 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Distribution Matching Distillation for Fast Image Synthesis
May 23, 2024
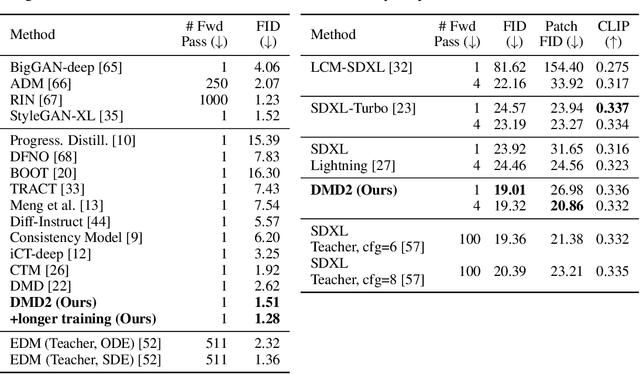

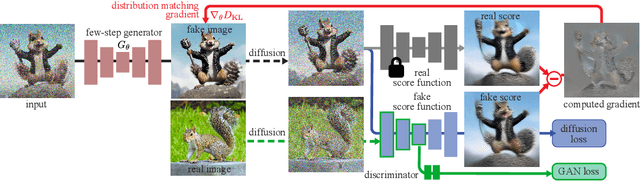
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Editable Image Elements for Controllable Synthesis
Apr 24, 2024
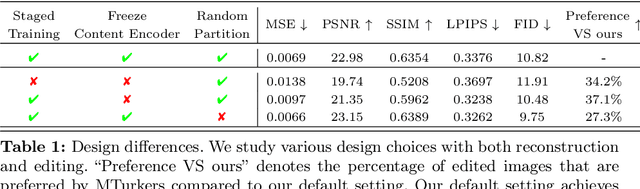
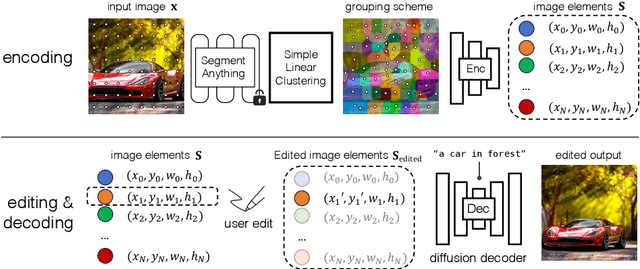
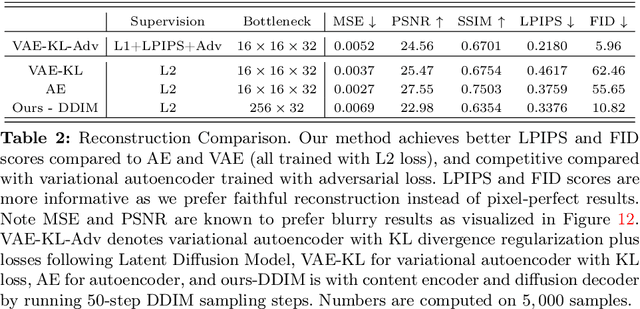
Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing. In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into "image elements" that can faithfully reconstruct an input image. These elements can be intuitively edited by a user, and are decoded by a diffusion model into realistic images. We show the effectiveness of our representation on various image editing tasks, such as object resizing, rearrangement, dragging, de-occlusion, removal, variation, and image composition. Project page: https://jitengmu.github.io/Editable_Image_Elements/
Lazy Diffusion Transformer for Interactive Image Editing
Apr 18, 2024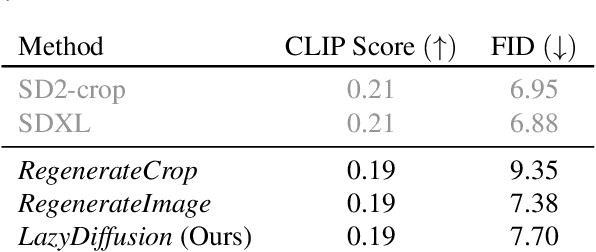

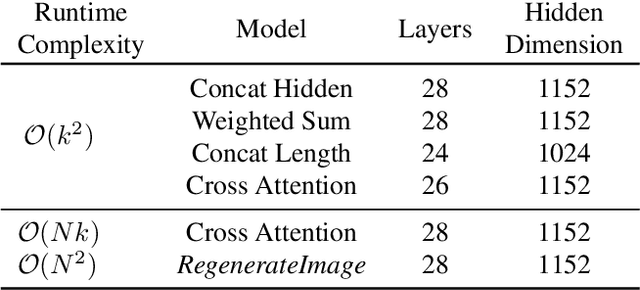

We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
Learning Subject-Aware Cropping by Outpainting Professional Photos
Dec 19, 2023



How to frame (or crop) a photo often depends on the image subject and its context; e.g., a human portrait. Recent works have defined the subject-aware image cropping task as a nuanced and practical version of image cropping. We propose a weakly-supervised approach (GenCrop) to learn what makes a high-quality, subject-aware crop from professional stock images. Unlike supervised prior work, GenCrop requires no new manual annotations beyond the existing stock image collection. The key challenge in learning from this data, however, is that the images are already cropped and we do not know what regions were removed. Our insight is combine a library of stock images with a modern, pre-trained text-to-image diffusion model. The stock image collection provides diversity and its images serve as pseudo-labels for a good crop, while the text-image diffusion model is used to out-paint (i.e., outward inpainting) realistic uncropped images. Using this procedure, we are able to automatically generate a large dataset of cropped-uncropped training pairs to train a cropping model. Despite being weakly-supervised, GenCrop is competitive with state-of-the-art supervised methods and significantly better than comparable weakly-supervised baselines on quantitative and qualitative evaluation metrics.
One-step Diffusion with Distribution Matching Distillation
Dec 05, 2023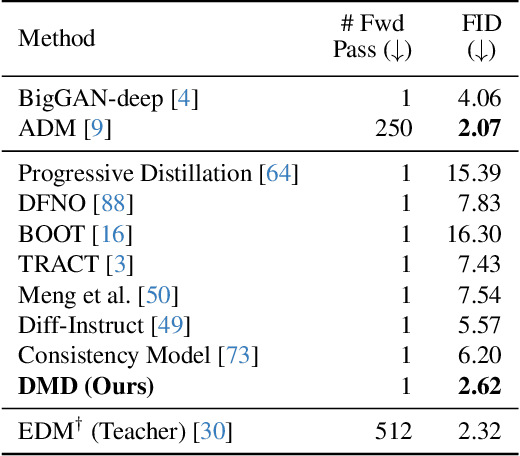
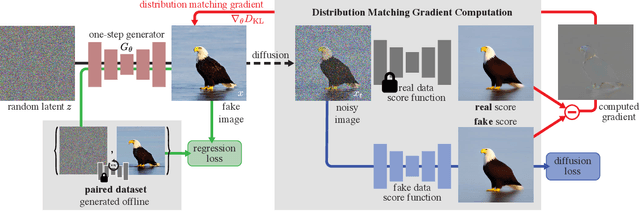
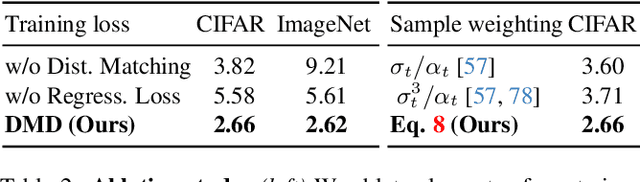
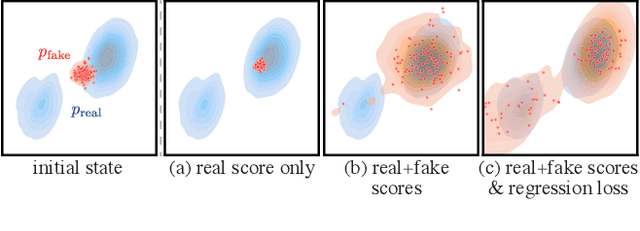
Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
Materialistic: Selecting Similar Materials in Images
May 22, 2023Separating an image into meaningful underlying components is a crucial first step for both editing and understanding images. We present a method capable of selecting the regions of a photograph exhibiting the same material as an artist-chosen area. Our proposed approach is robust to shading, specular highlights, and cast shadows, enabling selection in real images. As we do not rely on semantic segmentation (different woods or metal should not be selected together), we formulate the problem as a similarity-based grouping problem based on a user-provided image location. In particular, we propose to leverage the unsupervised DINO features coupled with a proposed Cross-Similarity module and an MLP head to extract material similarities in an image. We train our model on a new synthetic image dataset, that we release. We show that our method generalizes well to real-world images. We carefully analyze our model's behavior on varying material properties and lighting. Additionally, we evaluate it against a hand-annotated benchmark of 50 real photographs. We further demonstrate our model on a set of applications, including material editing, in-video selection, and retrieval of object photographs with similar materials.
Semi-supervised Parametric Real-world Image Harmonization
Mar 01, 2023



Learning-based image harmonization techniques are usually trained to undo synthetic random global transformations applied to a masked foreground in a single ground truth photo. This simulated data does not model many of the important appearance mismatches (illumination, object boundaries, etc.) between foreground and background in real composites, leading to models that do not generalize well and cannot model complex local changes. We propose a new semi-supervised training strategy that addresses this problem and lets us learn complex local appearance harmonization from unpaired real composites, where foreground and background come from different images. Our model is fully parametric. It uses RGB curves to correct the global colors and tone and a shading map to model local variations. Our method outperforms previous work on established benchmarks and real composites, as shown in a user study, and processes high-resolution images interactively.
Domain Expansion of Image Generators
Jan 12, 2023Can one inject new concepts into an already trained generative model, while respecting its existing structure and knowledge? We propose a new task - domain expansion - to address this. Given a pretrained generator and novel (but related) domains, we expand the generator to jointly model all domains, old and new, harmoniously. First, we note the generator contains a meaningful, pretrained latent space. Is it possible to minimally perturb this hard-earned representation, while maximally representing the new domains? Interestingly, we find that the latent space offers unused, "dormant" directions, which do not affect the output. This provides an opportunity: By "repurposing" these directions, we can represent new domains without perturbing the original representation. In fact, we find that pretrained generators have the capacity to add several - even hundreds - of new domains! Using our expansion method, one "expanded" model can supersede numerous domain-specific models, without expanding the model size. Additionally, a single expanded generator natively supports smooth transitions between domains, as well as composition of domains. Code and project page available at https://yotamnitzan.github.io/domain-expansion/.
Spotting Temporally Precise, Fine-Grained Events in Video
Jul 20, 2022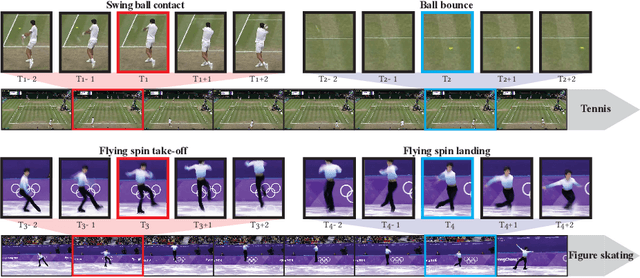
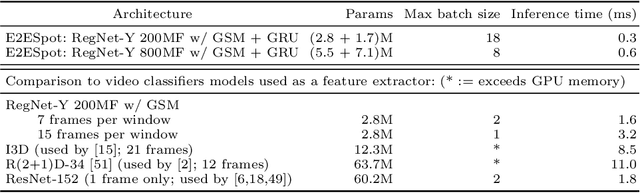
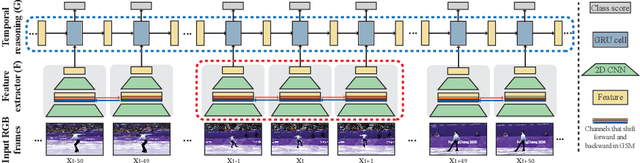
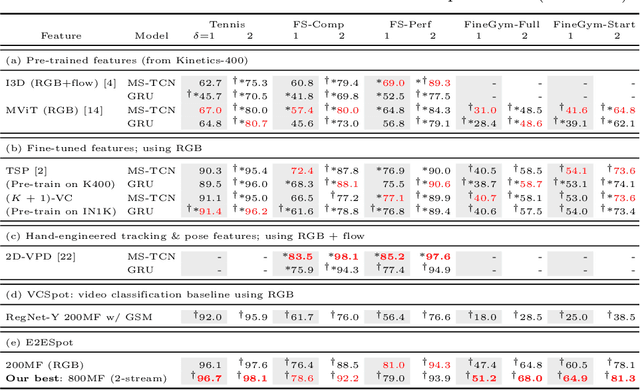
We introduce the task of spotting temporally precise, fine-grained events in video (detecting the precise moment in time events occur). Precise spotting requires models to reason globally about the full-time scale of actions and locally to identify subtle frame-to-frame appearance and motion differences that identify events during these actions. Surprisingly, we find that top performing solutions to prior video understanding tasks such as action detection and segmentation do not simultaneously meet both requirements. In response, we propose E2E-Spot, a compact, end-to-end model that performs well on the precise spotting task and can be trained quickly on a single GPU. We demonstrate that E2E-Spot significantly outperforms recent baselines adapted from the video action detection, segmentation, and spotting literature to the precise spotting task. Finally, we contribute new annotations and splits to several fine-grained sports action datasets to make these datasets suitable for future work on precise spotting.
Differentiable Rendering of Neural SDFs through Reparameterization
Jun 10, 2022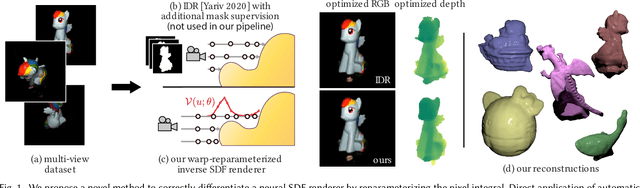

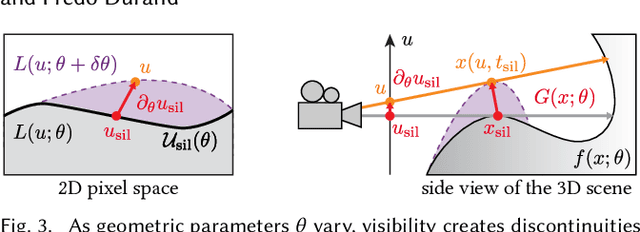
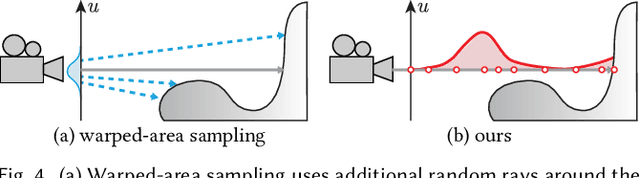
We present a method to automatically compute correct gradients with respect to geometric scene parameters in neural SDF renderers. Recent physically-based differentiable rendering techniques for meshes have used edge-sampling to handle discontinuities, particularly at object silhouettes, but SDFs do not have a simple parametric form amenable to sampling. Instead, our approach builds on area-sampling techniques and develops a continuous warping function for SDFs to account for these discontinuities. Our method leverages the distance to surface encoded in an SDF and uses quadrature on sphere tracer points to compute this warping function. We further show that this can be done by subsampling the points to make the method tractable for neural SDFs. Our differentiable renderer can be used to optimize neural shapes from multi-view images and produces comparable 3D reconstructions to recent SDF-based inverse rendering methods, without the need for 2D segmentation masks to guide the geometry optimization and no volumetric approximations to the geometry.