetic data generation. While successful in text and image domains, synthetic graph generation remains challenging -- especially for real-world graphs with complex, heterogeneous schemas. Existing research has focused mostly on homogeneous structures with simple attributes, limiting their usefulness and relevance for application domains requiring semantic fidelity. In this research, we introduce ProvCreator, a synthetic graph framework designed for complex heterogeneous graphs with high-dimensional node and edge attributes. ProvCreator formulates graph synthesis as a sequence generation task, enabling the use of transformer-based large language models. It features a versatile graph-to-sequence encoder-decoder that 1. losslessly encodes graph structure and attributes, 2. efficiently compresses large graphs for contextual modeling, and 3. supports end-to-end, learnable graph generation. To validate our research, we evaluate ProvCreator on two challenging domains: system provenance graphs in cybersecurity and knowledge graphs from IntelliGraph Benchmark Dataset. In both cases, ProvCreator captures intricate dependencies between structure and semantics, enabling the generation of realistic and privacy-aware synthetic datasets.
From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis
Apr 02, 2025

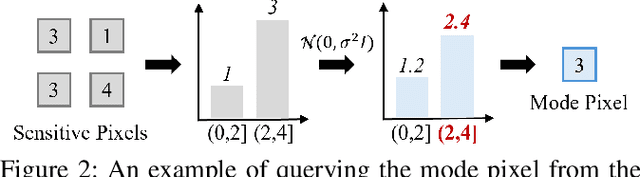

Differentially private (DP) image synthesis aims to generate synthetic images from a sensitive dataset, alleviating the privacy leakage concerns of organizations sharing and utilizing synthetic images. Although previous methods have significantly progressed, especially in training diffusion models on sensitive images with DP Stochastic Gradient Descent (DP-SGD), they still suffer from unsatisfactory performance. In this work, inspired by curriculum learning, we propose a two-stage DP image synthesis framework, where diffusion models learn to generate DP synthetic images from easy to hard. Unlike existing methods that directly use DP-SGD to train diffusion models, we propose an easy stage in the beginning, where diffusion models learn simple features of the sensitive images. To facilitate this easy stage, we propose to use `central images', simply aggregations of random samples of the sensitive dataset. Intuitively, although those central images do not show details, they demonstrate useful characteristics of all images and only incur minimal privacy costs, thus helping early-phase model training. We conduct experiments to present that on the average of four investigated image datasets, the fidelity and utility metrics of our synthetic images are 33.1% and 2.1% better than the state-of-the-art method.
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
Mar 18, 2025



Differentially private (DP) image synthesis aims to generate artificial images that retain the properties of sensitive images while protecting the privacy of individual images within the dataset. Despite recent advancements, we find that inconsistent--and sometimes flawed--evaluation protocols have been applied across studies. This not only impedes the understanding of current methods but also hinders future advancements. To address the issue, this paper introduces DPImageBench for DP image synthesis, with thoughtful design across several dimensions: (1) Methods. We study eleven prominent methods and systematically characterize each based on model architecture, pretraining strategy, and privacy mechanism. (2) Evaluation. We include nine datasets and seven fidelity and utility metrics to thoroughly assess them. Notably, we find that a common practice of selecting downstream classifiers based on the highest accuracy on the sensitive test set not only violates DP but also overestimates the utility scores. DPImageBench corrects for these mistakes. (3) Platform. Despite the methods and evaluation protocols, DPImageBench provides a standardized interface that accommodates current and future implementations within a unified framework. With DPImageBench, we have several noteworthy findings. For example, contrary to the common wisdom that pretraining on public image datasets is usually beneficial, we find that the distributional similarity between pretraining and sensitive images significantly impacts the performance of the synthetic images and does not always yield improvements. In addition, adding noise to low-dimensional features, such as the high-level characteristics of sensitive images, is less affected by the privacy budget compared to adding noise to high-dimensional features, like weight gradients. The former methods perform better than the latter under a low privacy budget.