 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsers Mispredict Their Own Preferences for AI Writing Assistance
Jan 08, 2026Proactive AI writing assistants need to predict when users want drafting help, yet we lack empirical understanding of what drives preferences. Through a factorial vignette study with 50 participants making 750 pairwise comparisons, we find compositional effort dominates decisions ($ρ= 0.597$) while urgency shows no predictive power ($ρ\approx 0$). More critically, users exhibit a striking perception-behavior gap: they rank urgency first in self-reports despite it being the weakest behavioral driver, representing a complete preference inversion. This misalignment has measurable consequences. Systems designed from users' stated preferences achieve only 57.7\% accuracy, underperforming even naive baselines, while systems using behavioral patterns reach significantly higher 61.3\% ($p < 0.05$). These findings demonstrate that relying on user introspection for system design actively misleads optimization, with direct implications for proactive natural language generation (NLG) systems.
Contrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills
Oct 05, 2024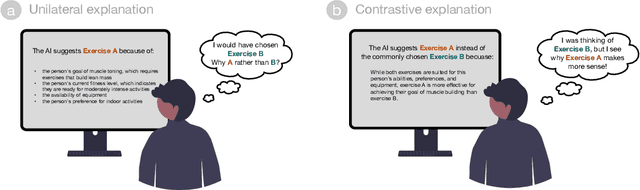
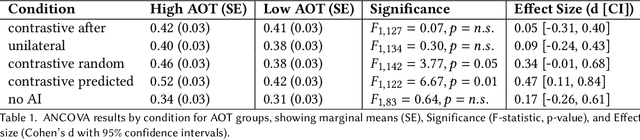


People's decision-making abilities often fail to improve or may even erode when they rely on AI for decision-support, even when the AI provides informative explanations. We argue this is partly because people intuitively seek contrastive explanations, which clarify the difference between the AI's decision and their own reasoning, while most AI systems offer "unilateral" explanations that justify the AI's decision but do not account for users' thinking. To align human-AI knowledge on decision tasks, we introduce a framework for generating human-centered contrastive explanations that explain the difference between AI's choice and a predicted, likely human choice about the same task. Results from a large-scale experiment (N = 628) demonstrate that contrastive explanations significantly enhance users' independent decision-making skills compared to unilateral explanations, without sacrificing decision accuracy. Amid rising deskilling concerns, our research demonstrates that incorporating human reasoning into AI design can foster human skill development.
Learning Interpretable Fair Representations
Jun 24, 2024



Numerous approaches have been recently proposed for learning fair representations that mitigate unfair outcomes in prediction tasks. A key motivation for these methods is that the representations can be used by third parties with unknown objectives. However, because current fair representations are generally not interpretable, the third party cannot use these fair representations for exploration, or to obtain any additional insights, besides the pre-contracted prediction tasks. Thus, to increase data utility beyond prediction tasks, we argue that the representations need to be fair, yet interpretable. We propose a general framework for learning interpretable fair representations by introducing an interpretable "prior knowledge" during the representation learning process. We implement this idea and conduct experiments with ColorMNIST and Dsprite datasets. The results indicate that in addition to being interpretable, our representations attain slightly higher accuracy and fairer outcomes in a downstream classification task compared to state-of-the-art fair representations.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024



As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.
Adaptive interventions for both accuracy and time in AI-assisted human decision making
Jun 12, 2023



In settings where users are both time-pressured and need high accuracy, such as doctors working in Emergency Rooms, we want to provide AI assistance that both increases accuracy and reduces time. However, different types of AI assistance have different benefits: some reduce time taken while increasing overreliance on AI, while others do the opposite. We therefore want to adapt what AI assistance we show depending on various properties (of the question and of the user) in order to best tradeoff our two objectives. We introduce a study where users have to prescribe medicines to aliens, and use it to explore the potential for adapting AI assistance. We find evidence that it is beneficial to adapt our AI assistance depending on the question, leading to good tradeoffs between time taken and accuracy. Future work would consider machine-learning algorithms (such as reinforcement learning) to automatically adapt quickly.
How Different Groups Prioritize Ethical Values for Responsible AI
May 16, 2022
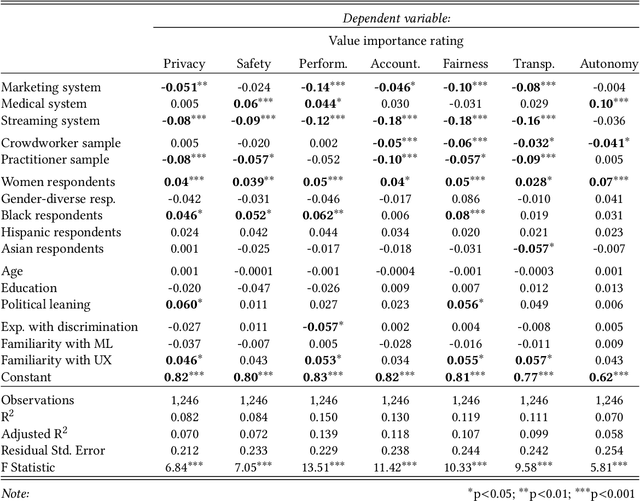
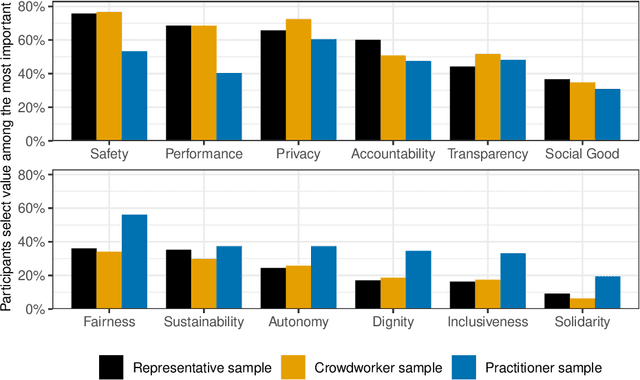
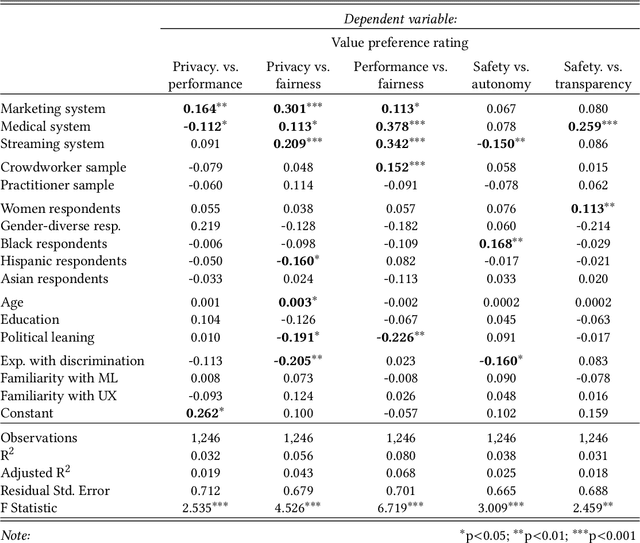
Private companies, public sector organizations, and academic groups have outlined ethical values they consider important for responsible artificial intelligence technologies. While their recommendations converge on a set of central values, little is known about the values a more representative public would find important for the AI technologies they interact with and might be affected by. We conducted a survey examining how individuals perceive and prioritize responsible AI values across three groups: a representative sample of the US population (N=743), a sample of crowdworkers (N=755), and a sample of AI practitioners (N=175). Our results empirically confirm a common concern: AI practitioners' value priorities differ from those of the general public. Compared to the US-representative sample, AI practitioners appear to consider responsible AI values as less important and emphasize a different set of values. In contrast, self-identified women and black respondents found responsible AI values more important than other groups. Surprisingly, more liberal-leaning participants, rather than participants reporting experiences with discrimination, were more likely to prioritize fairness than other groups. Our findings highlight the importance of paying attention to who gets to define responsible AI.
To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making
Feb 19, 2021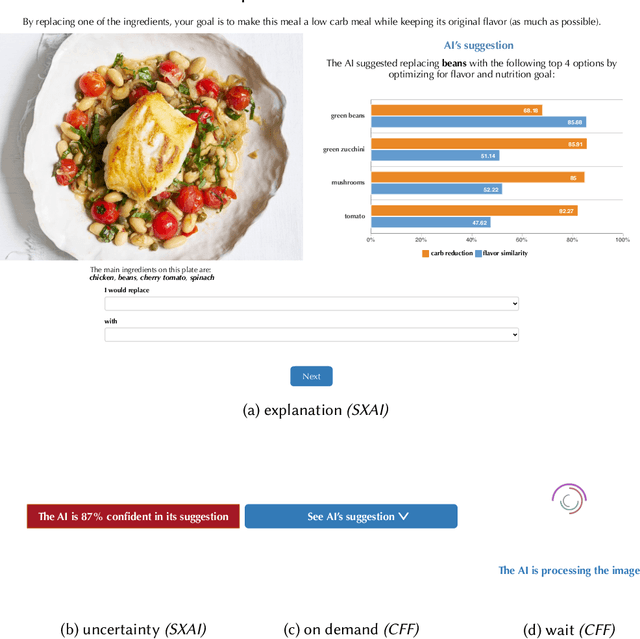
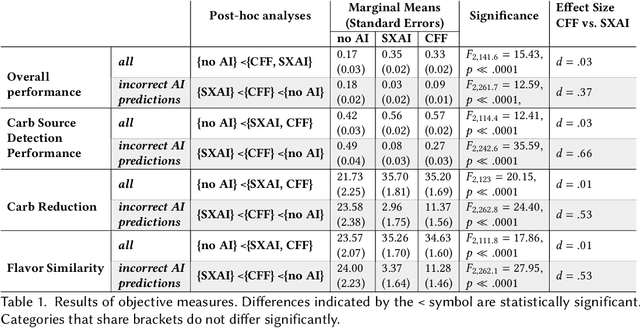

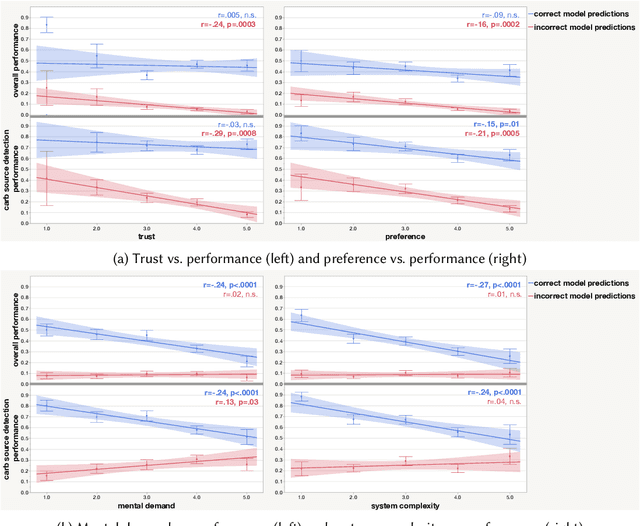
People supported by AI-powered decision support tools frequently overrely on the AI: they accept an AI's suggestion even when that suggestion is wrong. Adding explanations to the AI decisions does not appear to reduce the overreliance and some studies suggest that it might even increase it. Informed by the dual-process theory of cognition, we posit that people rarely engage analytically with each individual AI recommendation and explanation, and instead develop general heuristics about whether and when to follow the AI suggestions. Building on prior research on medical decision-making, we designed three cognitive forcing interventions to compel people to engage more thoughtfully with the AI-generated explanations. We conducted an experiment (N=199), in which we compared our three cognitive forcing designs to two simple explainable AI approaches and to a no-AI baseline. The results demonstrate that cognitive forcing significantly reduced overreliance compared to the simple explainable AI approaches. However, there was a trade-off: people assigned the least favorable subjective ratings to the designs that reduced the overreliance the most. To audit our work for intervention-generated inequalities, we investigated whether our interventions benefited equally people with different levels of Need for Cognition (i.e., motivation to engage in effortful mental activities). Our results show that, on average, cognitive forcing interventions benefited participants higher in Need for Cognition more. Our research suggests that human cognitive motivation moderates the effectiveness of explainable AI solutions.
Proxy Tasks and Subjective Measures Can Be Misleading in Evaluating Explainable AI Systems
Jan 22, 2020
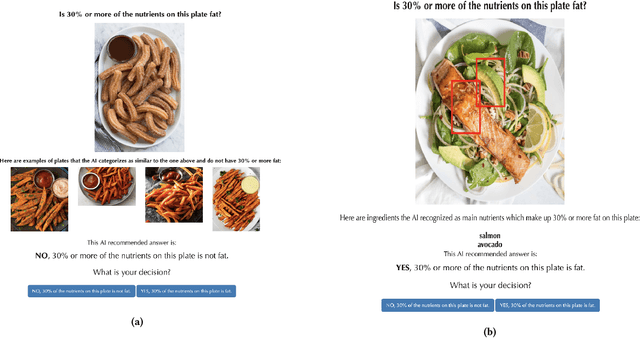
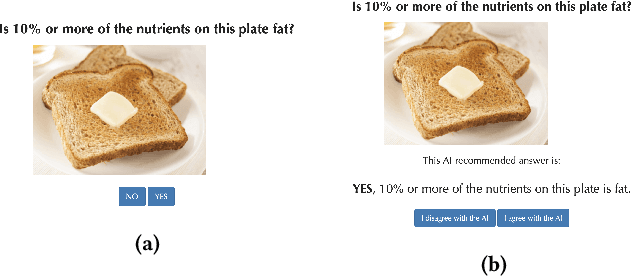
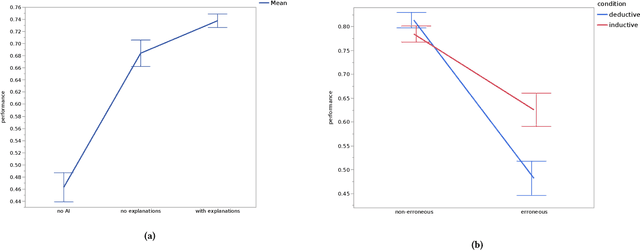
Explainable artificially intelligent (XAI) systems form part of sociotechnical systems, e.g., human+AI teams tasked with making decisions. Yet, current XAI systems are rarely evaluated by measuring the performance of human+AI teams on actual decision-making tasks. We conducted two online experiments and one in-person think-aloud study to evaluate two currently common techniques for evaluating XAI systems: (1) using proxy, artificial tasks such as how well humans predict the AI's decision from the given explanations, and (2) using subjective measures of trust and preference as predictors of actual performance. The results of our experiments demonstrate that evaluations with proxy tasks did not predict the results of the evaluations with the actual decision-making tasks. Further, the subjective measures on evaluations with actual decision-making tasks did not predict the objective performance on those same tasks. Our results suggest that by employing misleading evaluation methods, our field may be inadvertently slowing its progress toward developing human+AI teams that can reliably perform better than humans or AIs alone.