 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
URHand: Universal Relightable Hands
Jan 10, 2024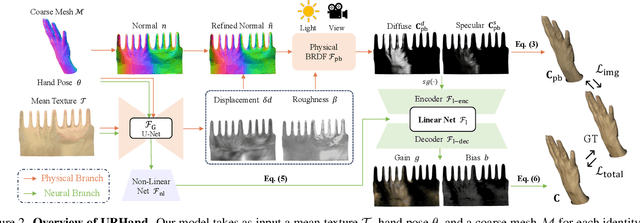
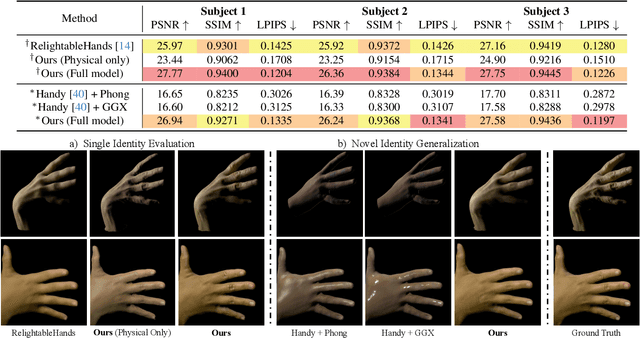
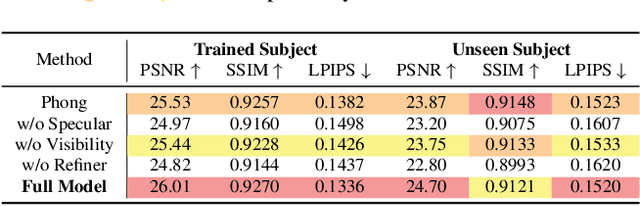
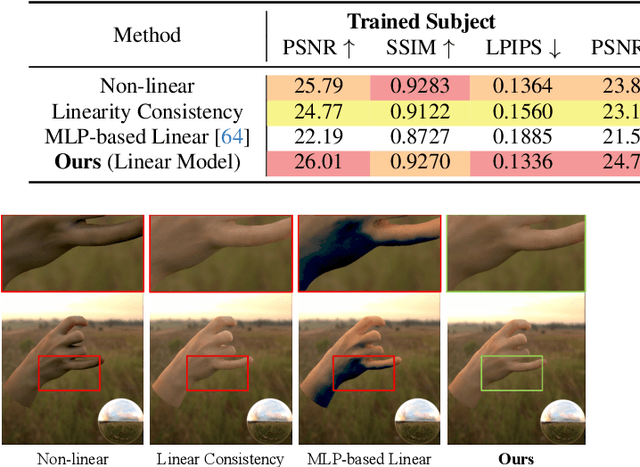
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
CodedStereo: Learned Phase Masks for Large Depth-of-field Stereo
Apr 09, 2021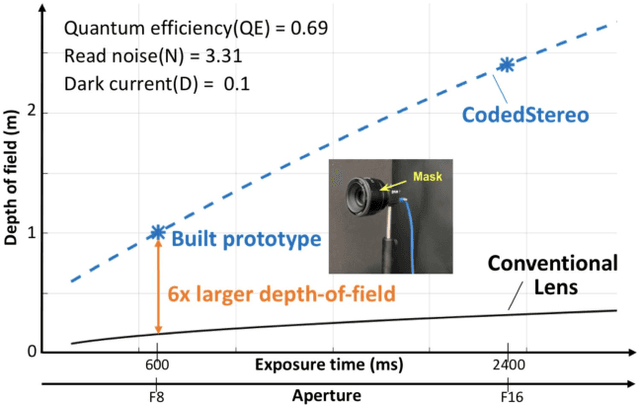
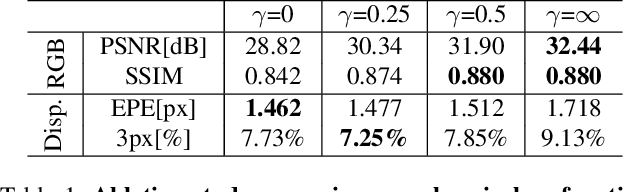
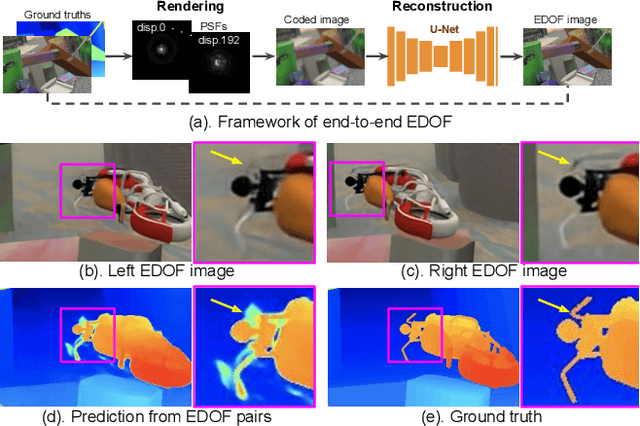
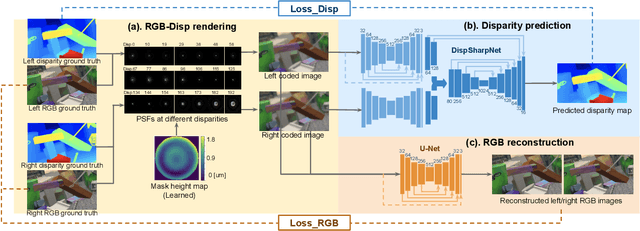
Conventional stereo suffers from a fundamental trade-off between imaging volume and signal-to-noise ratio (SNR) -- due to the conflicting impact of aperture size on both these variables. Inspired by the extended depth of field cameras, we propose a novel end-to-end learning-based technique to overcome this limitation, by introducing a phase mask at the aperture plane of the cameras in a stereo imaging system. The phase mask creates a depth-dependent point spread function, allowing us to recover sharp image texture and stereo correspondence over a significantly extended depth of field (EDOF) than conventional stereo. The phase mask pattern, the EDOF image reconstruction, and the stereo disparity estimation are all trained together using an end-to-end learned deep neural network. We perform theoretical analysis and characterization of the proposed approach and show a 6x increase in volume that can be imaged in simulation. We also build an experimental prototype and validate the approach using real-world results acquired using this prototype system.
Supervision by Registration and Triangulation for Landmark Detection
Jan 25, 2021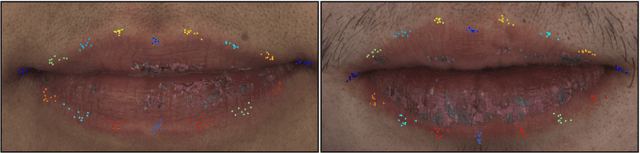

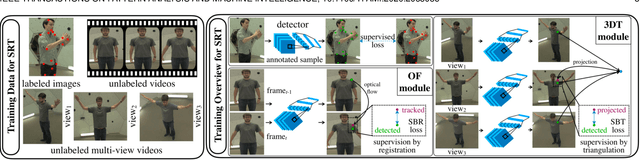
We present Supervision by Registration and Triangulation (SRT), an unsupervised approach that utilizes unlabeled multi-view video to improve the accuracy and precision of landmark detectors. Being able to utilize unlabeled data enables our detectors to learn from massive amounts of unlabeled data freely available and not be limited by the quality and quantity of manual human annotations. To utilize unlabeled data, there are two key observations: (1) the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. (2) the detections of the same landmark in multiple synchronized and geometrically calibrated views should correspond to a single 3D point, i.e., multi-view consistency. Registration and multi-view consistency are sources of supervision that do not require manual labeling, thus it can be leveraged to augment existing training data during detector training. End-to-end training is made possible by differentiable registration and 3D triangulation modules. Experiments with 11 datasets and a newly proposed metric to measure precision demonstrate accuracy and precision improvements in landmark detection on both images and video. Code is available at https://github.com/D-X-Y/landmark-detection.
Epipolar Transformers
May 10, 2020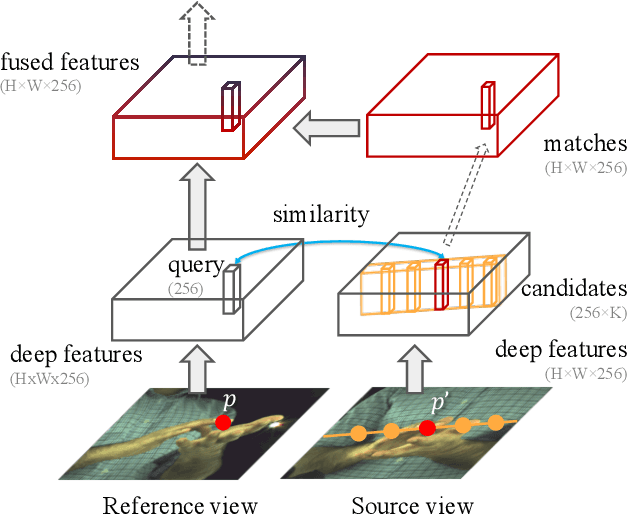
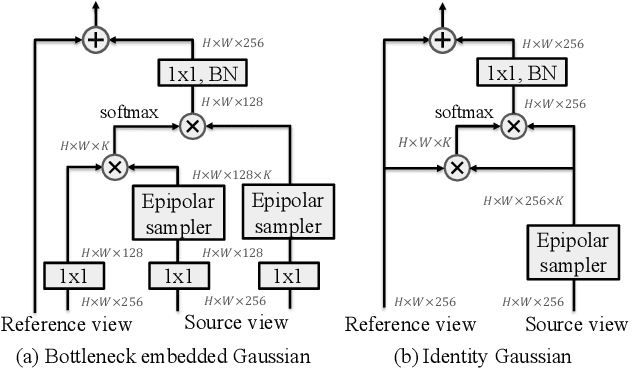


A common approach to localize 3D human joints in a synchronized and calibrated multi-view setup consists of two-steps: (1) apply a 2D detector separately on each view to localize joints in 2D, and (2) perform robust triangulation on 2D detections from each view to acquire the 3D joint locations. However, in step 1, the 2D detector is limited to solving challenging cases which could potentially be better resolved in 3D, such as occlusions and oblique viewing angles, purely in 2D without leveraging any 3D information. Therefore, we propose the differentiable "epipolar transformer", which enables the 2D detector to leverage 3D-aware features to improve 2D pose estimation. The intuition is: given a 2D location p in the current view, we would like to first find its corresponding point p' in a neighboring view, and then combine the features at p' with the features at p, thus leading to a 3D-aware feature at p. Inspired by stereo matching, the epipolar transformer leverages epipolar constraints and feature matching to approximate the features at p'. Experiments on InterHand and Human3.6M show that our approach has consistent improvements over the baselines. Specifically, in the condition where no external data is used, our Human3.6M model trained with ResNet-50 backbone and image size 256 x 256 outperforms state-of-the-art by 4.23 mm and achieves MPJPE 26.9 mm.
Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking
Jul 25, 2019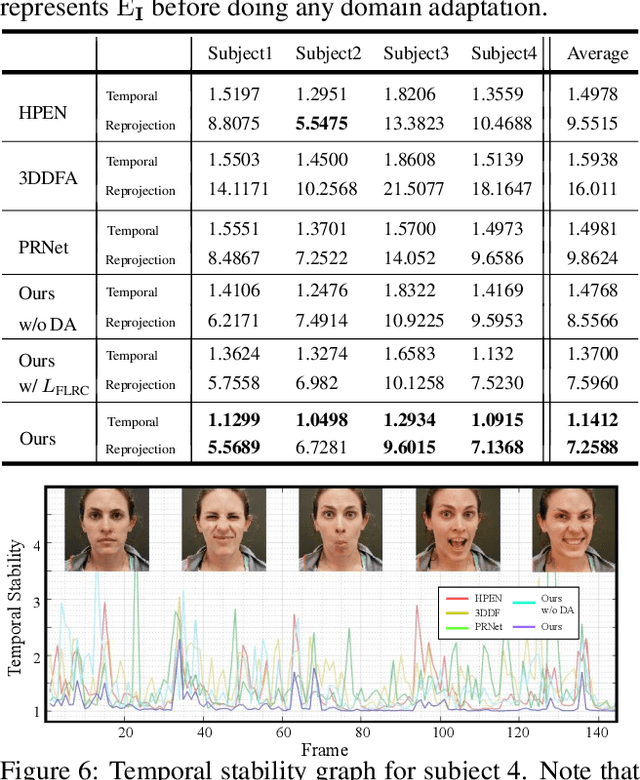
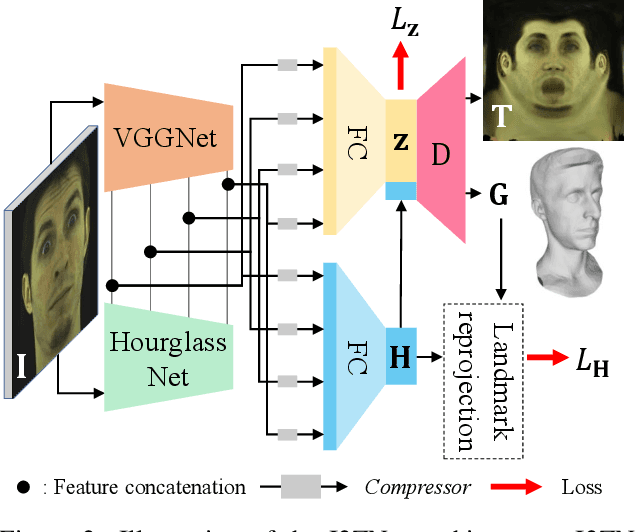
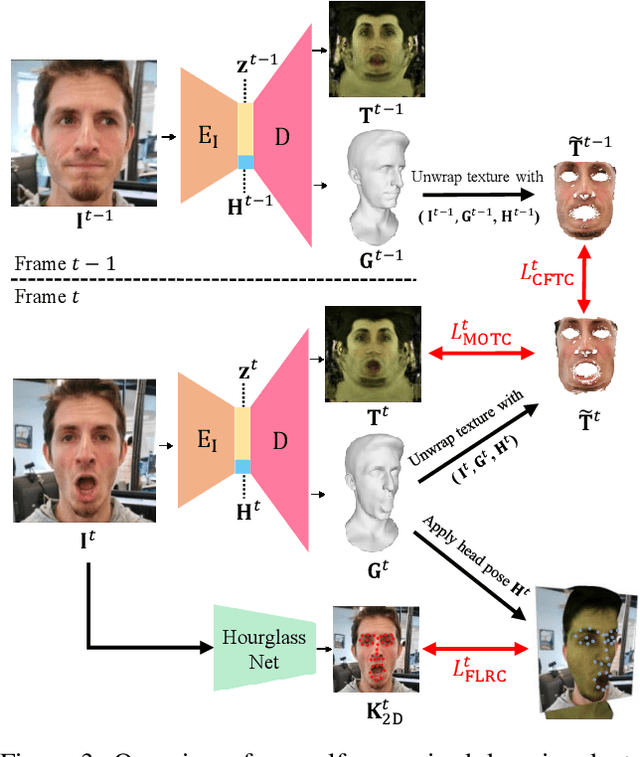
Improvements in data-capture and face modeling techniques have enabled us to create high-fidelity realistic face models. However, driving these realistic face models requires special input data, e.g. 3D meshes and unwrapped textures. Also, these face models expect clean input data taken under controlled lab environments, which is very different from data collected in the wild. All these constraints make it challenging to use the high-fidelity models in tracking for commodity cameras. In this paper, we propose a self-supervised domain adaptation approach to enable the animation of high-fidelity face models from a commodity camera. Our approach first circumvents the requirement for special input data by training a new network that can directly drive a face model just from a single 2D image. Then, we overcome the domain mismatch between lab and uncontrolled environments by performing self-supervised domain adaptation based on "consecutive frame texture consistency" based on the assumption that the appearance of the face is consistent over consecutive frames, avoiding the necessity of modeling the new environment such as lighting or background. Experiments show that we are able to drive a high-fidelity face model to perform complex facial motion from a cellphone camera without requiring any labeled data from the new domain.
Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
Jul 04, 2018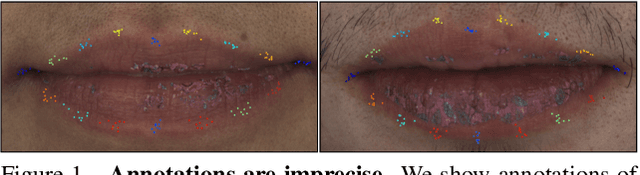
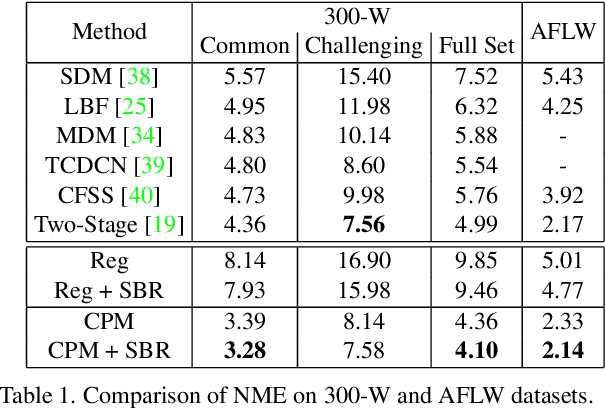
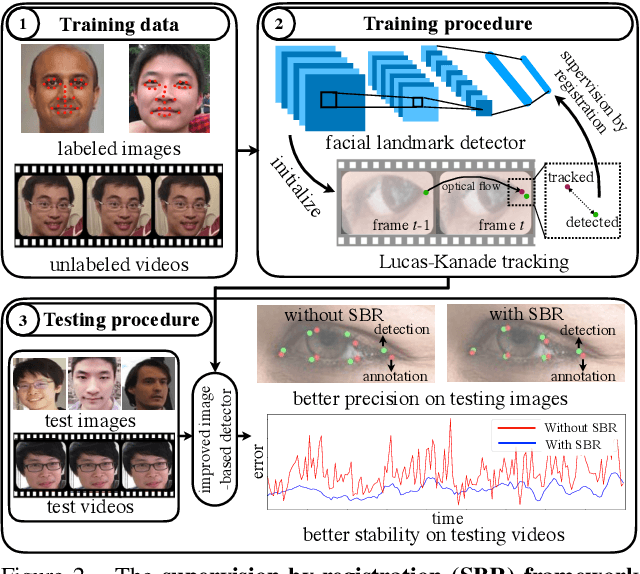
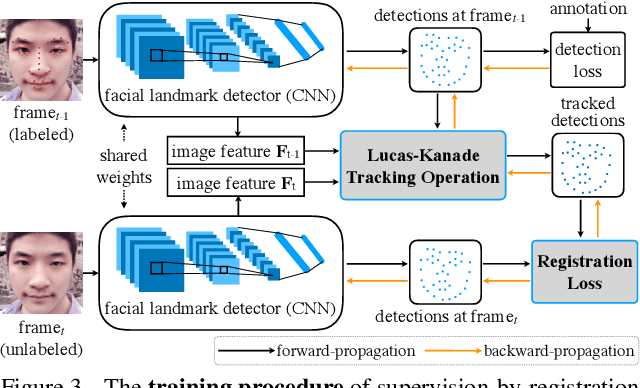
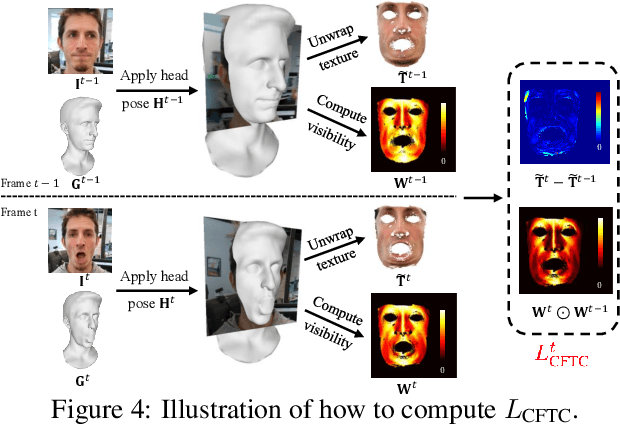
In this paper, we present supervision-by-registration, an unsupervised approach to improve the precision of facial landmark detectors on both images and video. Our key observation is that the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. Interestingly, the coherency of optical flow is a source of supervision that does not require manual labeling, and can be leveraged during detector training. For example, we can enforce in the training loss function that a detected landmark at frame$_{t-1}$ followed by optical flow tracking from frame$_{t-1}$ to frame$_t$ should coincide with the location of the detection at frame$_t$. Essentially, supervision-by-registration augments the training loss function with a registration loss, thus training the detector to have output that is not only close to the annotations in labeled images, but also consistent with registration on large amounts of unlabeled videos. End-to-end training with the registration loss is made possible by a differentiable Lucas-Kanade operation, which computes optical flow registration in the forward pass, and back-propagates gradients that encourage temporal coherency in the detector. The output of our method is a more precise image-based facial landmark detector, which can be applied to single images or video. With supervision-by-registration, we demonstrate (1) improvements in facial landmark detection on both images (300W, ALFW) and video (300VW, Youtube-Celebrities), and (2) significant reduction of jittering in video detections.
Long-Term Identity-Aware Multi-Person Tracking for Surveillance Video Summarization
Apr 11, 2017
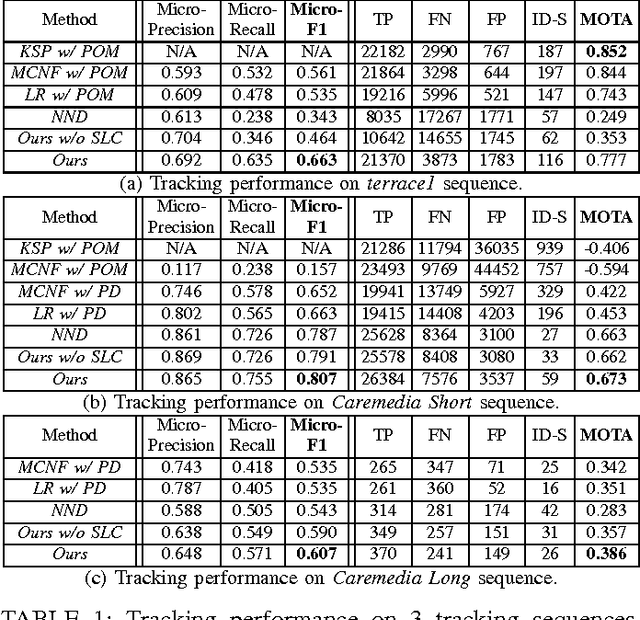

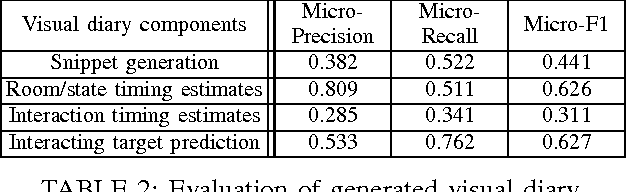
Multi-person tracking plays a critical role in the analysis of surveillance video. However, most existing work focus on shorter-term (e.g. minute-long or hour-long) video sequences. Therefore, we propose a multi-person tracking algorithm for very long-term (e.g. month-long) multi-camera surveillance scenarios. Long-term tracking is challenging because 1) the apparel/appearance of the same person will vary greatly over multiple days and 2) a person will leave and re-enter the scene numerous times. To tackle these challenges, we leverage face recognition information, which is robust to apparel change, to automatically reinitialize our tracker over multiple days of recordings. Unfortunately, recognized faces are unavailable oftentimes. Therefore, our tracker propagates identity information to frames without recognized faces by uncovering the appearance and spatial manifold formed by person detections. We tested our algorithm on a 23-day 15-camera data set (4,935 hours total), and we were able to localize a person 53.2% of the time with 69.8% precision. We further performed video summarization experiments based on our tracking output. Results on 116.25 hours of video showed that we were able to generate a reasonable visual diary (i.e. a summary of what a person did) for different people, thus potentially opening the door to automatic summarization of the vast amount of surveillance video generated every day.
Strategies for Searching Video Content with Text Queries or Video Examples
Jun 17, 2016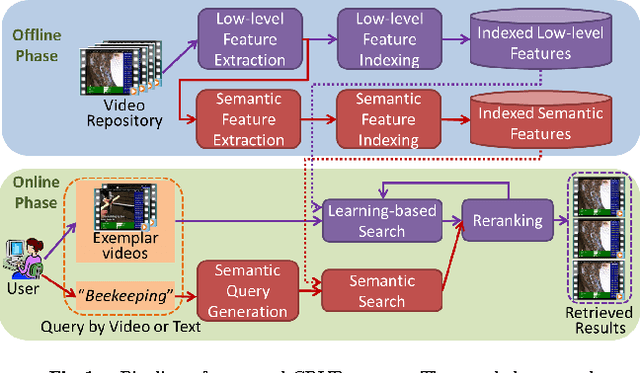



The large number of user-generated videos uploaded on to the Internet everyday has led to many commercial video search engines, which mainly rely on text metadata for search. However, metadata is often lacking for user-generated videos, thus these videos are unsearchable by current search engines. Therefore, content-based video retrieval (CBVR) tackles this metadata-scarcity problem by directly analyzing the visual and audio streams of each video. CBVR encompasses multiple research topics, including low-level feature design, feature fusion, semantic detector training and video search/reranking. We present novel strategies in these topics to enhance CBVR in both accuracy and speed under different query inputs, including pure textual queries and query by video examples. Our proposed strategies have been incorporated into our submission for the TRECVID 2014 Multimedia Event Detection evaluation, where our system outperformed other submissions in both text queries and video example queries, thus demonstrating the effectiveness of our proposed approaches.