 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Extension of Scale Pyramid and Spatial Pyramid Matching for Action Recognition
Aug 29, 2014


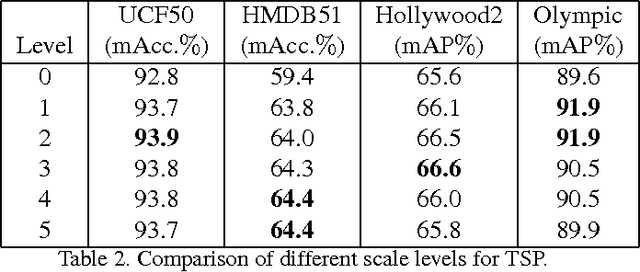
Historically, researchers in the field have spent a great deal of effort to create image representations that have scale invariance and retain spatial location information. This paper proposes to encode equivalent temporal characteristics in video representations for action recognition. To achieve temporal scale invariance, we develop a method called temporal scale pyramid (TSP). To encode temporal information, we present and compare two methods called temporal extension descriptor (TED) and temporal division pyramid (TDP) . Our purpose is to suggest solutions for matching complex actions that have large variation in velocity and appearance, which is missing from most current action representations. The experimental results on four benchmark datasets, UCF50, HMDB51, Hollywood2 and Olympic Sports, support our approach and significantly outperform state-of-the-art methods. Most noticeably, we achieve 65.0% mean accuracy and 68.2% mean average precision on the challenging HMDB51 and Hollywood2 datasets which constitutes an absolute improvement over the state-of-the-art by 7.8% and 3.9%, respectively.