 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Paper and Code
Jul 22, 2022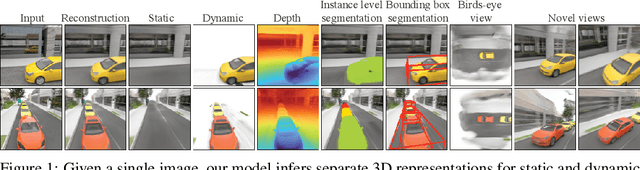
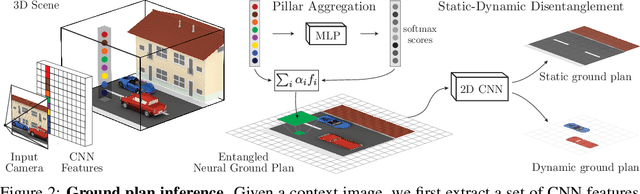
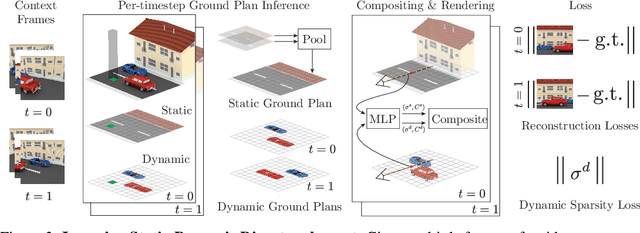
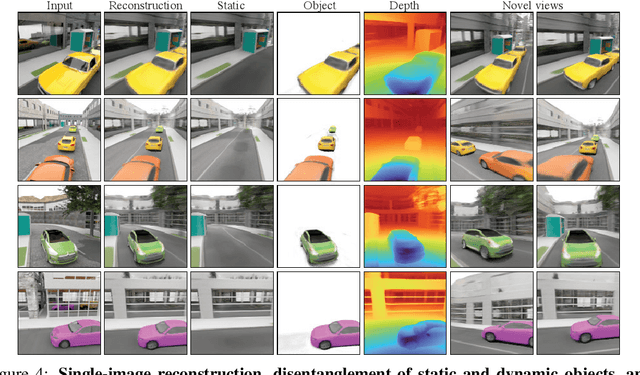
Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.