 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACUNA: Safe Agents as Recursive Program Holes
May 27, 2026LLM agents increasingly act by writing code, yet a split persists between the runtime that drives the agent and the code the model writes. The runtime owns the loop, context, and control flow, and the model has little say over any of them. Letting model-written code shape the runtime itself would make agents more expressive, but it would also sharpen safety problems. A model can be diverted by a prompt injection, call the wrong tool, or fail partway and leave an inconsistent state, and each such failure reaches further when the code shapes the runtime than when it expresses a single action. We present LACUNA, a programming model for agents that closes this split while preserving safety. Each agent action is a typed call $\texttt{agent[T](task)}$ that the LLM fills with code when execution reaches it, and the code is type-checked against the surrounding program before it runs. Because each action is accepted or rejected as a whole, a rejected one leaves the environment untouched, and its compiler diagnostics drive a retry. The same check also bounds which tools and data an action may use and how they flow. Our primitive expresses ReAct loops, sub-agents, skills, parallel decomposition, and multi-model planning as ordinary control flow. We evaluate LACUNA on a collection of test cases, BrowseComp-Plus, and $τ^2$-bench. On BrowseComp-Plus, $8.6\%$ of generations are rejected before execution, with 0.7 retries per query on average, and the agent reaches $27.1\%$ accuracy. On $τ^2$-bench, LACUNA solves $76.0\%$ of $392$ tasks across four domains with a capable model, on par with the baseline agent.
Generative Synthetic Data for Causal Inference: Pitfalls, Remedies, and Opportunities
Apr 26, 2026Synthetic data offers a promising tool for privacy-preserving data release, augmentation, and simulation, but its use in causal inference requires preserving more than predictive fidelity. We show that fully generative tabular synthesizers, including GAN- and LLM-based models, can achieve strong train-on-synthetic-test-on-real performance while substantially distorting causal estimands such as the average treatment effect (ATE). We formalize this failure through sensitivity and tradeoff results showing that ATE preservation requires control of both the generated covariate law and the treatment-effect contrast in the outcome regression. Motivated by this observation, we propose a hybrid synthetic-data framework that generates covariates separately from the treatment and outcome mechanisms, using distance-to-closest-record diagnostics to monitor covariate synthesis and separately learned nuisance models to construct (W, A, Y) triplets. We further study targeted synthetic augmentation for practical positivity problems and characterize when added overlap support helps by improving conditional-effect estimation more than it shifts the covariate distribution. Finally, we develop a synthetic simulation engine for pre-analysis estimator evaluation, enabling finite-sample comparison of OR, IPW, AIPW, and TMLE under realistic covariate structure. Across experiments, hybrid synthetic data substantially improve ATE preservation relative to fully generative baselines and provide a practical diagnostic tool for robust causal analysis.
EgoEsportsQA: An Egocentric Video Benchmark for Perception and Reasoning in Esports
Apr 14, 2026While video large language models (Video-LLMs) excel in understanding slow-paced, real-world egocentric videos, their capabilities in high-velocity, information-dense virtual environments remain under-explored. Existing benchmarks focus on daily activities, yet lack a rigorous testbed for evaluating fast, rule-bound reasoning in virtual scenarios. To fill this gap, we introduce EgoEsportsQA, a pioneering video question-answering (QA) benchmark for grounding perception and reasoning in expert esports knowledge. We curate 1,745 high-quality QA pairs from professional matches across 3 first-person shooter games via a scalable six-stage pipeline. These questions are structured into a two-dimensional decoupled taxonomy: 11 sub-tasks in the cognitive capability dimension (covering perception and reasoning levels) and 6 sub-tasks in the esports knowledge dimension. Comprehensive evaluations of state-of-the-art Video-LLMs reveal that current models still fail to achieve satisfactory performance, with the best model only 71.58%. The results expose notable gaps across both axes: models exhibit stronger capabilities in basic visual perception than in deep tactical reasoning, and they grasp overall macro-progression better than fine-grained micro-operations. Extensive ablation experiments demonstrate the intrinsic weaknesses of current Video-LLM architectures. Further analysis suggests that our dataset not only reveals the connections between real-world and virtual egocentric domains, but also offers guidance for optimizing downstream esports applications, thereby fostering the future advancement of Video-LLMs in various egocentric environments.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
Tracking Capabilities for Safer Agents
Mar 01, 2026AI agents that interact with the real world through tool calls pose fundamental safety challenges: agents might leak private information, cause unintended side effects, or be manipulated through prompt injection. To address these challenges, we propose to put the agent in a programming-language-based "safety harness": instead of calling tools directly, agents express their intentions as code in a capability-safe language: Scala 3 with capture checking. Capabilities are program variables that regulate access to effects and resources of interest. Scala's type system tracks capabilities statically, providing fine-grained control over what an agent can do. In particular, it enables local purity, the ability to enforce that sub-computations are side-effect-free, preventing information leakage when agents process classified data. We demonstrate that extensible agent safety harnesses can be built by leveraging a strong type system with tracked capabilities. Our experiments show that agents can generate capability-safe code with no significant loss in task performance, while the type system reliably prevents unsafe behaviors such as information leakage and malicious side effects.
Understanding and Guiding Layer Placement in Parameter-Efficient Fine-Tuning of Large Language Models
Feb 03, 2026As large language models (LLMs) continue to grow, the cost of full-parameter fine-tuning has made parameter-efficient fine-tuning (PEFT) the default strategy for downstream adaptation. Constraints from inference latency in scalable serving and fine-tuning cost in edge or rapid-deployment settings make the choice of which layers to fine-tune unavoidable. Yet current practice typically applies PEFT uniformly across all layers, with limited understanding or leverage of layer selection. This paper develops a unified projected residual view of PEFT on top of a frozen base model. Under a local quadratic approximation, layerwise adaptation is governed by three quantities: (i) the projected residual norm (resnorm), which measures how much correctable bias a layer can capture; (ii) the activation energy, which determines feature conditioning; and (iii) layer coupling, which quantifies how strongly residuals interact across layers. We show that, for squared loss and linear adapters, the resnorm equals a normalized gradient norm, activation energy controls ill-conditioning and noise amplification, and weak coupling yields approximately additive layerwise contributions. Building on these insights, we introduce the Layer Card, a reusable diagnostic that summarizes residual signal strength, compute cost, and performance for each layer of a given model. With an identical model and LoRA configuration, Layer Card-guided placement refines the choice of adapted layers to flexibly prioritize different objectives, such as maximizing performance or reducing fine-tuning cost. Moreover, on Qwen3-8B, we show that selectively adapting a subset of layers can achieve performance close to full-layer LoRA while substantially reducing fine-tuning cost and the number of adapter-augmented layers during inference, offering a more cost-performance-aware alternative to full-layer insertion.
ChartEditor: A Reinforcement Learning Framework for Robust Chart Editing
Nov 19, 2025Chart editing reduces manual effort in visualization design. Typical benchmarks limited in data diversity and assume access to complete chart code, which is seldom in real-world scenarios. To address this gap, we present ChartEditVista, a comprehensive benchmark consisting of 7,964 samples spanning 31 chart categories. It encompasses diverse editing instructions and covers nearly all editable chart elements. The inputs in ChartEditVista include only the original chart image and natural language editing instructions, without the original chart codes. ChartEditVista is generated through a fully automated pipeline that produces, edits, and verifies charts, ensuring high-quality chart editing data. Besides, we introduce two novel fine-grained, rule-based evaluation metrics: the layout metric, which evaluates the position, size and color of graphical components; and the text metric, which jointly assesses textual content and font styling. Building on top of ChartEditVista, we present ChartEditor, a model trained using a reinforcement learning framework that incorporates a novel rendering reward to simultaneously enforce code executability and visual fidelity. Through extensive experiments and human evaluations, we demonstrate that ChartEditVista provides a robust evaluation, while ChartEditor consistently outperforms models with similar-scale and larger-scale on chart editing tasks.
POLYCHARTQA: Benchmarking Large Vision-Language Models with Multilingual Chart Question Answering
Jul 16, 2025Charts are a universally adopted medium for interpreting and communicating data. However, existing chart understanding benchmarks are predominantly English-centric, limiting their accessibility and applicability to global audiences. In this paper, we present PolyChartQA, the first large-scale multilingual chart question answering benchmark covering 22,606 charts and 26,151 question-answering pairs across 10 diverse languages. PolyChartQA is built using a decoupled pipeline that separates chart data from rendering code, allowing multilingual charts to be flexibly generated by simply translating the data and reusing the code. We leverage state-of-the-art LLM-based translation and enforce rigorous quality control in the pipeline to ensure the linguistic and semantic consistency of the generated multilingual charts. PolyChartQA facilitates systematic evaluation of multilingual chart understanding. Experiments on both open- and closed-source large vision-language models reveal a significant performance gap between English and other languages, especially low-resource ones with non-Latin scripts. This benchmark lays a foundation for advancing globally inclusive vision-language models.
Residual Feature Integration is Sufficient to Prevent Negative Transfer
May 17, 2025Transfer learning typically leverages representations learned from a source domain to improve performance on a target task. A common approach is to extract features from a pre-trained model and directly apply them for target prediction. However, this strategy is prone to negative transfer where the source representation fails to align with the target distribution. In this article, we propose Residual Feature Integration (REFINE), a simple yet effective method designed to mitigate negative transfer. Our approach combines a fixed source-side representation with a trainable target-side encoder and fits a shallow neural network on the resulting joint representation, which adapts to the target domain while preserving transferable knowledge from the source domain. Theoretically, we prove that REFINE is sufficient to prevent negative transfer under mild conditions, and derive the generalization bound demonstrating its theoretical benefit. Empirically, we show that REFINE consistently enhances performance across diverse application and data modalities including vision, text, and tabular data, and outperforms numerous alternative solutions. Our method is lightweight, architecture-agnostic, and robust, making it a valuable addition to the existing transfer learning toolbox.
Goal State Generation for Robotic Manipulation Based on Linguistically Guided Hybrid Gaussian Diffusion
Dec 25, 2024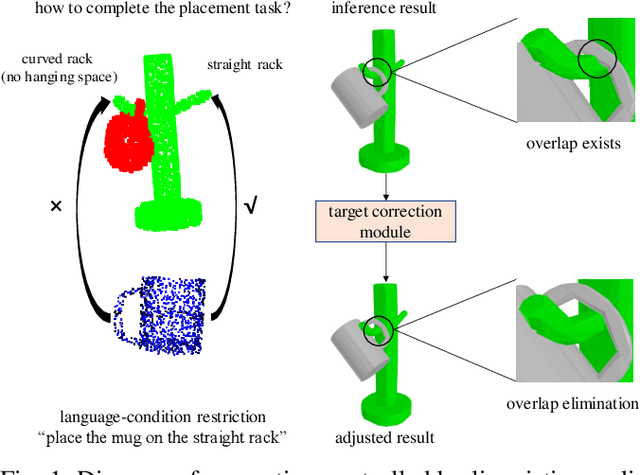
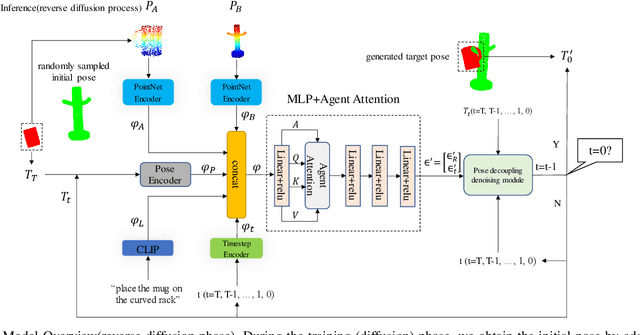
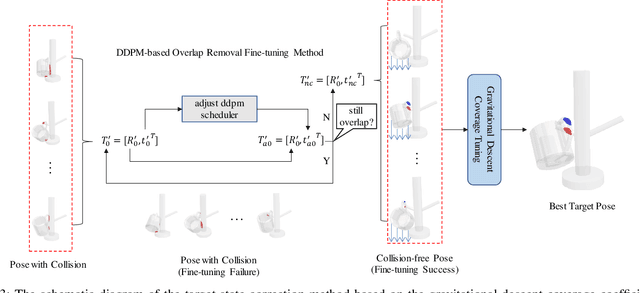

In robotic manipulation tasks, achieving a designated target state for the manipulated object is often essential to facilitate motion planning for robotic arms. Specifically, in tasks such as hanging a mug, the mug must be positioned within a feasible region around the hook. Previous approaches have enabled the generation of multiple feasible target states for mugs; however, these target states are typically generated randomly, lacking control over the specific generation locations. This limitation makes such methods less effective in scenarios where constraints exist, such as hooks already occupied by other mugs or when specific operational objectives must be met. Moreover, due to the frequent physical interactions between the mug and the rack in real-world hanging scenarios, imprecisely generated target states from end-to-end models often result in overlapping point clouds. This overlap adversely impacts subsequent motion planning for the robotic arm. To address these challenges, we propose a Linguistically Guided Hybrid Gaussian Diffusion (LHGD) network for generating manipulation target states, combined with a gravity coverage coefficient-based method for target state refinement. To evaluate our approach under a language-specified distribution setting, we collected multiple feasible target states for 10 types of mugs across 5 different racks with 10 distinct hooks. Additionally, we prepared five unseen mug designs for validation purposes. Experimental results demonstrate that our method achieves the highest success rates across single-mode, multi-mode, and language-specified distribution manipulation tasks. Furthermore, it significantly reduces point cloud overlap, directly producing collision-free target states and eliminating the need for additional obstacle avoidance operations by the robotic arm.