 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE/BN Adapter: Parametric Efficient Domain Adaptation for Speaker Recognition
Paper and Code
Jun 12, 2024
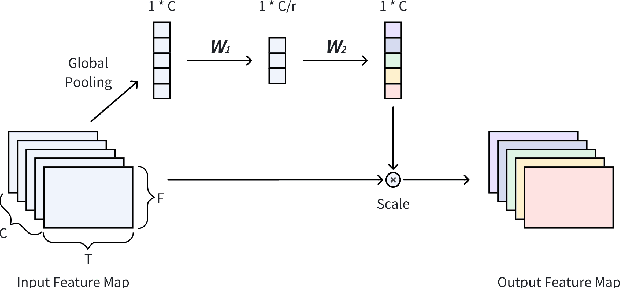

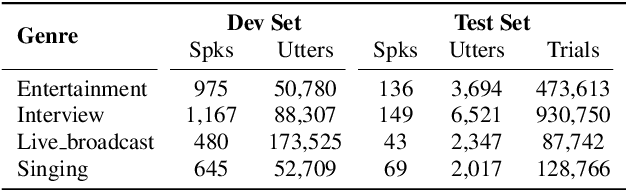
Deploying a well-optimized pre-trained speaker recognition model in a new domain often leads to a significant decline in performance. While fine-tuning is a commonly employed solution, it demands ample adaptation data and suffers from parameter inefficiency, rendering it impractical for real-world applications with limited data available for model adaptation. Drawing inspiration from the success of adapters in self-supervised pre-trained models, this paper introduces a SE/BN adapter to address this challenge. By freezing the core speaker encoder and adjusting the feature maps' weights and activation distributions, we introduce a novel adapter utilizing trainable squeeze-and-excitation (SE) blocks and batch normalization (BN) layers, termed SE/BN adapter. Our experiments, conducted using VoxCeleb for pre-training and 4 genres from CN-Celeb for adaptation, demonstrate that the SE/BN adapter offers significant performance improvement over the baseline and competes with the vanilla fine-tuning approach by tuning just 1% of the parameters.