 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning AI Learning Experiences for K-12: Emerging Works, Future Opportunities and a Design Framework
Sep 22, 2020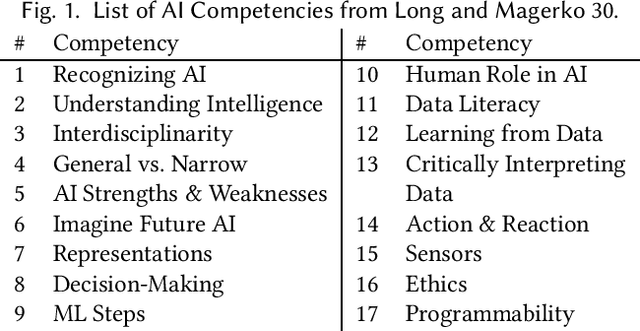
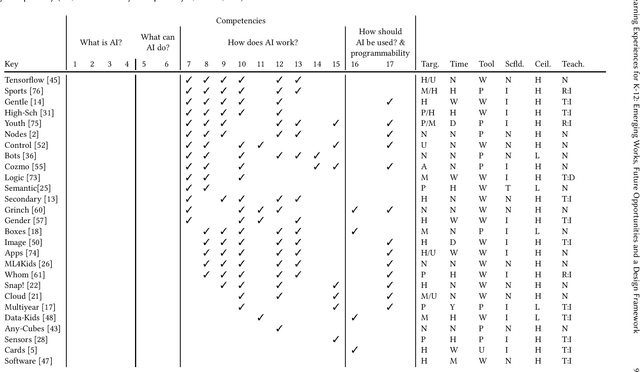
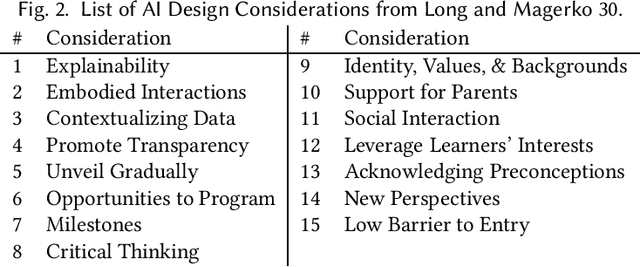

Artificial intelligence (AI) literacy is a rapidly growing research area and a critical addition to K-12 education. However, support for designing tools and curriculum to teach K-12 AI literacy is still limited. There is a need for additional interdisciplinary human-computer interaction and education research investigating (1) how general AI literacy is currently implemented in learning experiences and (2) what additional guidelines are required to teach AI literacy in specifically K-12 learning contexts. In this paper, we analyze a collection of K-12 AI and education literature to show how core competencies of AI literacy are applied successfully and organize them into an educator-friendly chart to enable educators to efficiently find appropriate resources for their classrooms. We also identify future opportunities and K-12 specific design guidelines, which we synthesized into a conceptual framework to support researchers, designers, and educators in creating K-12 AI learning experiences.
Convo: What does conversational programming need? An exploration of machine learning interface design
Mar 03, 2020
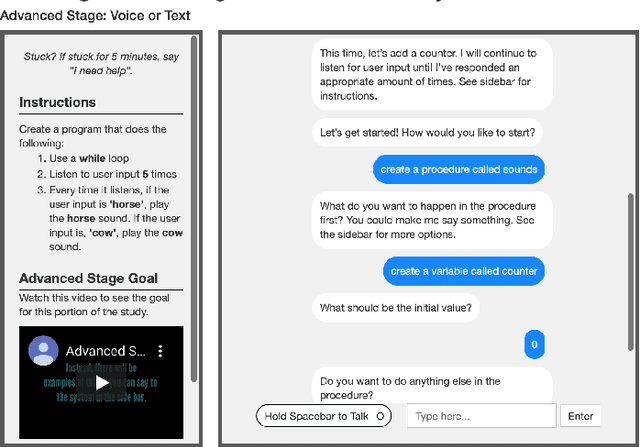
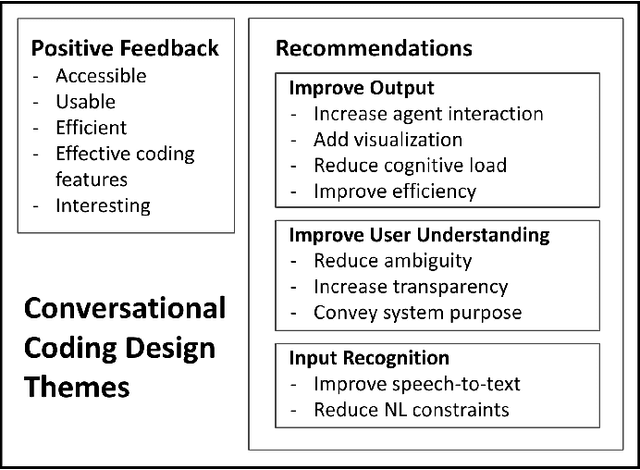
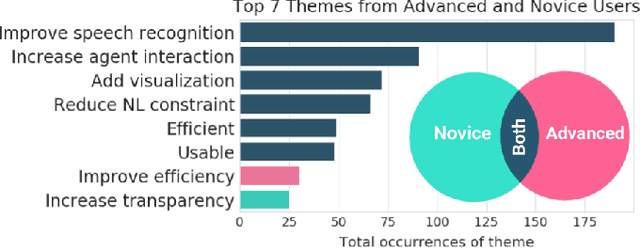
Vast improvements in natural language understanding and speech recognition have paved the way for conversational interaction with computers. While conversational agents have often been used for short goal-oriented dialog, we know little about agents for developing computer programs. To explore the utility of natural language for programming, we conducted a study ($n$=45) comparing different input methods to a conversational programming system we developed. Participants completed novice and advanced tasks using voice-based, text-based, and voice-or-text-based systems. We found that users appreciated aspects of each system (e.g., voice-input efficiency, text-input precision) and that novice users were more optimistic about programming using voice-input than advanced users. Our results show that future conversational programming tools should be tailored to users' programming experience and allow users to choose their preferred input mode. To reduce cognitive load, future interfaces can incorporate visualizations and possess custom natural language understanding and speech recognition models for programming.
Proxy Tasks and Subjective Measures Can Be Misleading in Evaluating Explainable AI Systems
Jan 22, 2020
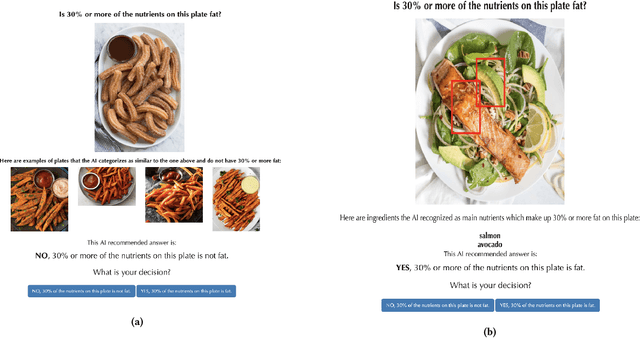
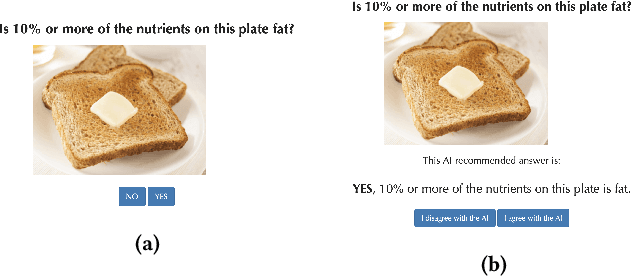
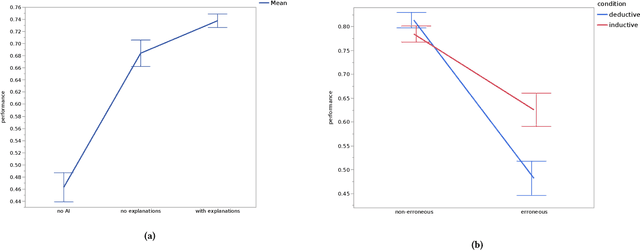
Explainable artificially intelligent (XAI) systems form part of sociotechnical systems, e.g., human+AI teams tasked with making decisions. Yet, current XAI systems are rarely evaluated by measuring the performance of human+AI teams on actual decision-making tasks. We conducted two online experiments and one in-person think-aloud study to evaluate two currently common techniques for evaluating XAI systems: (1) using proxy, artificial tasks such as how well humans predict the AI's decision from the given explanations, and (2) using subjective measures of trust and preference as predictors of actual performance. The results of our experiments demonstrate that evaluations with proxy tasks did not predict the results of the evaluations with the actual decision-making tasks. Further, the subjective measures on evaluations with actual decision-making tasks did not predict the objective performance on those same tasks. Our results suggest that by employing misleading evaluation methods, our field may be inadvertently slowing its progress toward developing human+AI teams that can reliably perform better than humans or AIs alone.