 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboStream: Weaving Spatio-Temporal Reasoning with Memory in Vision-Language Models for Robotics
Mar 13, 2026Enabling reliable long-horizon robotic manipulation is a crucial step toward open-world embodied intelligence. However, VLM-based planners treat each step as an isolated observation-to-action mapping, forcing them to reinfer scene geometry from raw pixels at every decision point while remaining unaware of how prior actions have reshaped the environment. Despite strong short-horizon performance, these systems lack the spatio-temporal reasoning required for persistent geometric anchoring and memory of action-triggered state transitions. Without persistent state tracking, perceptual errors accumulate across the execution horizon, temporarily occluded objects are catastrophically forgotten, and these compounding failures lead to precondition violations that cascade through subsequent steps. In contrast, humans maintain a persistent mental model that continuously tracks spatial relations and action consequences across interactions rather than reconstructing them at each instant. Inspired by this human capacity for causal spatio-temporal reasoning with persistent memory, we propose RoboStream, a training-free framework that achieves geometric anchoring through Spatio-Temporal Fusion Tokens (STF-Tokens), which bind visual evidence to 3D geometric attributes for persistent object grounding, and maintains causal continuity via a Causal Spatio-Temporal Graph (CSTG) that records action-triggered state transitions across steps. This design enables the planner to trace causal chains and preserve object permanence under occlusion without additional training or fine-tuning. RoboStream achieves 90.5% on long-horizon RLBench and 44.4% on challenging real-world block-building tasks, where both SoFar and VoxPoser score 11.1%, demonstrating that spatio-temporal reasoning and causal memory are critical missing components for reliable long-horizon manipulation.
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
Learning to Stabilize Faces
Nov 22, 2024Nowadays, it is possible to scan faces and automatically register them with high quality. However, the resulting face meshes often need further processing: we need to stabilize them to remove unwanted head movement. Stabilization is important for tasks like game development or movie making which require facial expressions to be cleanly separated from rigid head motion. Since manual stabilization is labor-intensive, there have been attempts to automate it. However, previous methods remain impractical: they either still require some manual input, produce imprecise alignments, rely on dubious heuristics and slow optimization, or assume a temporally ordered input. Instead, we present a new learning-based approach that is simple and fully automatic. We treat stabilization as a regression problem: given two face meshes, our network directly predicts the rigid transform between them that brings their skulls into alignment. We generate synthetic training data using a 3D Morphable Model (3DMM), exploiting the fact that 3DMM parameters separate skull motion from facial skin motion. Through extensive experiments we show that our approach outperforms the state-of-the-art both quantitatively and qualitatively on the tasks of stabilizing discrete sets of facial expressions as well as dynamic facial performances. Furthermore, we provide an ablation study detailing the design choices and best practices to help others adopt our approach for their own uses. Supplementary videos can be found on the project webpage syntec-research.github.io/FaceStab.
FabricDiffusion: High-Fidelity Texture Transfer for 3D Garments Generation from In-The-Wild Clothing Images
Oct 02, 2024

We introduce FabricDiffusion, a method for transferring fabric textures from a single clothing image to 3D garments of arbitrary shapes. Existing approaches typically synthesize textures on the garment surface through 2D-to-3D texture mapping or depth-aware inpainting via generative models. Unfortunately, these methods often struggle to capture and preserve texture details, particularly due to challenging occlusions, distortions, or poses in the input image. Inspired by the observation that in the fashion industry, most garments are constructed by stitching sewing patterns with flat, repeatable textures, we cast the task of clothing texture transfer as extracting distortion-free, tileable texture materials that are subsequently mapped onto the UV space of the garment. Building upon this insight, we train a denoising diffusion model with a large-scale synthetic dataset to rectify distortions in the input texture image. This process yields a flat texture map that enables a tight coupling with existing Physically-Based Rendering (PBR) material generation pipelines, allowing for realistic relighting of the garment under various lighting conditions. We show that FabricDiffusion can transfer various features from a single clothing image including texture patterns, material properties, and detailed prints and logos. Extensive experiments demonstrate that our model significantly outperforms state-to-the-art methods on both synthetic data and real-world, in-the-wild clothing images while generalizing to unseen textures and garment shapes.
Authentic Hand Avatar from a Phone Scan via Universal Hand Model
May 13, 2024


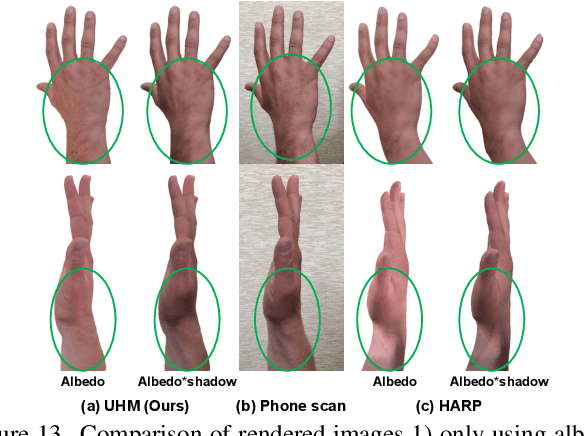
The authentic 3D hand avatar with every identifiable information, such as hand shapes and textures, is necessary for immersive experiences in AR/VR. In this paper, we present a universal hand model (UHM), which 1) can universally represent high-fidelity 3D hand meshes of arbitrary identities (IDs) and 2) can be adapted to each person with a short phone scan for the authentic hand avatar. For effective universal hand modeling, we perform tracking and modeling at the same time, while previous 3D hand models perform them separately. The conventional separate pipeline suffers from the accumulated errors from the tracking stage, which cannot be recovered in the modeling stage. On the other hand, ours does not suffer from the accumulated errors while having a much more concise overall pipeline. We additionally introduce a novel image matching loss function to address a skin sliding during the tracking and modeling, while existing works have not focused on it much. Finally, using learned priors from our UHM, we effectively adapt our UHM to each person's short phone scan for the authentic hand avatar.
Diffusion Shape Prior for Wrinkle-Accurate Cloth Registration
Nov 10, 2023



Registering clothes from 4D scans with vertex-accurate correspondence is challenging, yet important for dynamic appearance modeling and physics parameter estimation from real-world data. However, previous methods either rely on texture information, which is not always reliable, or achieve only coarse-level alignment. In this work, we present a novel approach to enabling accurate surface registration of texture-less clothes with large deformation. Our key idea is to effectively leverage a shape prior learned from pre-captured clothing using diffusion models. We also propose a multi-stage guidance scheme based on learned functional maps, which stabilizes registration for large-scale deformation even when they vary significantly from training data. Using high-fidelity real captured clothes, our experiments show that the proposed approach based on diffusion models generalizes better than surface registration with VAE or PCA-based priors, outperforming both optimization-based and learning-based non-rigid registration methods for both interpolation and extrapolation tests.
Drivable Avatar Clothing: Faithful Full-Body Telepresence with Dynamic Clothing Driven by Sparse RGB-D Input
Oct 11, 2023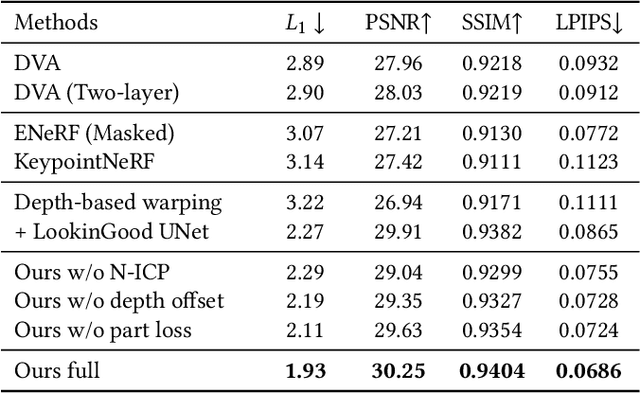


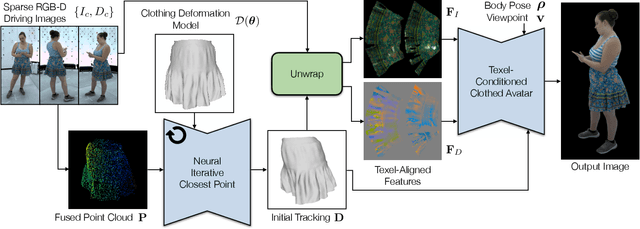
Clothing is an important part of human appearance but challenging to model in photorealistic avatars. In this work we present avatars with dynamically moving loose clothing that can be faithfully driven by sparse RGB-D inputs as well as body and face motion. We propose a Neural Iterative Closest Point (N-ICP) algorithm that can efficiently track the coarse garment shape given sparse depth input. Given the coarse tracking results, the input RGB-D images are then remapped to texel-aligned features, which are fed into the drivable avatar models to faithfully reconstruct appearance details. We evaluate our method against recent image-driven synthesis baselines, and conduct a comprehensive analysis of the N-ICP algorithm. We demonstrate that our method can generalize to a novel testing environment, while preserving the ability to produce high-fidelity and faithful clothing dynamics and appearance.
Neural Strands: Learning Hair Geometry and Appearance from Multi-View Images
Jul 28, 2022

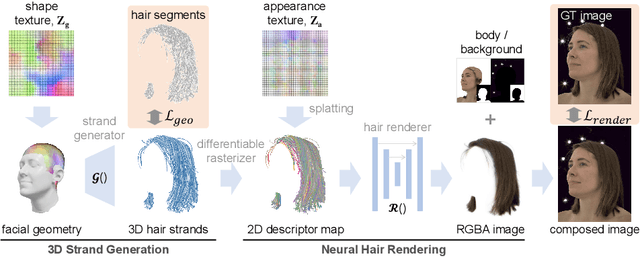
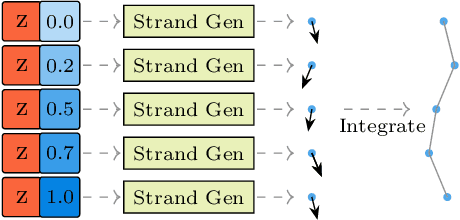
We present Neural Strands, a novel learning framework for modeling accurate hair geometry and appearance from multi-view image inputs. The learned hair model can be rendered in real-time from any viewpoint with high-fidelity view-dependent effects. Our model achieves intuitive shape and style control unlike volumetric counterparts. To enable these properties, we propose a novel hair representation based on a neural scalp texture that encodes the geometry and appearance of individual strands at each texel location. Furthermore, we introduce a novel neural rendering framework based on rasterization of the learned hair strands. Our neural rendering is strand-accurate and anti-aliased, making the rendering view-consistent and photorealistic. Combining appearance with a multi-view geometric prior, we enable, for the first time, the joint learning of appearance and explicit hair geometry from a multi-view setup. We demonstrate the efficacy of our approach in terms of fidelity and efficiency for various hairstyles.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
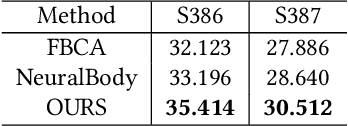
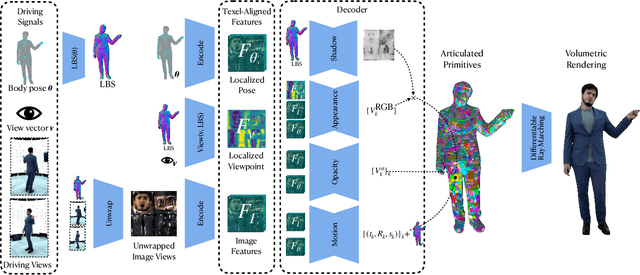
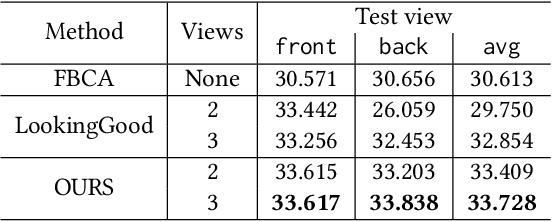
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.