 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of SVBRDF Prediction from Generative Image Models for Appearance Modeling of 3D Scenes
Dec 15, 2025Digital content creation is experiencing a profound change with the advent of deep generative models. For texturing, conditional image generators now allow the synthesis of realistic RGB images of a 3D scene that align with the geometry of that scene. For appearance modeling, SVBRDF prediction networks recover material parameters from RGB images. Combining these technologies allows us to quickly generate SVBRDF maps for multiple views of a 3D scene, which can be merged to form a SVBRDF texture atlas of that scene. In this paper, we analyze the challenges and opportunities for SVBRDF prediction in the context of such a fast appearance modeling pipeline. On the one hand, single-view SVBRDF predictions might suffer from multiview incoherence and yield inconsistent texture atlases. On the other hand, generated RGB images, and the different modalities on which they are conditioned, can provide additional information for SVBRDF estimation compared to photographs. We compare neural architectures and conditions to identify designs that achieve high accuracy and coherence. We find that, surprisingly, a standard UNet is competitive with more complex designs. Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation
* Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation Code: http://github.com/graphdeco-inria/svbrdf-evaluation
From Slow Bidirectional to Fast Causal Video Generators
Dec 10, 2024



Current video diffusion models achieve impressive generation quality but struggle in interactive applications due to bidirectional attention dependencies. The generation of a single frame requires the model to process the entire sequence, including the future. We address this limitation by adapting a pretrained bidirectional diffusion transformer to a causal transformer that generates frames on-the-fly. To further reduce latency, we extend distribution matching distillation (DMD) to videos, distilling 50-step diffusion model into a 4-step generator. To enable stable and high-quality distillation, we introduce a student initialization scheme based on teacher's ODE trajectories, as well as an asymmetric distillation strategy that supervises a causal student model with a bidirectional teacher. This approach effectively mitigates error accumulation in autoregressive generation, allowing long-duration video synthesis despite training on short clips. Our model supports fast streaming generation of high quality videos at 9.4 FPS on a single GPU thanks to KV caching. Our approach also enables streaming video-to-video translation, image-to-video, and dynamic prompting in a zero-shot manner. We will release the code based on an open-source model in the future.
Improved Distribution Matching Distillation for Fast Image Synthesis
May 23, 2024
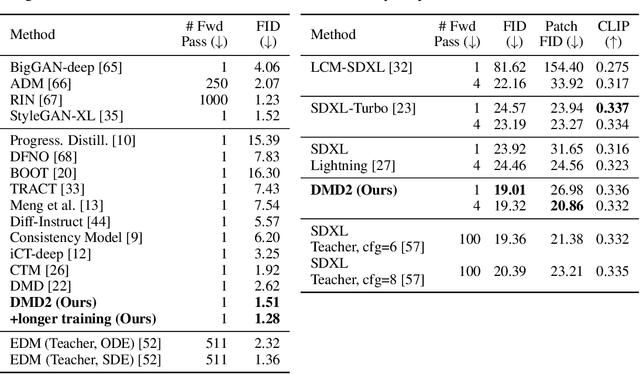

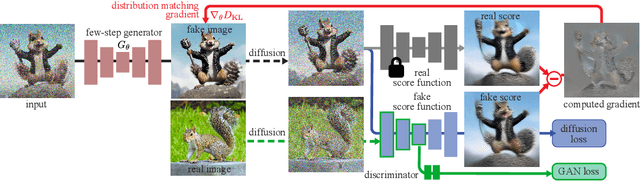
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Alchemist: Parametric Control of Material Properties with Diffusion Models
Dec 05, 2023
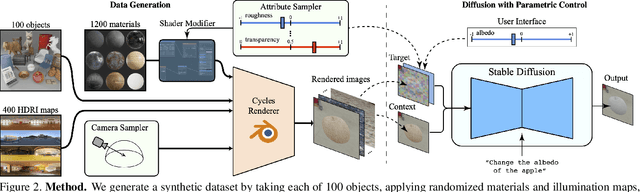


We propose a method to control material attributes of objects like roughness, metallic, albedo, and transparency in real images. Our method capitalizes on the generative prior of text-to-image models known for photorealism, employing a scalar value and instructions to alter low-level material properties. Addressing the lack of datasets with controlled material attributes, we generated an object-centric synthetic dataset with physically-based materials. Fine-tuning a modified pre-trained text-to-image model on this synthetic dataset enables us to edit material properties in real-world images while preserving all other attributes. We show the potential application of our model to material edited NeRFs.
One-step Diffusion with Distribution Matching Distillation
Dec 05, 2023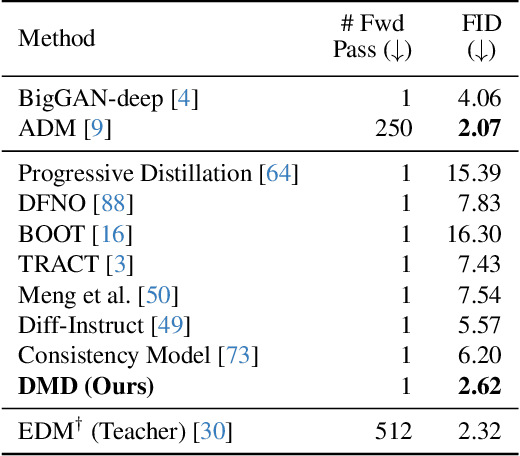
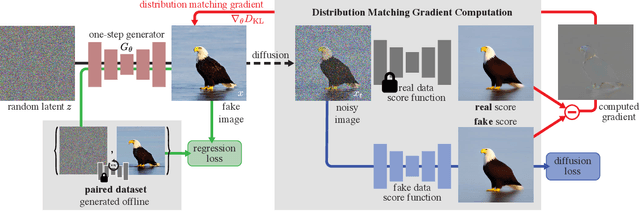
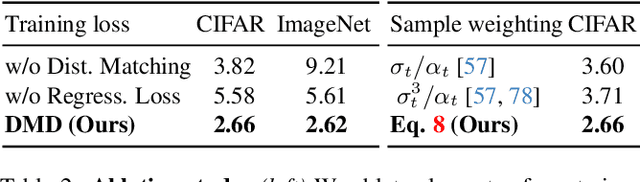
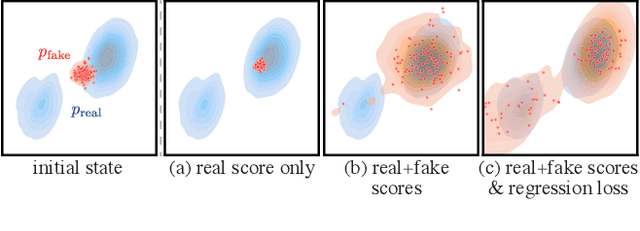
Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
Materialistic: Selecting Similar Materials in Images
May 22, 2023Separating an image into meaningful underlying components is a crucial first step for both editing and understanding images. We present a method capable of selecting the regions of a photograph exhibiting the same material as an artist-chosen area. Our proposed approach is robust to shading, specular highlights, and cast shadows, enabling selection in real images. As we do not rely on semantic segmentation (different woods or metal should not be selected together), we formulate the problem as a similarity-based grouping problem based on a user-provided image location. In particular, we propose to leverage the unsupervised DINO features coupled with a proposed Cross-Similarity module and an MLP head to extract material similarities in an image. We train our model on a new synthetic image dataset, that we release. We show that our method generalizes well to real-world images. We carefully analyze our model's behavior on varying material properties and lighting. Additionally, we evaluate it against a hand-annotated benchmark of 50 real photographs. We further demonstrate our model on a set of applications, including material editing, in-video selection, and retrieval of object photographs with similar materials.
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022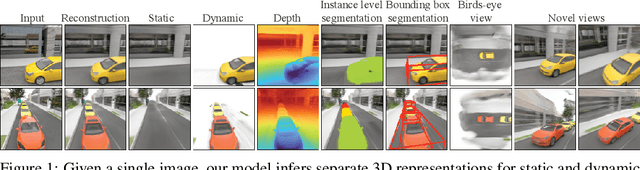
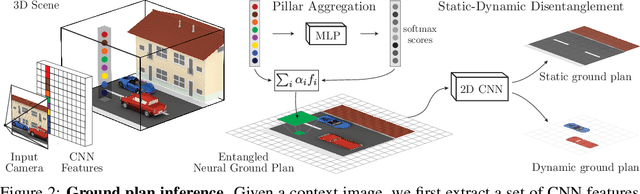
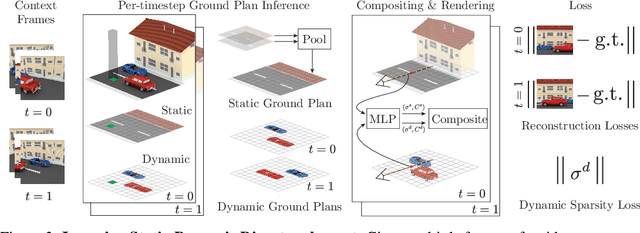
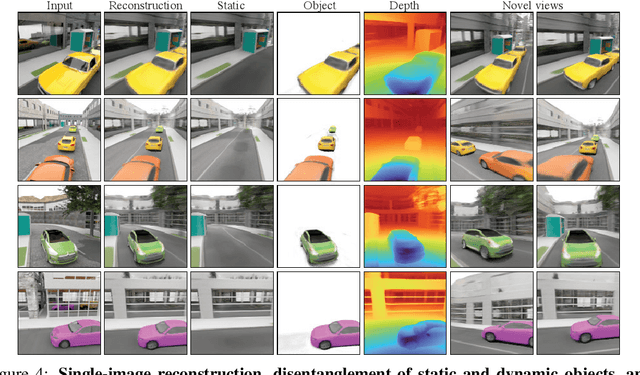
Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
Unsupervised Discovery and Composition of Object Light Fields
May 08, 2022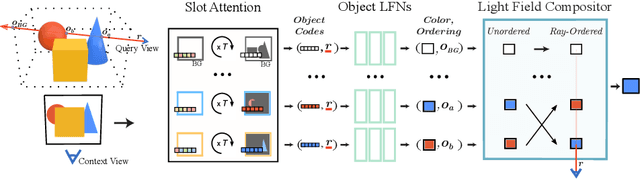

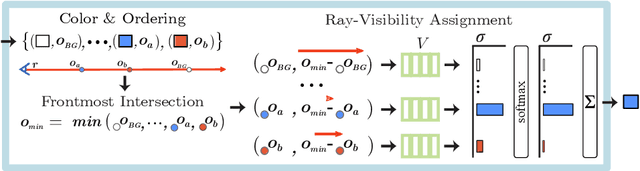

Neural scene representations, both continuous and discrete, have recently emerged as a powerful new paradigm for 3D scene understanding. Recent efforts have tackled unsupervised discovery of object-centric neural scene representations. However, the high cost of ray-marching, exacerbated by the fact that each object representation has to be ray-marched separately, leads to insufficiently sampled radiance fields and thus, noisy renderings, poor framerates, and high memory and time complexity during training and rendering. Here, we propose to represent objects in an object-centric, compositional scene representation as light fields. We propose a novel light field compositor module that enables reconstructing the global light field from a set of object-centric light fields. Dubbed Compositional Object Light Fields (COLF), our method enables unsupervised learning of object-centric neural scene representations, state-of-the-art reconstruction and novel view synthesis performance on standard datasets, and rendering and training speeds at orders of magnitude faster than existing 3D approaches.
Learning to generate line drawings that convey geometry and semantics
Mar 29, 2022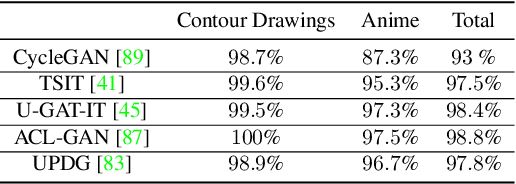

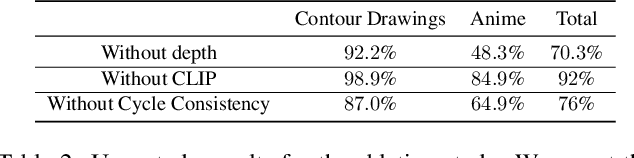

This paper presents an unpaired method for creating line drawings from photographs. Current methods often rely on high quality paired datasets to generate line drawings. However, these datasets often have limitations due to the subjects of the drawings belonging to a specific domain, or in the amount of data collected. Although recent work in unsupervised image-to-image translation has shown much progress, the latest methods still struggle to generate compelling line drawings. We observe that line drawings are encodings of scene information and seek to convey 3D shape and semantic meaning. We build these observations into a set of objectives and train an image translation to map photographs into line drawings. We introduce a geometry loss which predicts depth information from the image features of a line drawing, and a semantic loss which matches the CLIP features of a line drawing with its corresponding photograph. Our approach outperforms state-of-the-art unpaired image translation and line drawing generation methods on creating line drawings from arbitrary photographs. For code and demo visit our webpage carolineec.github.io/informative_drawings
What You Can Learn by Staring at a Blank Wall
Aug 30, 2021



We present a passive non-line-of-sight method that infers the number of people or activity of a person from the observation of a blank wall in an unknown room. Our technique analyzes complex imperceptible changes in indirect illumination in a video of the wall to reveal a signal that is correlated with motion in the hidden part of a scene. We use this signal to classify between zero, one, or two moving people, or the activity of a person in the hidden scene. We train two convolutional neural networks using data collected from 20 different scenes, and achieve an accuracy of $\approx94\%$ for both tasks in unseen test environments and real-time online settings. Unlike other passive non-line-of-sight methods, the technique does not rely on known occluders or controllable light sources, and generalizes to unknown rooms with no re-calibration. We analyze the generalization and robustness of our method with both real and synthetic data, and study the effect of the scene parameters on the signal quality.