 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills
Oct 05, 2024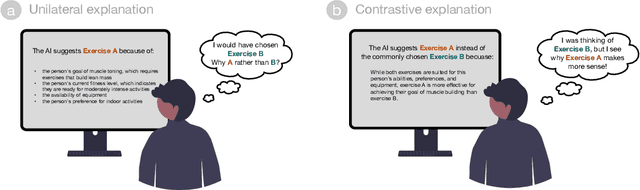
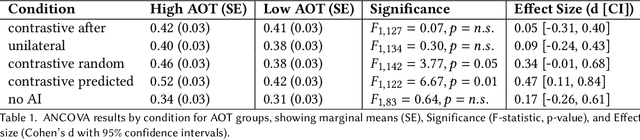


People's decision-making abilities often fail to improve or may even erode when they rely on AI for decision-support, even when the AI provides informative explanations. We argue this is partly because people intuitively seek contrastive explanations, which clarify the difference between the AI's decision and their own reasoning, while most AI systems offer "unilateral" explanations that justify the AI's decision but do not account for users' thinking. To align human-AI knowledge on decision tasks, we introduce a framework for generating human-centered contrastive explanations that explain the difference between AI's choice and a predicted, likely human choice about the same task. Results from a large-scale experiment (N = 628) demonstrate that contrastive explanations significantly enhance users' independent decision-making skills compared to unilateral explanations, without sacrificing decision accuracy. Amid rising deskilling concerns, our research demonstrates that incorporating human reasoning into AI design can foster human skill development.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024



As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.
Do People Engage Cognitively with AI? Impact of AI Assistance on Incidental Learning
Feb 11, 2022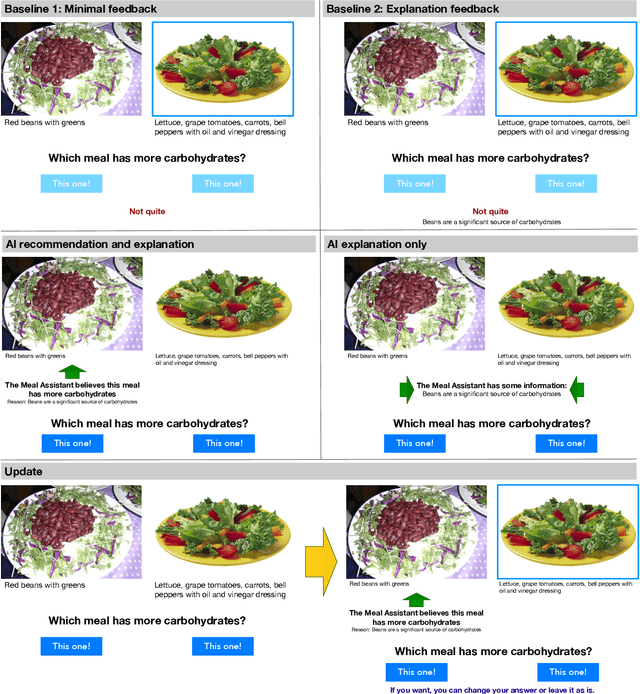
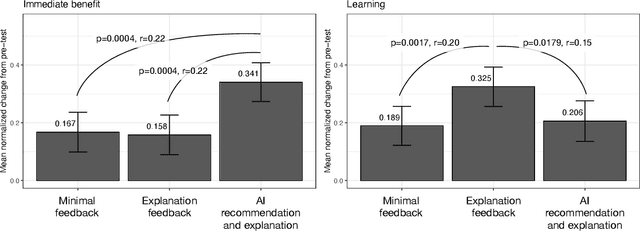
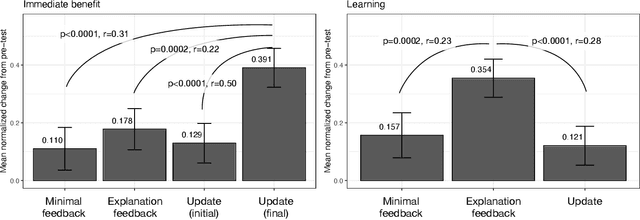
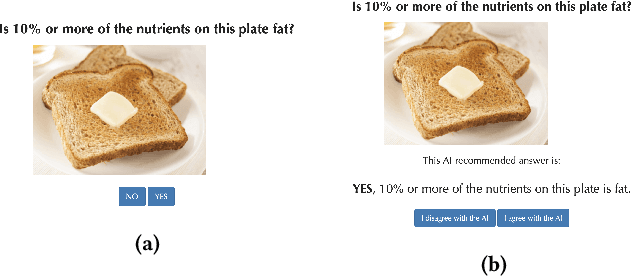
When people receive advice while making difficult decisions, they often make better decisions in the moment and also increase their knowledge in the process. However, such incidental learning can only occur when people cognitively engage with the information they receive and process this information thoughtfully. How do people process the information and advice they receive from AI, and do they engage with it deeply enough to enable learning? To answer these questions, we conducted three experiments in which individuals were asked to make nutritional decisions and received simulated AI recommendations and explanations. In the first experiment, we found that when people were presented with both a recommendation and an explanation before making their choice, they made better decisions than they did when they received no such help, but they did not learn. In the second experiment, participants first made their own choice, and only then saw a recommendation and an explanation from AI; this condition also resulted in improved decisions, but no learning. However, in our third experiment, participants were presented with just an AI explanation but no recommendation and had to arrive at their own decision. This condition led to both more accurate decisions and learning gains. We hypothesize that learning gains in this condition were due to deeper engagement with explanations needed to arrive at the decisions. This work provides some of the most direct evidence to date that it may not be sufficient to include explanations together with AI-generated recommendation to ensure that people engage carefully with the AI-provided information. This work also presents one technique that enables incidental learning and, by implication, can help people process AI recommendations and explanations more carefully.
To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making
Feb 19, 2021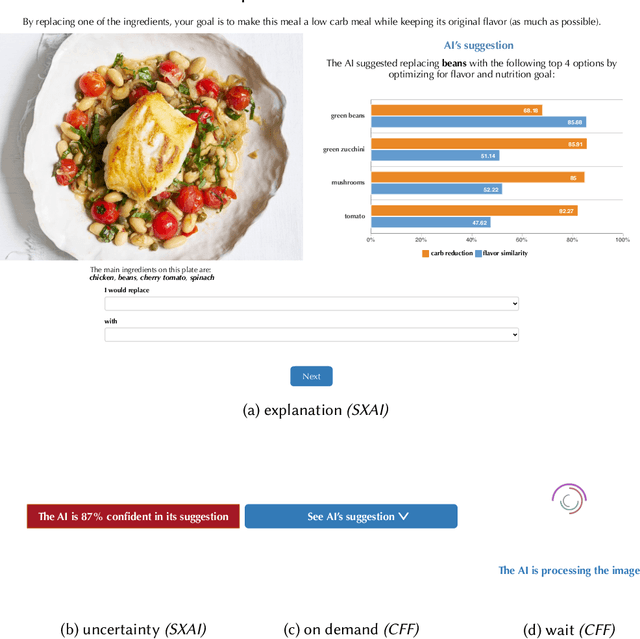
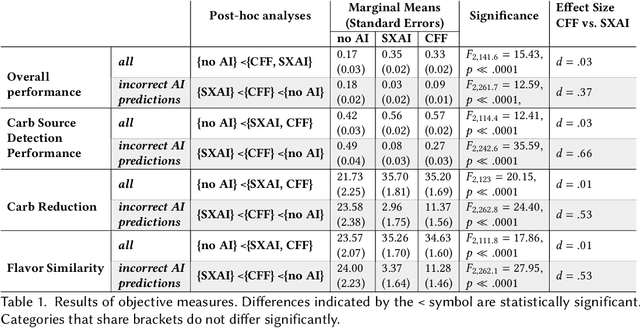

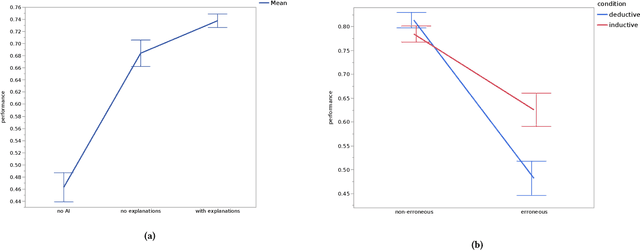
People supported by AI-powered decision support tools frequently overrely on the AI: they accept an AI's suggestion even when that suggestion is wrong. Adding explanations to the AI decisions does not appear to reduce the overreliance and some studies suggest that it might even increase it. Informed by the dual-process theory of cognition, we posit that people rarely engage analytically with each individual AI recommendation and explanation, and instead develop general heuristics about whether and when to follow the AI suggestions. Building on prior research on medical decision-making, we designed three cognitive forcing interventions to compel people to engage more thoughtfully with the AI-generated explanations. We conducted an experiment (N=199), in which we compared our three cognitive forcing designs to two simple explainable AI approaches and to a no-AI baseline. The results demonstrate that cognitive forcing significantly reduced overreliance compared to the simple explainable AI approaches. However, there was a trade-off: people assigned the least favorable subjective ratings to the designs that reduced the overreliance the most. To audit our work for intervention-generated inequalities, we investigated whether our interventions benefited equally people with different levels of Need for Cognition (i.e., motivation to engage in effortful mental activities). Our results show that, on average, cognitive forcing interventions benefited participants higher in Need for Cognition more. Our research suggests that human cognitive motivation moderates the effectiveness of explainable AI solutions.
Proxy Tasks and Subjective Measures Can Be Misleading in Evaluating Explainable AI Systems
Jan 22, 2020
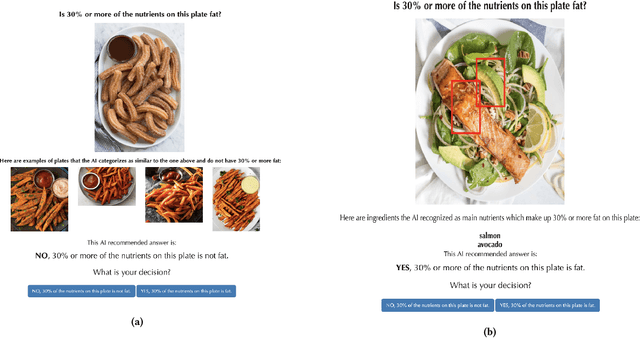
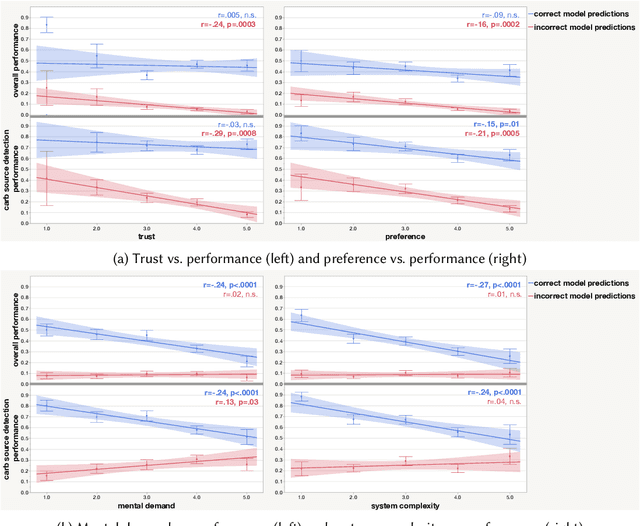
Explainable artificially intelligent (XAI) systems form part of sociotechnical systems, e.g., human+AI teams tasked with making decisions. Yet, current XAI systems are rarely evaluated by measuring the performance of human+AI teams on actual decision-making tasks. We conducted two online experiments and one in-person think-aloud study to evaluate two currently common techniques for evaluating XAI systems: (1) using proxy, artificial tasks such as how well humans predict the AI's decision from the given explanations, and (2) using subjective measures of trust and preference as predictors of actual performance. The results of our experiments demonstrate that evaluations with proxy tasks did not predict the results of the evaluations with the actual decision-making tasks. Further, the subjective measures on evaluations with actual decision-making tasks did not predict the objective performance on those same tasks. Our results suggest that by employing misleading evaluation methods, our field may be inadvertently slowing its progress toward developing human+AI teams that can reliably perform better than humans or AIs alone.
BubbleView: an interface for crowdsourcing image importance maps and tracking visual attention
Aug 09, 2017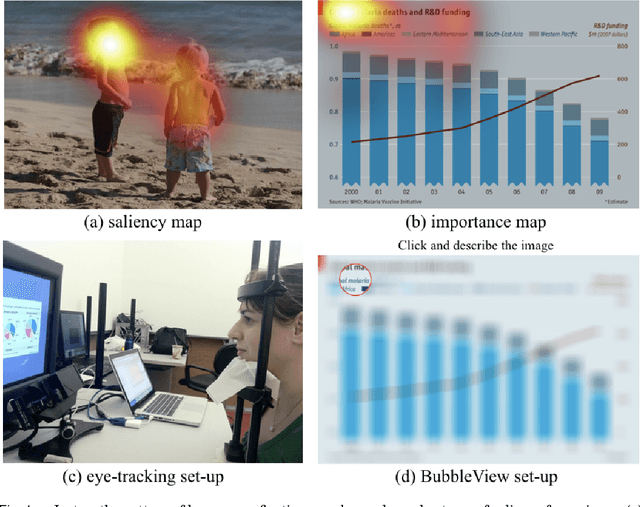
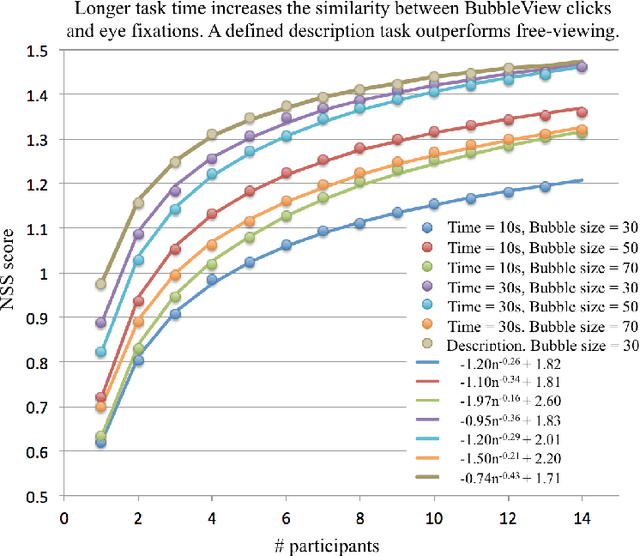

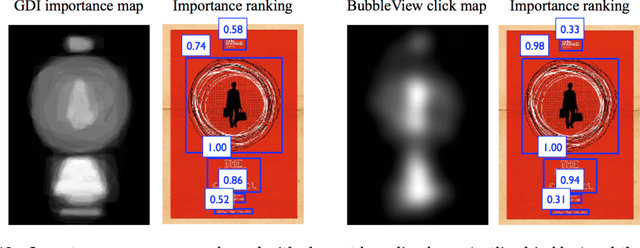
In this paper, we present BubbleView, an alternative methodology for eye tracking using discrete mouse clicks to measure which information people consciously choose to examine. BubbleView is a mouse-contingent, moving-window interface in which participants are presented with a series of blurred images and click to reveal "bubbles" - small, circular areas of the image at original resolution, similar to having a confined area of focus like the eye fovea. Across 10 experiments with 28 different parameter combinations, we evaluated BubbleView on a variety of image types: information visualizations, natural images, static webpages, and graphic designs, and compared the clicks to eye fixations collected with eye-trackers in controlled lab settings. We found that BubbleView clicks can both (i) successfully approximate eye fixations on different images, and (ii) be used to rank image and design elements by importance. BubbleView is designed to collect clicks on static images, and works best for defined tasks such as describing the content of an information visualization or measuring image importance. BubbleView data is cleaner and more consistent than related methodologies that use continuous mouse movements. Our analyses validate the use of mouse-contingent, moving-window methodologies as approximating eye fixations for different image and task types.