 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Jan 26, 2026Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and environmental factors. Existing methods often struggle to maintain global directional consistency, leading to drifting or implausible trajectories when extrapolated over long time horizons. To address this issue, we propose a semantic-key-point-conditioned trajectory modeling framework, in which future trajectories are predicted by conditioning on a high-level Next Key Point (NKP) that captures navigational intent. This formulation decomposes long-horizon prediction into global semantic decision-making and local motion modeling, effectively restricting the support of future trajectories to semantically feasible subsets. To efficiently estimate the NKP prior from historical observations, we adopt a pretrain-finetune strategy. Extensive experiments on real-world AIS data demonstrate that the proposed method consistently outperforms state-of-the-art approaches, particularly for long travel durations, directional accuracy, and fine-grained trajectory prediction.
Deep Residual Shrinkage Networks for EMG-based Gesture Identification
Feb 08, 2022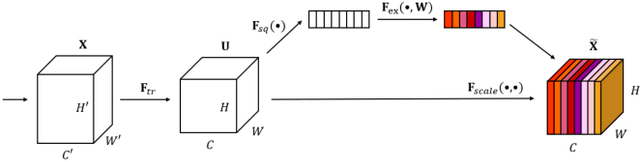
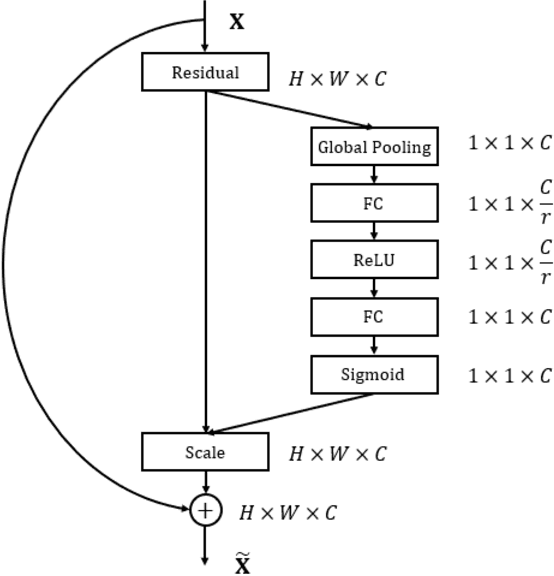
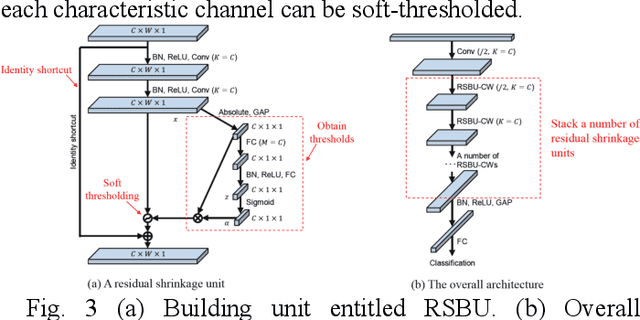
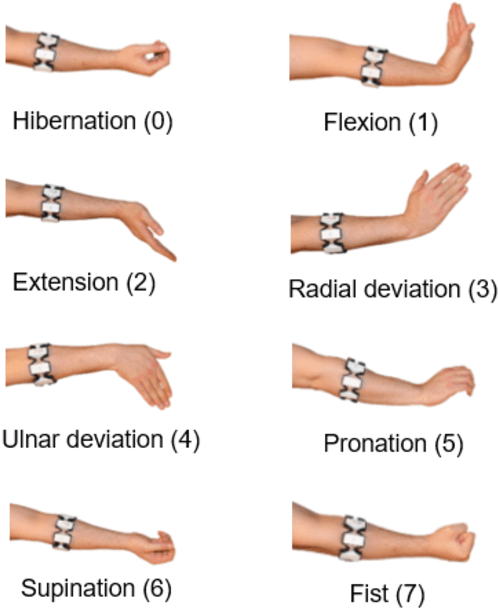
This work introduces a method for high-accuracy EMG based gesture identification. A newly developed deep learning method, namely, deep residual shrinkage network is applied to perform gesture identification. Based on the feature of EMG signal resulting from gestures, optimizations are made to improve the identification accuracy. Finally, three different algorithms are applied to compare the accuracy of EMG signal recognition with that of DRSN. The result shows that DRSN excel traditional neural networks in terms of EMG recognition accuracy. This paper provides a reliable way to classify EMG signals, as well as exploring possible applications of DRSN.
Fully Convolutional Mesh Autoencoder using Efficient Spatially Varying Kernels
Jun 08, 2020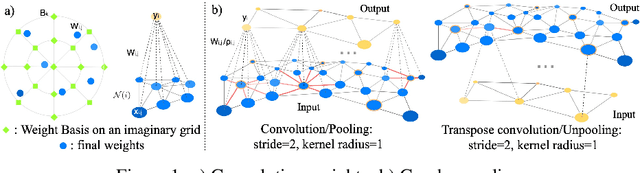
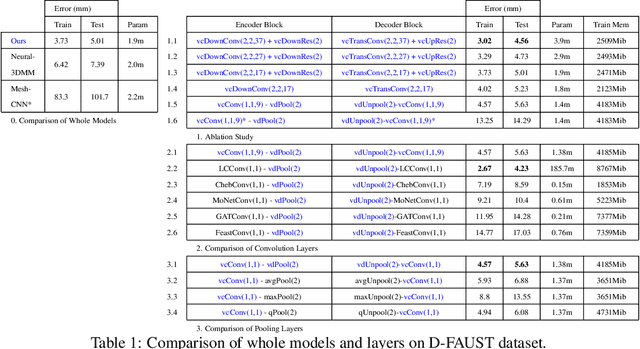
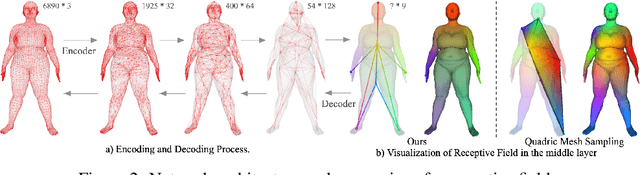
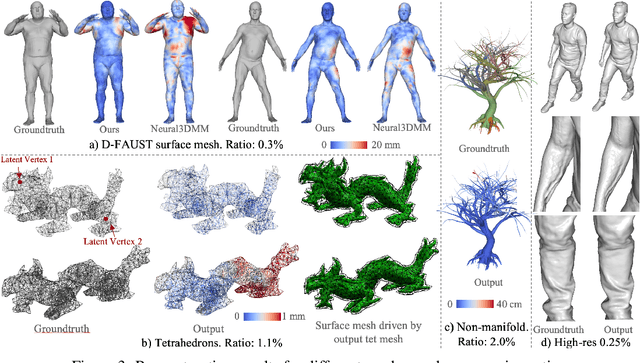
Learning latent representations of registered meshes is useful for many 3D tasks. Techniques have recently shifted to neural mesh autoencoders. Although they demonstrate higher precision than traditional methods, they remain unable to capture fine-grained deformations. Furthermore, these methods can only be applied to a template-specific surface mesh, and is not applicable to more general meshes, like tetrahedrons and non-manifold meshes. While more general graph convolution methods can be employed, they lack performance in reconstruction precision and require higher memory usage. In this paper, we propose a non-template-specific fully convolutional mesh autoencoder for arbitrary registered mesh data. It is enabled by our novel convolution and (un)pooling operators learned with globally shared weights and locally varying coefficients which can efficiently capture the spatially varying contents presented by irregular mesh connections. Our model outperforms state-of-the-art methods on reconstruction accuracy. In addition, the latent codes of our network are fully localized thanks to the fully convolutional structure, and thus have much higher interpolation capability than many traditional 3D mesh generation models.
Auto-Conditioned Recurrent Networks for Extended Complex Human Motion Synthesis
Jul 09, 2018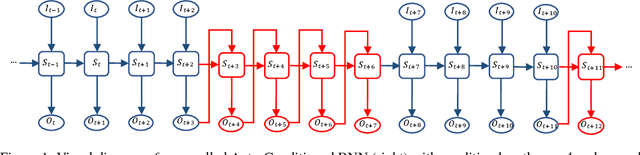
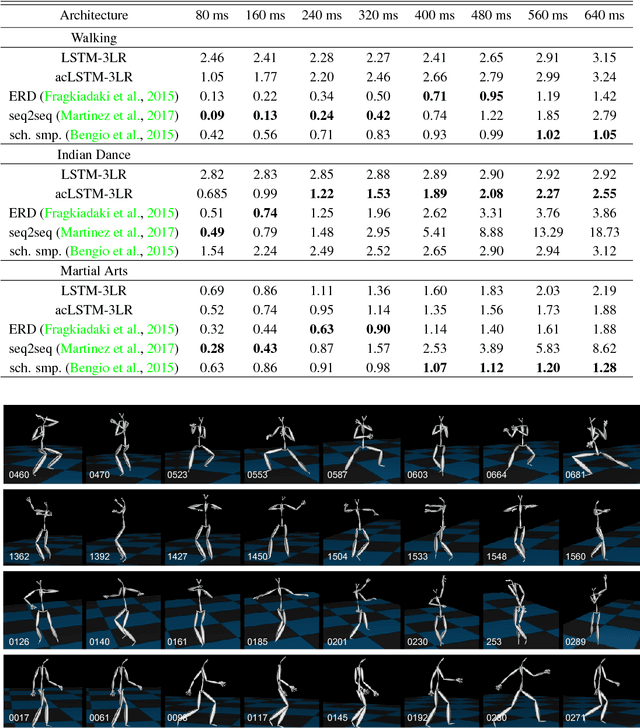
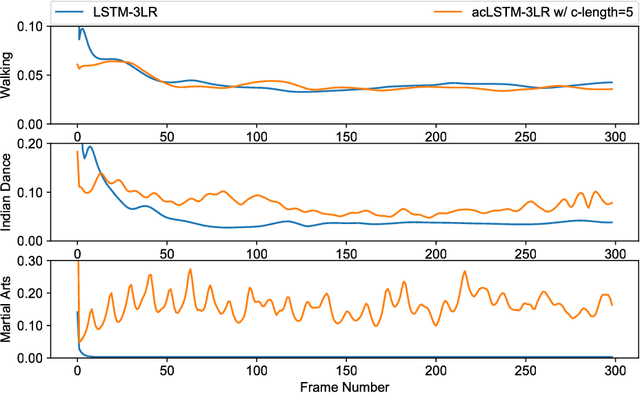
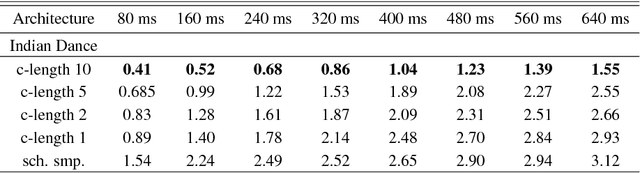
We present a real-time method for synthesizing highly complex human motions using a novel training regime we call the auto-conditioned Recurrent Neural Network (acRNN). Recently, researchers have attempted to synthesize new motion by using autoregressive techniques, but existing methods tend to freeze or diverge after a couple of seconds due to an accumulation of errors that are fed back into the network. Furthermore, such methods have only been shown to be reliable for relatively simple human motions, such as walking or running. In contrast, our approach can synthesize arbitrary motions with highly complex styles, including dances or martial arts in addition to locomotion. The acRNN is able to accomplish this by explicitly accommodating for autoregressive noise accumulation during training. Our work is the first to our knowledge that demonstrates the ability to generate over 18,000 continuous frames (300 seconds) of new complex human motion w.r.t. different styles.
Symmetry-aware Depth Estimation using Deep Neural Networks
Jun 09, 2016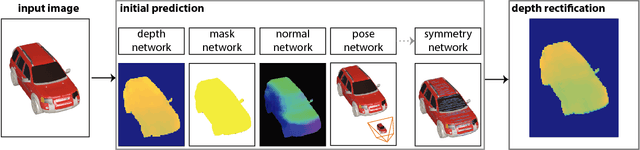
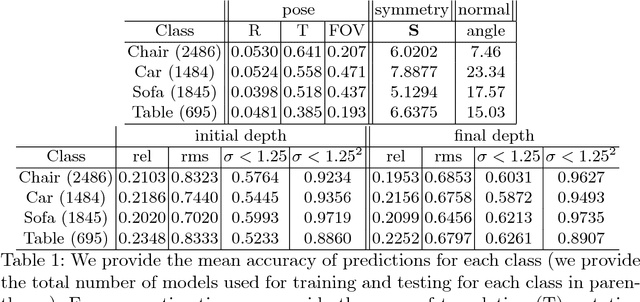


Due to the abundance of 2D product images from the Internet, developing efficient and scalable algorithms to recover the missing depth information is central to many applications. Recent works have addressed the single-view depth estimation problem by utilizing convolutional neural networks. In this paper, we show that exploring symmetry information, which is ubiquitous in man made objects, can significantly boost the quality of such depth predictions. Specifically, we propose a new convolutional neural network architecture to first estimate dense symmetric correspondences in a product image and then propose an optimization which utilizes this information explicitly to significantly improve the quality of single-view depth estimations. We have evaluated our approach extensively, and experimental results show that this approach outperforms state-of-the-art depth estimation techniques.
ShapeNet: An Information-Rich 3D Model Repository
Dec 09, 2015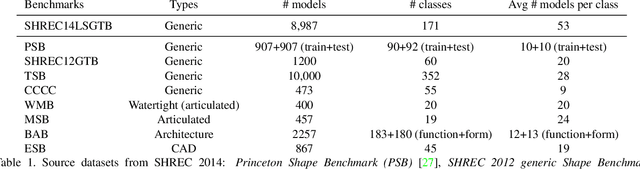
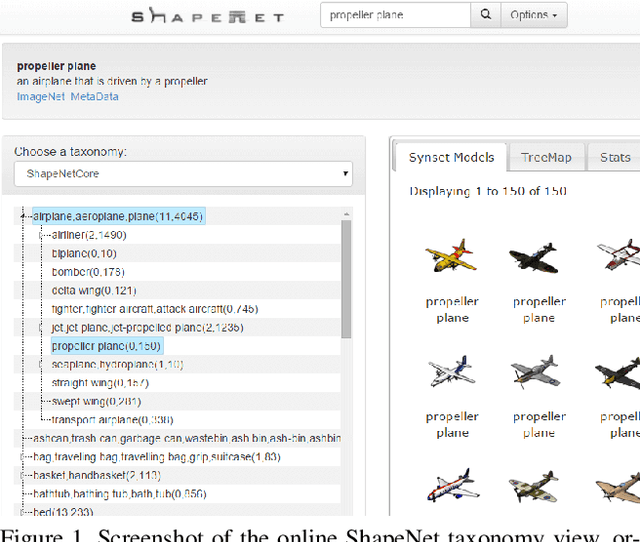
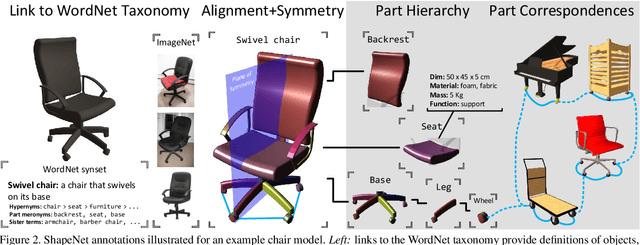
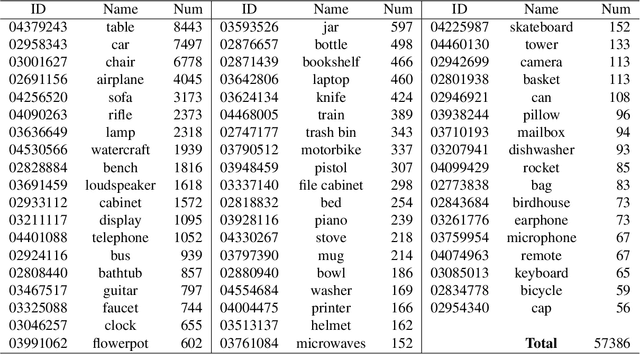
We present ShapeNet: a richly-annotated, large-scale repository of shapes represented by 3D CAD models of objects. ShapeNet contains 3D models from a multitude of semantic categories and organizes them under the WordNet taxonomy. It is a collection of datasets providing many semantic annotations for each 3D model such as consistent rigid alignments, parts and bilateral symmetry planes, physical sizes, keywords, as well as other planned annotations. Annotations are made available through a public web-based interface to enable data visualization of object attributes, promote data-driven geometric analysis, and provide a large-scale quantitative benchmark for research in computer graphics and vision. At the time of this technical report, ShapeNet has indexed more than 3,000,000 models, 220,000 models out of which are classified into 3,135 categories (WordNet synsets). In this report we describe the ShapeNet effort as a whole, provide details for all currently available datasets, and summarize future plans.