 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiper: A Programmable Distributed Training System
Jun 09, 2026Large-scale model training increasingly relies on composing multiple parallelism strategies, such as data, pipeline, and expert parallelism, together with memory-saving optimizations like ZeRO. Deployed systems for foundation model pretraining often rely on human experts to manually design a high-level parallelism strategy then implement the corresponding low-level execution strategy, making it difficult to adapt the system to new strategies. Meanwhile, many general-purpose frameworks are more flexible but their implementations are still tied to a fixed set of common parallelism strategies, making it challenging to integrate state-of-the-art strategies. We present Piper, a user-controllable distributed training system that decouples the strategy from the runtime implementation. Piper allows users to declare a comprehensive distributed training strategy with a small set of model annotations and scheduling directives. Each directive applies a transformation on Piper's intermediate representation (IR), a unified global training DAG that represents all computation and communication. Using this IR, Piper compiles per-device execution plans and executes them with a distributed runtime agnostic to the strategy. We show that the combined system maintains performance parity on commonly available strategies such as ZeRO, while also enabling additional performance and memory efficiency gains through joint scheduling of compute and communication in composed parallelism strategies such as DeepSeek-V3's DualPipe.
Learning to Move Like Professional Counter-Strike Players
Aug 25, 2024
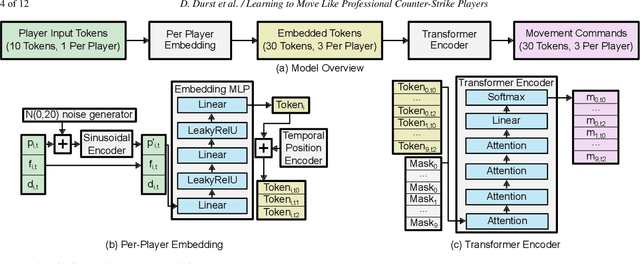
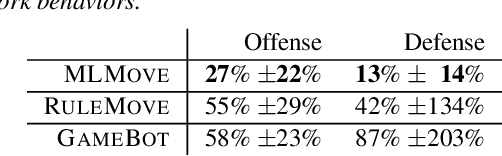
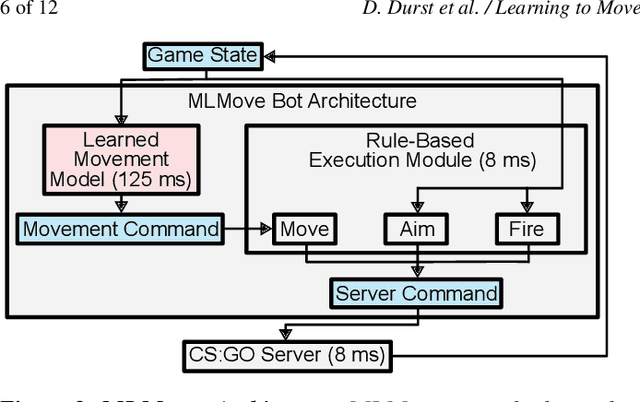
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
Differentiable Rendering of Neural SDFs through Reparameterization
Jun 10, 2022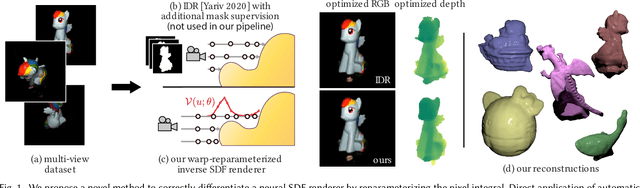

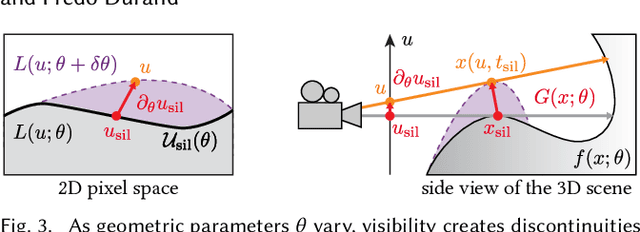
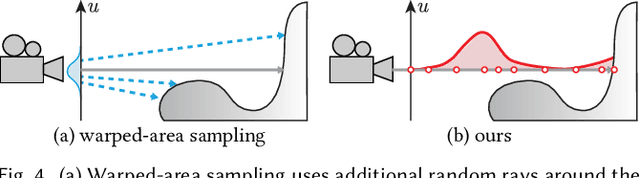
We present a method to automatically compute correct gradients with respect to geometric scene parameters in neural SDF renderers. Recent physically-based differentiable rendering techniques for meshes have used edge-sampling to handle discontinuities, particularly at object silhouettes, but SDFs do not have a simple parametric form amenable to sampling. Instead, our approach builds on area-sampling techniques and develops a continuous warping function for SDFs to account for these discontinuities. Our method leverages the distance to surface encoded in an SDF and uses quadrature on sphere tracer points to compute this warping function. We further show that this can be done by subsampling the points to make the method tractable for neural SDFs. Our differentiable renderer can be used to optimize neural shapes from multi-view images and produces comparable 3D reconstructions to recent SDF-based inverse rendering methods, without the need for 2D segmentation masks to guide the geometry optimization and no volumetric approximations to the geometry.
Opt: A Domain Specific Language for Non-linear Least Squares Optimization in Graphics and Imaging
Sep 09, 2017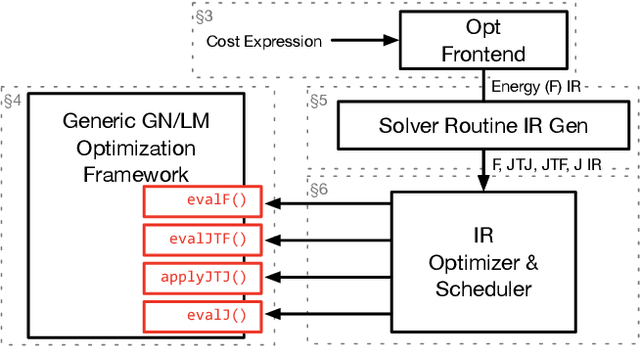



Many graphics and vision problems can be expressed as non-linear least squares optimizations of objective functions over visual data, such as images and meshes. The mathematical descriptions of these functions are extremely concise, but their implementation in real code is tedious, especially when optimized for real-time performance on modern GPUs in interactive applications. In this work, we propose a new language, Opt (available under http://optlang.org), for writing these objective functions over image- or graph-structured unknowns concisely and at a high level. Our compiler automatically transforms these specifications into state-of-the-art GPU solvers based on Gauss-Newton or Levenberg-Marquardt methods. Opt can generate different variations of the solver, so users can easily explore tradeoffs in numerical precision, matrix-free methods, and solver approaches. In our results, we implement a variety of real-world graphics and vision applications. Their energy functions are expressible in tens of lines of code, and produce highly-optimized GPU solver implementations. These solver have performance competitive with the best published hand-tuned, application-specific GPU solvers, and orders of magnitude beyond a general-purpose auto-generated solver.