 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Identity-Aware Multi-Person Tracking for Surveillance Video Summarization
Apr 11, 2017
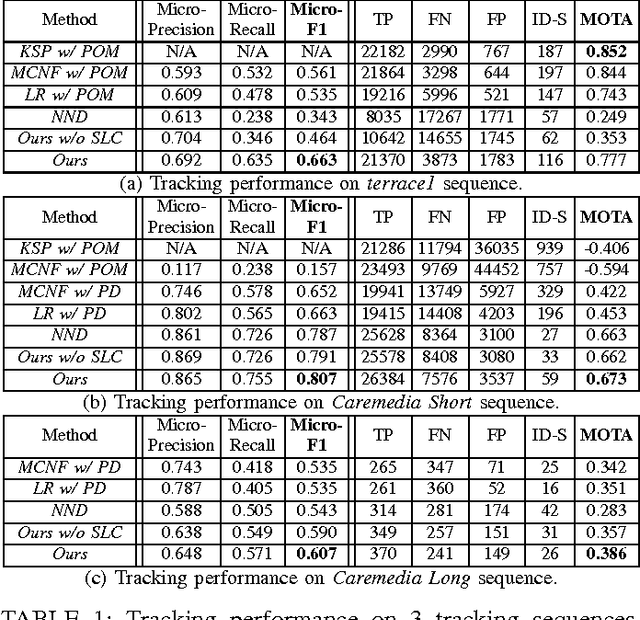

Multi-person tracking plays a critical role in the analysis of surveillance video. However, most existing work focus on shorter-term (e.g. minute-long or hour-long) video sequences. Therefore, we propose a multi-person tracking algorithm for very long-term (e.g. month-long) multi-camera surveillance scenarios. Long-term tracking is challenging because 1) the apparel/appearance of the same person will vary greatly over multiple days and 2) a person will leave and re-enter the scene numerous times. To tackle these challenges, we leverage face recognition information, which is robust to apparel change, to automatically reinitialize our tracker over multiple days of recordings. Unfortunately, recognized faces are unavailable oftentimes. Therefore, our tracker propagates identity information to frames without recognized faces by uncovering the appearance and spatial manifold formed by person detections. We tested our algorithm on a 23-day 15-camera data set (4,935 hours total), and we were able to localize a person 53.2% of the time with 69.8% precision. We further performed video summarization experiments based on our tracking output. Results on 116.25 hours of video showed that we were able to generate a reasonable visual diary (i.e. a summary of what a person did) for different people, thus potentially opening the door to automatic summarization of the vast amount of surveillance video generated every day.
Strategies for Searching Video Content with Text Queries or Video Examples
Jun 17, 2016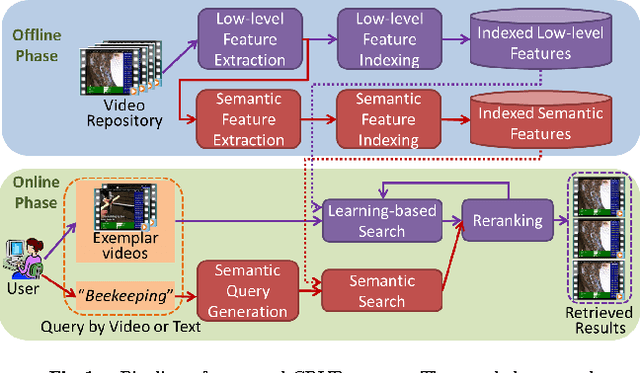



The large number of user-generated videos uploaded on to the Internet everyday has led to many commercial video search engines, which mainly rely on text metadata for search. However, metadata is often lacking for user-generated videos, thus these videos are unsearchable by current search engines. Therefore, content-based video retrieval (CBVR) tackles this metadata-scarcity problem by directly analyzing the visual and audio streams of each video. CBVR encompasses multiple research topics, including low-level feature design, feature fusion, semantic detector training and video search/reranking. We present novel strategies in these topics to enhance CBVR in both accuracy and speed under different query inputs, including pure textual queries and query by video examples. Our proposed strategies have been incorporated into our submission for the TRECVID 2014 Multimedia Event Detection evaluation, where our system outperformed other submissions in both text queries and video example queries, thus demonstrating the effectiveness of our proposed approaches.
Beyond Gaussian Pyramid: Multi-skip Feature Stacking for Action Recognition
Apr 19, 2015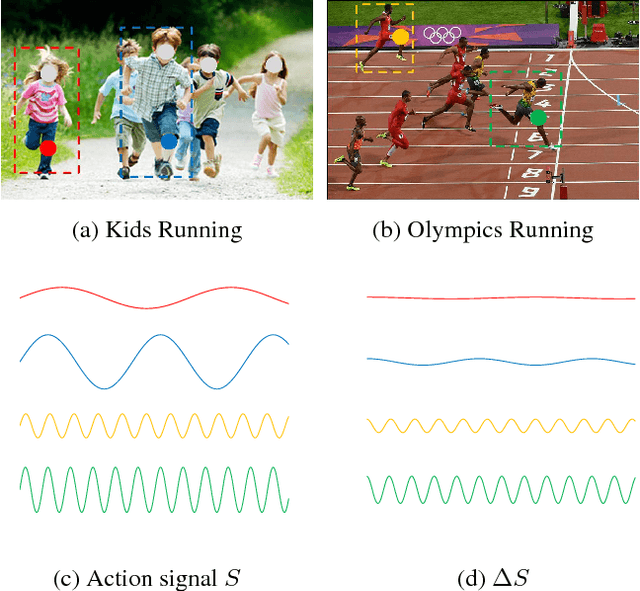
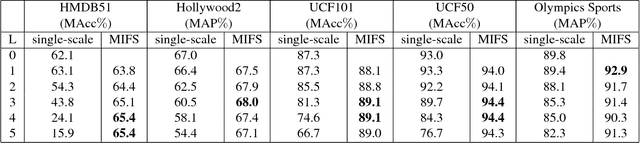
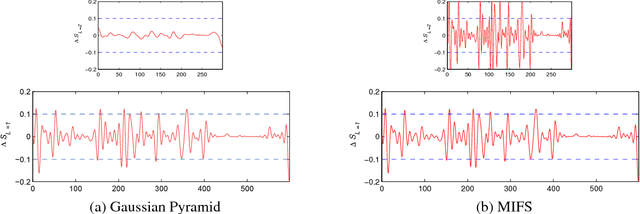

Most state-of-the-art action feature extractors involve differential operators, which act as highpass filters and tend to attenuate low frequency action information. This attenuation introduces bias to the resulting features and generates ill-conditioned feature matrices. The Gaussian Pyramid has been used as a feature enhancing technique that encodes scale-invariant characteristics into the feature space in an attempt to deal with this attenuation. However, at the core of the Gaussian Pyramid is a convolutional smoothing operation, which makes it incapable of generating new features at coarse scales. In order to address this problem, we propose a novel feature enhancing technique called Multi-skIp Feature Stacking (MIFS), which stacks features extracted using a family of differential filters parameterized with multiple time skips and encodes shift-invariance into the frequency space. MIFS compensates for information lost from using differential operators by recapturing information at coarse scales. This recaptured information allows us to match actions at different speeds and ranges of motion. We prove that MIFS enhances the learnability of differential-based features exponentially. The resulting feature matrices from MIFS have much smaller conditional numbers and variances than those from conventional methods. Experimental results show significantly improved performance on challenging action recognition and event detection tasks. Specifically, our method exceeds the state-of-the-arts on Hollywood2, UCF101 and UCF50 datasets and is comparable to state-of-the-arts on HMDB51 and Olympics Sports datasets. MIFS can also be used as a speedup strategy for feature extraction with minimal or no accuracy cost.
Long-short Term Motion Feature for Action Classification and Retrieval
Feb 13, 2015

We propose a method for representing motion information for video classification and retrieval. We improve upon local descriptor based methods that have been among the most popular and successful models for representing videos. The desired local descriptors need to satisfy two requirements: 1) to be representative, 2) to be discriminative. Therefore, they need to occur frequently enough in the videos and to be be able to tell the difference among different types of motions. To generate such local descriptors, the video blocks they are based on must contain just the right amount of motion information. However, current state-of-the-art local descriptor methods use video blocks with a single fixed size, which is insufficient for covering actions with varying speeds. In this paper, we introduce a long-short term motion feature that generates descriptors from video blocks with multiple lengths, thus covering motions with large speed variance. Experimental results show that, albeit simple, our model achieves state-of-the-arts results on several benchmark datasets.
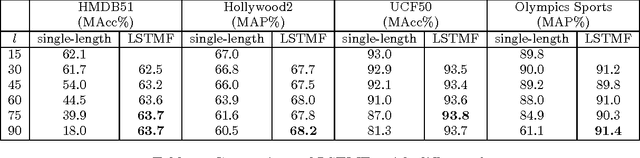
Temporal Extension of Scale Pyramid and Spatial Pyramid Matching for Action Recognition
Aug 29, 2014


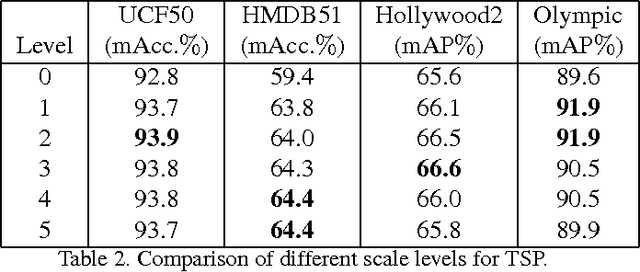
Historically, researchers in the field have spent a great deal of effort to create image representations that have scale invariance and retain spatial location information. This paper proposes to encode equivalent temporal characteristics in video representations for action recognition. To achieve temporal scale invariance, we develop a method called temporal scale pyramid (TSP). To encode temporal information, we present and compare two methods called temporal extension descriptor (TED) and temporal division pyramid (TDP) . Our purpose is to suggest solutions for matching complex actions that have large variation in velocity and appearance, which is missing from most current action representations. The experimental results on four benchmark datasets, UCF50, HMDB51, Hollywood2 and Olympic Sports, support our approach and significantly outperform state-of-the-art methods. Most noticeably, we achieve 65.0% mean accuracy and 68.2% mean average precision on the challenging HMDB51 and Hollywood2 datasets which constitutes an absolute improvement over the state-of-the-art by 7.8% and 3.9%, respectively.