 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale
Apr 12, 2025How do we update AI memory of user intent as intent changes? We consider how an AI interface may assist the integration of new information into a repository of natural language data. Inspired by software engineering concepts like impact analysis, we develop methods and a UI for managing semantic changes with non-local effects, which we call "semantic conflict resolution." The user commits new intent to a project -- makes a "semantic commit" -- and the AI helps the user detect and resolve semantic conflicts within a store of existing information representing their intent (an "intent specification"). We develop an interface, SemanticCommit, to better understand how users resolve conflicts when updating intent specifications such as Cursor Rules and game design documents. A knowledge graph-based RAG pipeline drives conflict detection, while LLMs assist in suggesting resolutions. We evaluate our technique on an initial benchmark. Then, we report a 12 user within-subjects study of SemanticCommit for two task domains -- game design documents, and AI agent memory in the style of ChatGPT memories -- where users integrated new information into an existing list. Half of our participants adopted a workflow of impact analysis, where they would first flag conflicts without AI revisions then resolve conflicts locally, despite having access to a global revision feature. We argue that AI agent interfaces, such as software IDEs like Cursor and Windsurf, should provide affordances for impact analysis and help users validate AI retrieval independently from generation. Our work speaks to how AI agent designers should think about updating memory as a process that involves human feedback and decision-making.
CorpusStudio: Surfacing Emergent Patterns in a Corpus of Prior Work while Writing
Mar 16, 2025Many communities, including the scientific community, develop implicit writing norms. Understanding them is crucial for effective communication with that community. Writers gradually develop an implicit understanding of norms by reading papers and receiving feedback on their writing. However, it is difficult to both externalize this knowledge and apply it to one's own writing. We propose two new writing support concepts that reify document and sentence-level patterns in a given text corpus: (1) an ordered distribution over section titles and (2) given the user's draft and cursor location, many retrieved contextually relevant sentences. Recurring words in the latter are algorithmically highlighted to help users see any emergent norms. Study results (N=16) show that participants revised the structure and content using these concepts, gaining confidence in aligning with or breaking norms after reviewing many examples. These results demonstrate the value of reifying distributions over other authors' writing choices during the writing process.
Leveraging Variation Theory in Counterfactual Data Augmentation for Optimized Active Learning
Aug 07, 2024



Active Learning (AL) allows models to learn interactively from user feedback. This paper introduces a counterfactual data augmentation approach to AL, particularly addressing the selection of datapoints for user querying, a pivotal concern in enhancing data efficiency. Our approach is inspired by Variation Theory, a theory of human concept learning that emphasizes the essential features of a concept by focusing on what stays the same and what changes. Instead of just querying with existing datapoints, our approach synthesizes artificial datapoints that highlight potential key similarities and differences among labels using a neuro-symbolic pipeline combining large language models (LLMs) and rule-based models. Through an experiment in the example domain of text classification, we show that our approach achieves significantly higher performance when there are fewer annotated data. As the annotated training data gets larger the impact of the generated data starts to diminish showing its capability to address the cold start problem in AL. This research sheds light on integrating theories of human learning into the optimization of AL.
Imagining a Future of Designing with AI: Dynamic Grounding, Constructive Negotiation, and Sustainable Motivation
Feb 12, 2024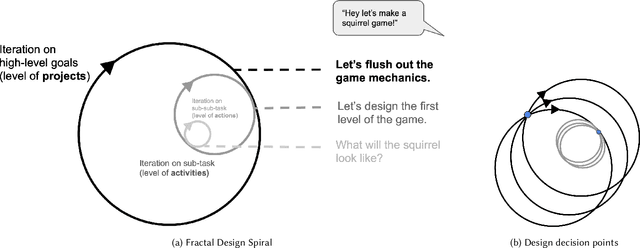

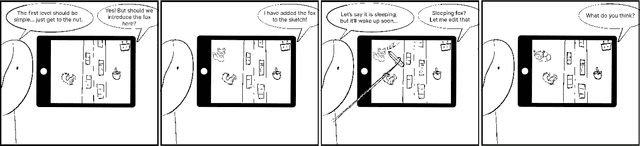
We ideate a future design workflow that involves AI technology. Drawing from activity and communication theory, we attempt to isolate the new value large AI models can provide design compared to past technologies. We arrive at three affordances -- dynamic grounding, constructive negotiation, and sustainable motivation -- that summarize latent qualities of natural language-enabled foundation models that, if explicitly designed for, can support the process of design. Through design fiction, we then imagine a future interface as a diegetic prototype, the story of Squirrel Game, that demonstrates each of our three affordances in a realistic usage scenario. Our design process, terminology, and diagrams aim to contribute to future discussions about the relative affordances of AI technology with regard to collaborating with human designers.
Antagonistic AI
Feb 12, 2024



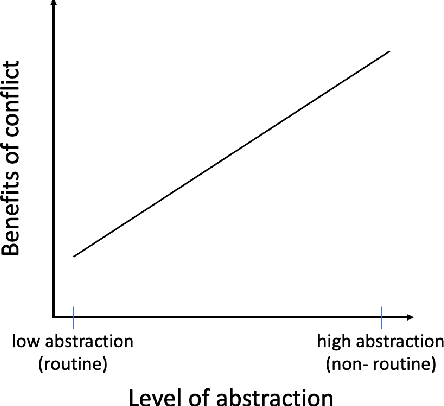
The vast majority of discourse around AI development assumes that subservient, "moral" models aligned with "human values" are universally beneficial -- in short, that good AI is sycophantic AI. We explore the shadow of the sycophantic paradigm, a design space we term antagonistic AI: AI systems that are disagreeable, rude, interrupting, confrontational, challenging, etc. -- embedding opposite behaviors or values. Far from being "bad" or "immoral," we consider whether antagonistic AI systems may sometimes have benefits to users, such as forcing users to confront their assumptions, build resilience, or develop healthier relational boundaries. Drawing from formative explorations and a speculative design workshop where participants designed fictional AI technologies that employ antagonism, we lay out a design space for antagonistic AI, articulating potential benefits, design techniques, and methods of embedding antagonistic elements into user experience. Finally, we discuss the many ethical challenges of this space and identify three dimensions for the responsible design of antagonistic AI -- consent, context, and framing.
Supporting Sensemaking of Large Language Model Outputs at Scale
Jan 24, 2024
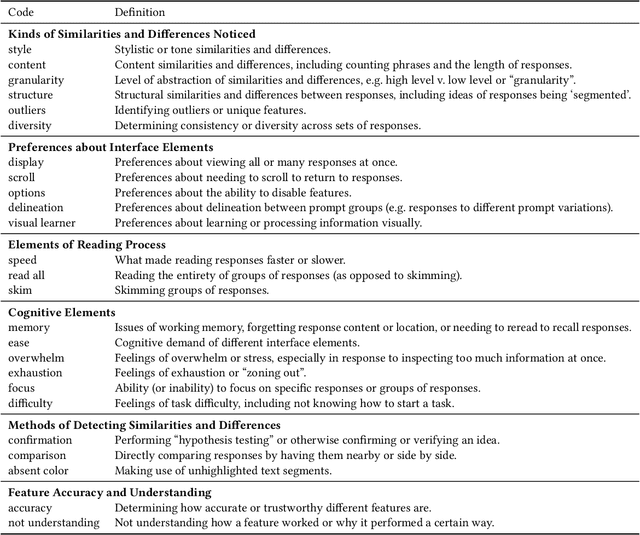


Large language models (LLMs) are capable of generating multiple responses to a single prompt, yet little effort has been expended to help end-users or system designers make use of this capability. In this paper, we explore how to present many LLM responses at once. We design five features, which include both pre-existing and novel methods for computing similarities and differences across textual documents, as well as how to render their outputs. We report on a controlled user study (n=24) and eight case studies evaluating these features and how they support users in different tasks. We find that the features support a wide variety of sensemaking tasks and even make tasks previously considered to be too difficult by our participants now tractable. Finally, we present design guidelines to inform future explorations of new LLM interfaces.
Metric Elicitation; Moving from Theory to Practice
Dec 07, 2022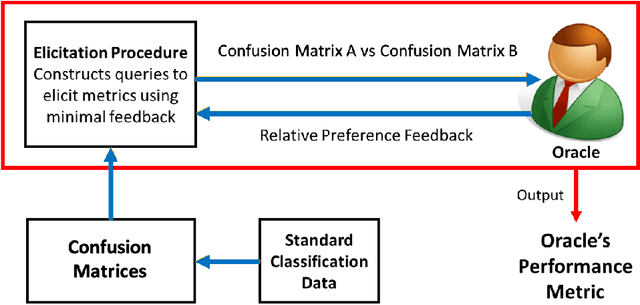
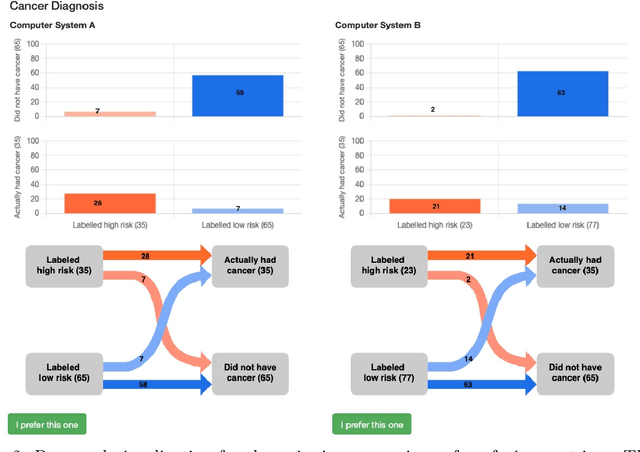
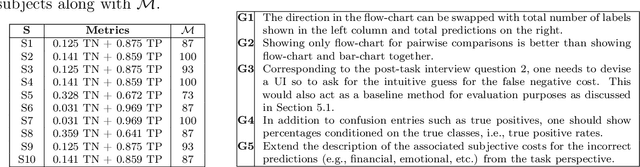
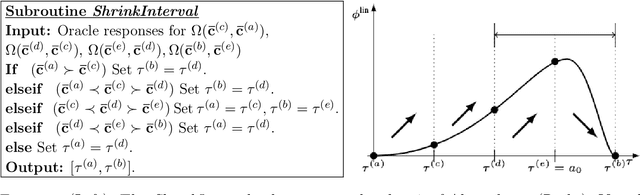
Metric Elicitation (ME) is a framework for eliciting classification metrics that better align with implicit user preferences based on the task and context. The existing ME strategy so far is based on the assumption that users can most easily provide preference feedback over classifier statistics such as confusion matrices. This work examines ME, by providing a first ever implementation of the ME strategy. Specifically, we create a web-based ME interface and conduct a user study that elicits users' preferred metrics in a binary classification setting. We discuss the study findings and present guidelines for future research in this direction.
Evaluating the Interpretability of Generative Models by Interactive Reconstruction
Feb 02, 2021


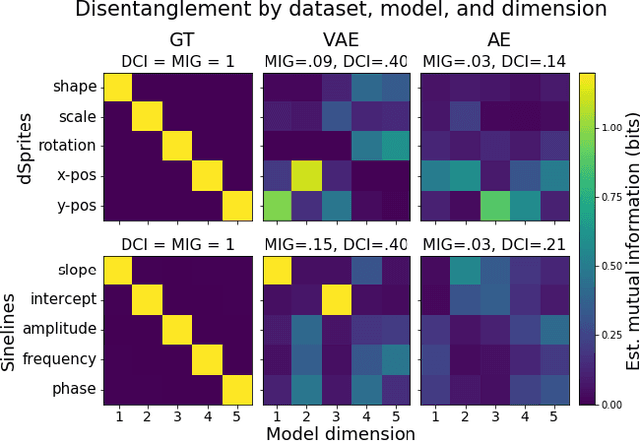
For machine learning models to be most useful in numerous sociotechnical systems, many have argued that they must be human-interpretable. However, despite increasing interest in interpretability, there remains no firm consensus on how to measure it. This is especially true in representation learning, where interpretability research has focused on "disentanglement" measures only applicable to synthetic datasets and not grounded in human factors. We introduce a task to quantify the human-interpretability of generative model representations, where users interactively modify representations to reconstruct target instances. On synthetic datasets, we find performance on this task much more reliably differentiates entangled and disentangled models than baseline approaches. On a real dataset, we find it differentiates between representation learning methods widely believed but never shown to produce more or less interpretable models. In both cases, we ran small-scale think-aloud studies and large-scale experiments on Amazon Mechanical Turk to confirm that our qualitative and quantitative results agreed.
Proxy Tasks and Subjective Measures Can Be Misleading in Evaluating Explainable AI Systems
Jan 22, 2020
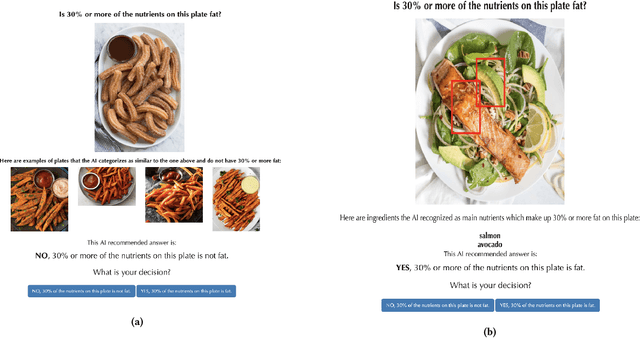
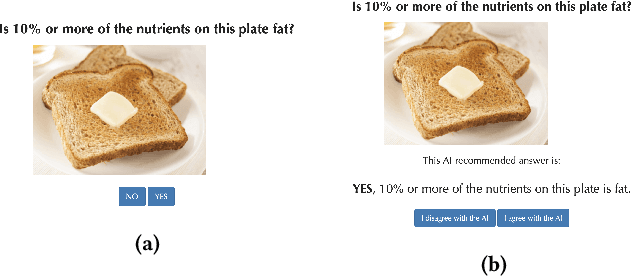
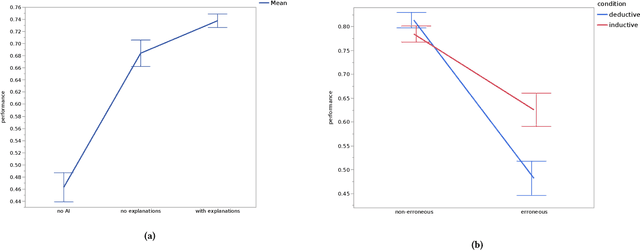
Explainable artificially intelligent (XAI) systems form part of sociotechnical systems, e.g., human+AI teams tasked with making decisions. Yet, current XAI systems are rarely evaluated by measuring the performance of human+AI teams on actual decision-making tasks. We conducted two online experiments and one in-person think-aloud study to evaluate two currently common techniques for evaluating XAI systems: (1) using proxy, artificial tasks such as how well humans predict the AI's decision from the given explanations, and (2) using subjective measures of trust and preference as predictors of actual performance. The results of our experiments demonstrate that evaluations with proxy tasks did not predict the results of the evaluations with the actual decision-making tasks. Further, the subjective measures on evaluations with actual decision-making tasks did not predict the objective performance on those same tasks. Our results suggest that by employing misleading evaluation methods, our field may be inadvertently slowing its progress toward developing human+AI teams that can reliably perform better than humans or AIs alone.