 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Move Like Professional Counter-Strike Players
Aug 25, 2024
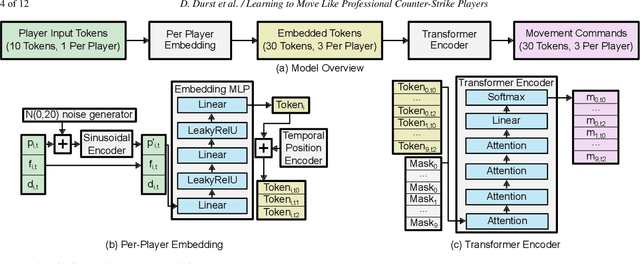
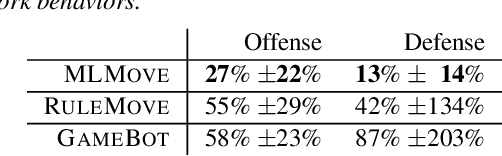
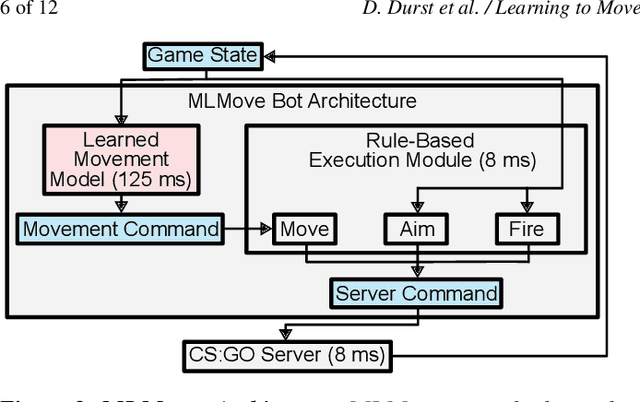
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
Automating Program Structure Classification
Jan 15, 2021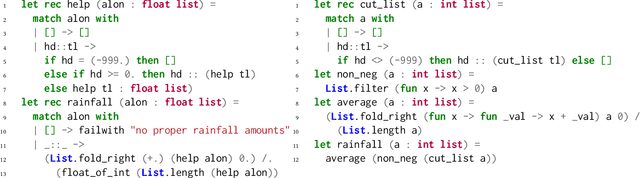

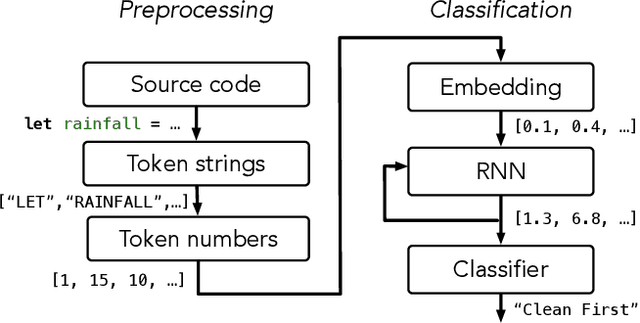
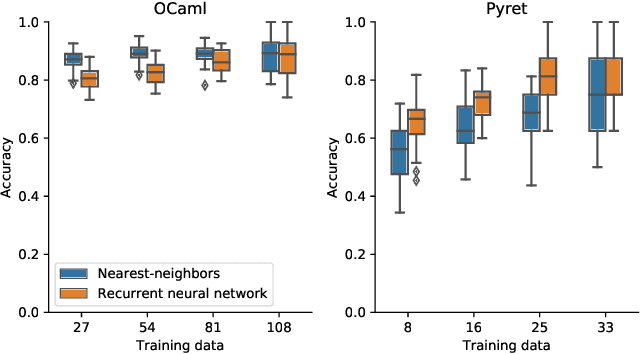
When students write programs, their program structure provides insight into their learning process. However, analyzing program structure by hand is time-consuming, and teachers need better tools for computer-assisted exploration of student solutions. As a first step towards an education-oriented program analysis toolkit, we show how supervised machine learning methods can automatically classify student programs into a predetermined set of high-level structures. We evaluate two models on classifying student solutions to the Rainfall problem: a nearest-neighbors classifier using syntax tree edit distance and a recurrent neural network. We demonstrate that these models can achieve 91% classification accuracy when trained on 108 programs. We further explore the generality, trade-offs, and failure cases of each model.
Scanner: Efficient Video Analysis at Scale
May 18, 2018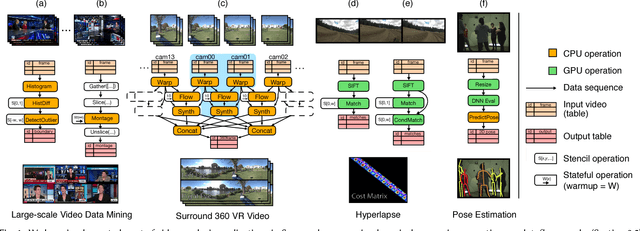
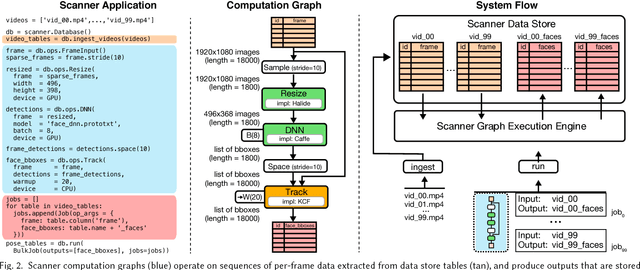
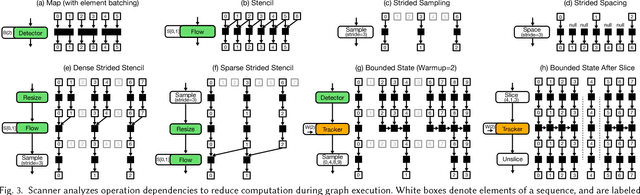
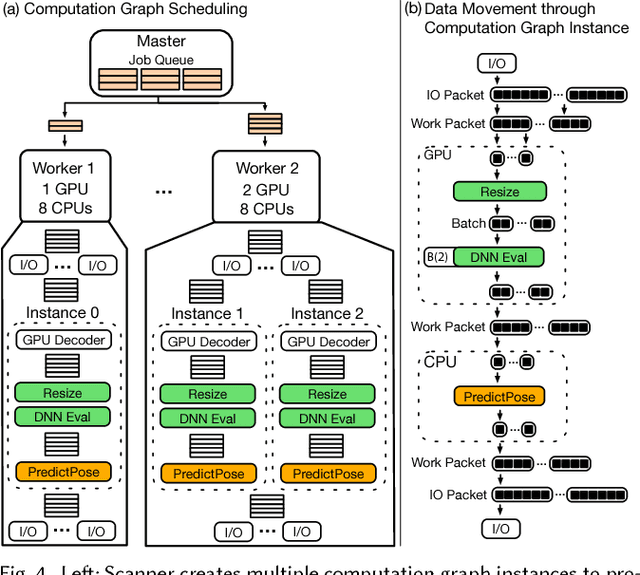
A growing number of visual computing applications depend on the analysis of large video collections. The challenge is that scaling applications to operate on these datasets requires efficient systems for pixel data access and parallel processing across large numbers of machines. Few programmers have the capability to operate efficiently at these scales, limiting the field's ability to explore new applications that leverage big video data. In response, we have created Scanner, a system for productive and efficient video analysis at scale. Scanner organizes video collections as tables in a data store optimized for sampling frames from compressed video, and executes pixel processing computations, expressed as dataflow graphs, on these frames. Scanner schedules video analysis applications expressed using these abstractions onto heterogeneous throughput computing hardware, such as multi-core CPUs, GPUs, and media processing ASICs, for high-throughput pixel processing. We demonstrate the productivity of Scanner by authoring a variety of video processing applications including the synthesis of stereo VR video streams from multi-camera rigs, markerless 3D human pose reconstruction from video, and data-mining big video datasets such as hundreds of feature-length films or over 70,000 hours of TV news. These applications achieve near-expert performance on a single machine and scale efficiently to hundreds of machines, enabling formerly long-running big video data analysis tasks to be carried out in minutes to hours.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
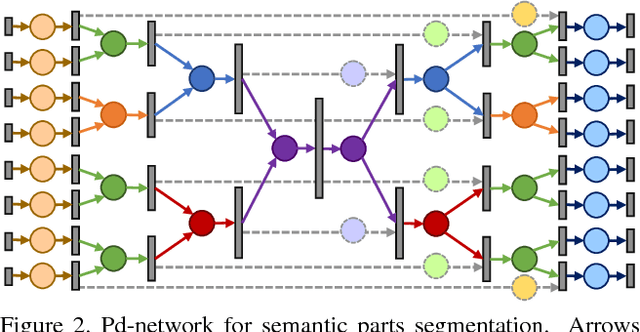
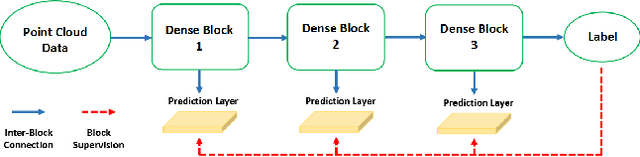
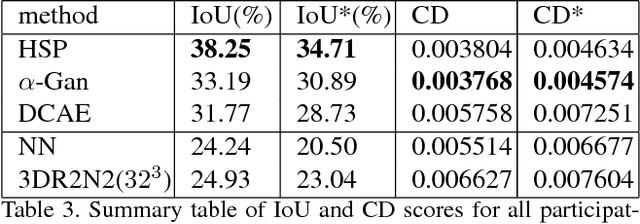
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
Opt: A Domain Specific Language for Non-linear Least Squares Optimization in Graphics and Imaging
Sep 09, 2017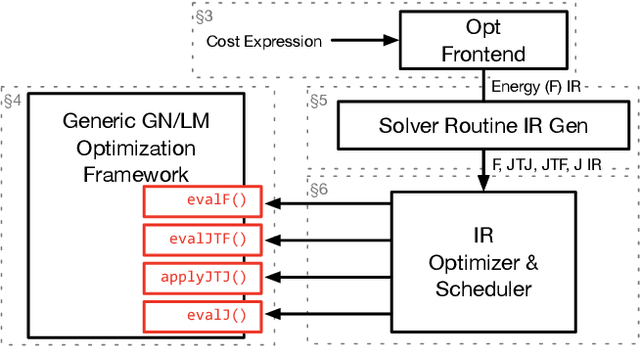



Many graphics and vision problems can be expressed as non-linear least squares optimizations of objective functions over visual data, such as images and meshes. The mathematical descriptions of these functions are extremely concise, but their implementation in real code is tedious, especially when optimized for real-time performance on modern GPUs in interactive applications. In this work, we propose a new language, Opt (available under http://optlang.org), for writing these objective functions over image- or graph-structured unknowns concisely and at a high level. Our compiler automatically transforms these specifications into state-of-the-art GPU solvers based on Gauss-Newton or Levenberg-Marquardt methods. Opt can generate different variations of the solver, so users can easily explore tradeoffs in numerical precision, matrix-free methods, and solver approaches. In our results, we implement a variety of real-world graphics and vision applications. Their energy functions are expressible in tens of lines of code, and produce highly-optimized GPU solver implementations. These solver have performance competitive with the best published hand-tuned, application-specific GPU solvers, and orders of magnitude beyond a general-purpose auto-generated solver.
Submodular Trajectory Optimization for Aerial 3D Scanning
Aug 04, 2017
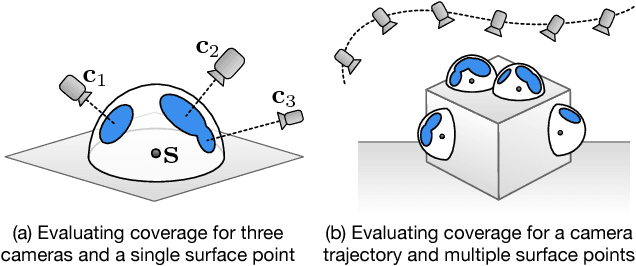
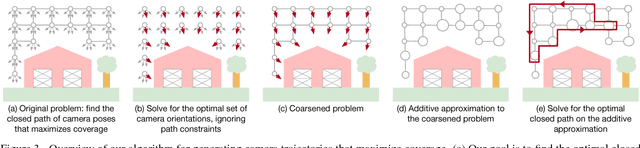

Drones equipped with cameras are emerging as a powerful tool for large-scale aerial 3D scanning, but existing automatic flight planners do not exploit all available information about the scene, and can therefore produce inaccurate and incomplete 3D models. We present an automatic method to generate drone trajectories, such that the imagery acquired during the flight will later produce a high-fidelity 3D model. Our method uses a coarse estimate of the scene geometry to plan camera trajectories that: (1) cover the scene as thoroughly as possible; (2) encourage observations of scene geometry from a diverse set of viewing angles; (3) avoid obstacles; and (4) respect a user-specified flight time budget. Our method relies on a mathematical model of scene coverage that exhibits an intuitive diminishing returns property known as submodularity. We leverage this property extensively to design a trajectory planning algorithm that reasons globally about the non-additive coverage reward obtained across a trajectory, jointly with the cost of traveling between views. We evaluate our method by using it to scan three large outdoor scenes, and we perform a quantitative evaluation using a photorealistic video game simulator.
Neurally-Guided Procedural Models: Amortized Inference for Procedural Graphics Programs using Neural Networks
Oct 13, 2016
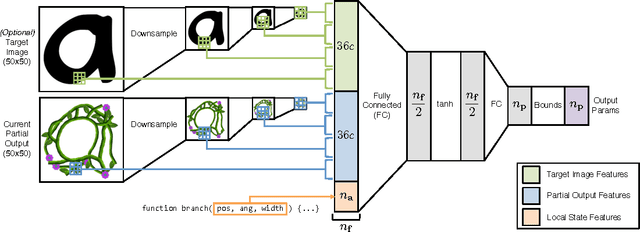
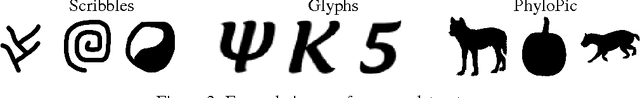

Probabilistic inference algorithms such as Sequential Monte Carlo (SMC) provide powerful tools for constraining procedural models in computer graphics, but they require many samples to produce desirable results. In this paper, we show how to create procedural models which learn how to satisfy constraints. We augment procedural models with neural networks which control how the model makes random choices based on the output it has generated thus far. We call such models neurally-guided procedural models. As a pre-computation, we train these models to maximize the likelihood of example outputs generated via SMC. They are then used as efficient SMC importance samplers, generating high-quality results with very few samples. We evaluate our method on L-system-like models with image-based constraints. Given a desired quality threshold, neurally-guided models can generate satisfactory results up to 10x faster than unguided models.
Towards a Drone Cinematographer: Guiding Quadrotor Cameras using Visual Composition Principles
Oct 05, 2016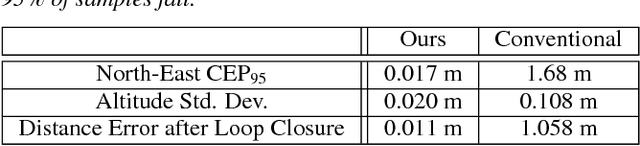

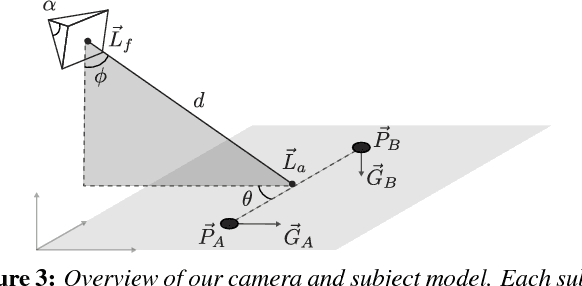
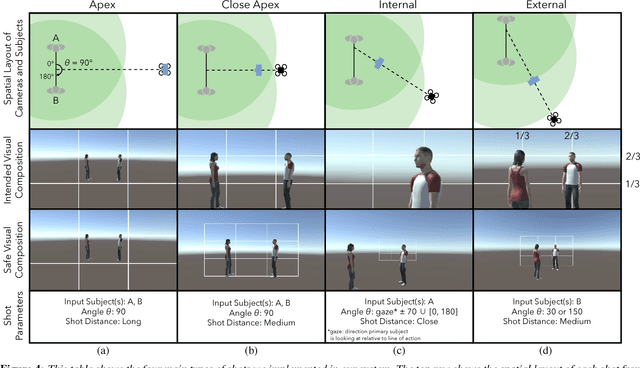
We present a system to capture video footage of human subjects in the real world. Our system leverages a quadrotor camera to automatically capture well-composed video of two subjects. Subjects are tracked in a large-scale outdoor environment using RTK GPS and IMU sensors. Then, given the tracked state of our subjects, our system automatically computes static shots based on well-established visual composition principles and canonical shots from cinematography literature. To transition between these static shots, we calculate feasible, safe, and visually pleasing transitions using a novel real-time trajectory planning algorithm. We evaluate the performance of our tracking system, and experimentally show that RTK GPS significantly outperforms conventional GPS in capturing a variety of canonical shots. Lastly, we demonstrate our system guiding a consumer quadrotor camera autonomously capturing footage of two subjects in a variety of use cases. This is the first end-to-end system that enables people to leverage the mobility of quadrotors, as well as the knowledge of expert filmmakers, to autonomously capture high-quality footage of people in the real world.
ShapeNet: An Information-Rich 3D Model Repository
Dec 09, 2015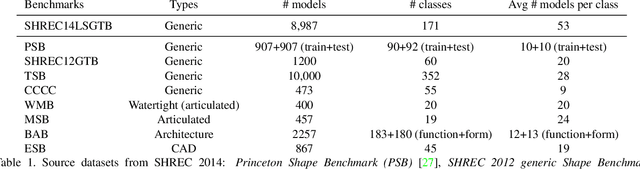
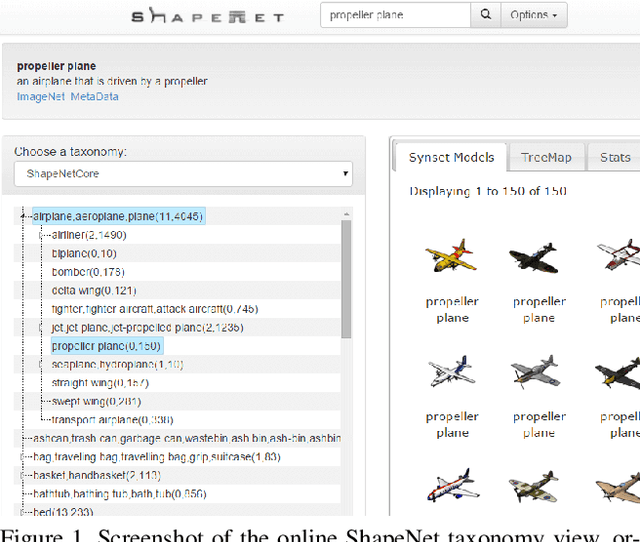
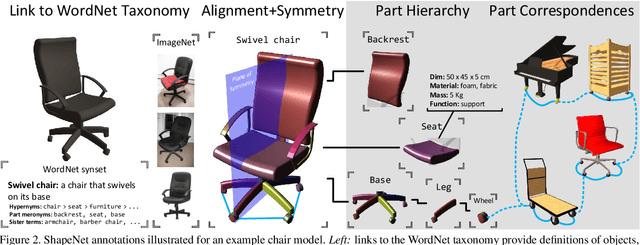
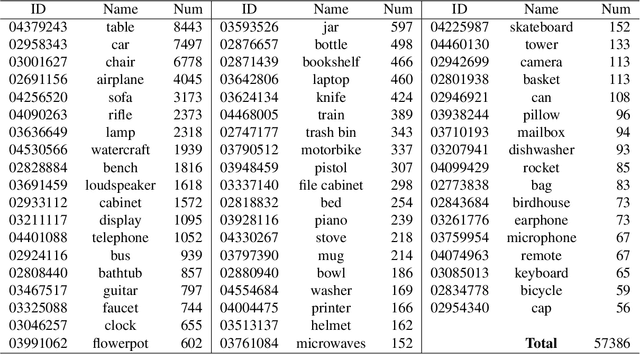
We present ShapeNet: a richly-annotated, large-scale repository of shapes represented by 3D CAD models of objects. ShapeNet contains 3D models from a multitude of semantic categories and organizes them under the WordNet taxonomy. It is a collection of datasets providing many semantic annotations for each 3D model such as consistent rigid alignments, parts and bilateral symmetry planes, physical sizes, keywords, as well as other planned annotations. Annotations are made available through a public web-based interface to enable data visualization of object attributes, promote data-driven geometric analysis, and provide a large-scale quantitative benchmark for research in computer graphics and vision. At the time of this technical report, ShapeNet has indexed more than 3,000,000 models, 220,000 models out of which are classified into 3,135 categories (WordNet synsets). In this report we describe the ShapeNet effort as a whole, provide details for all currently available datasets, and summarize future plans.