 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCAS: Layered Universal Codec Avatars
Feb 27, 2025



Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
SqueezeMe: Efficient Gaussian Avatars for VR
Dec 19, 2024



Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
Rasterized Edge Gradients: Handling Discontinuities Differentiably
May 03, 2024



Computing the gradients of a rendering process is paramount for diverse applications in computer vision and graphics. However, accurate computation of these gradients is challenging due to discontinuities and rendering approximations, particularly for surface-based representations and rasterization-based rendering. We present a novel method for computing gradients at visibility discontinuities for rasterization-based differentiable renderers. Our method elegantly simplifies the traditionally complex problem through a carefully designed approximation strategy, allowing for a straightforward, effective, and performant solution. We introduce a novel concept of micro-edges, which allows us to treat the rasterized images as outcomes of a differentiable, continuous process aligned with the inherently non-differentiable, discrete-pixel rasterization. This technique eliminates the necessity for rendering approximations or other modifications to the forward pass, preserving the integrity of the rendered image, which makes it applicable to rasterized masks, depth, and normals images where filtering is prohibitive. Utilizing micro-edges simplifies gradient interpretation at discontinuities and enables handling of geometry intersections, offering an advantage over the prior art. We showcase our method in dynamic human head scene reconstruction, demonstrating effective handling of camera images and segmentation masks.
URHand: Universal Relightable Hands
Jan 10, 2024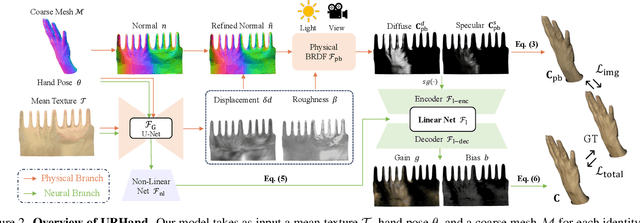
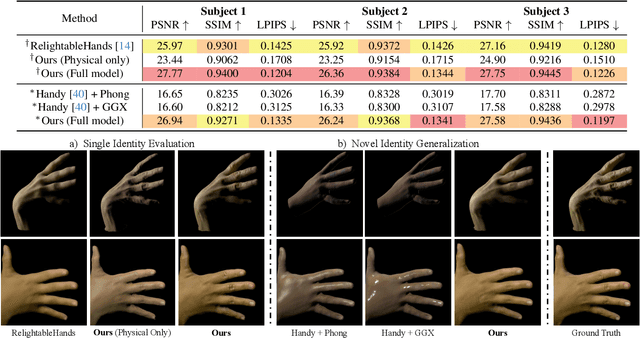
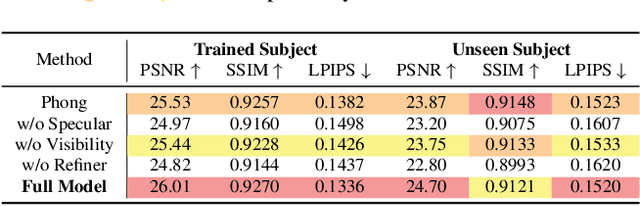
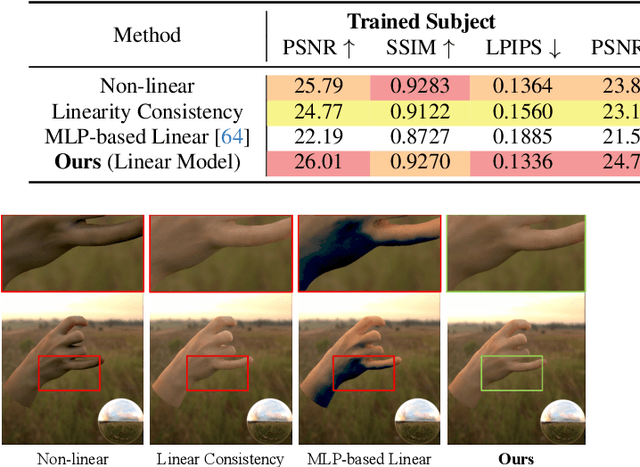
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022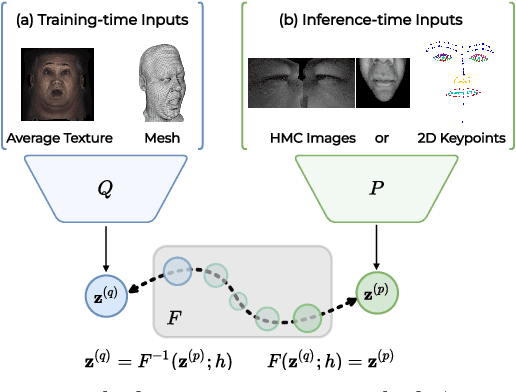
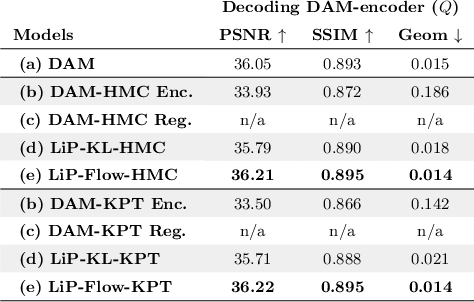

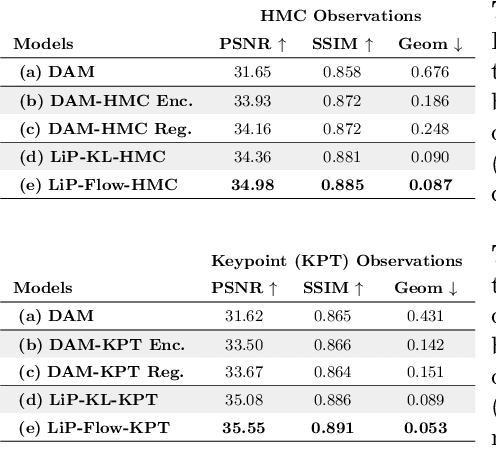
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.
Adversarial Latent Autoencoders
Apr 09, 2020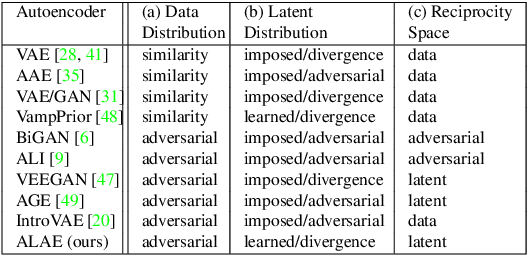
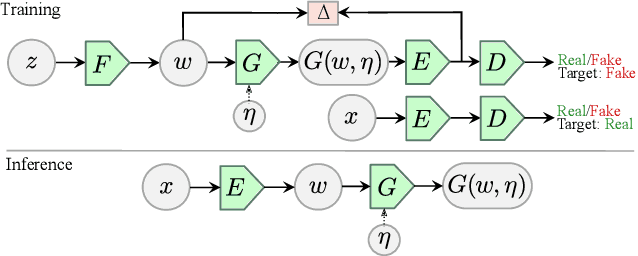
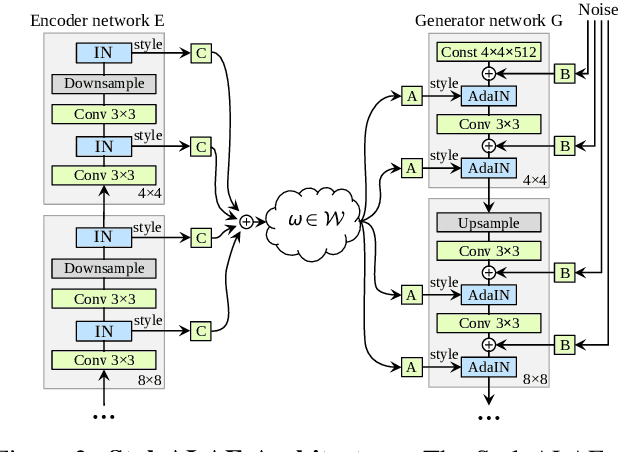
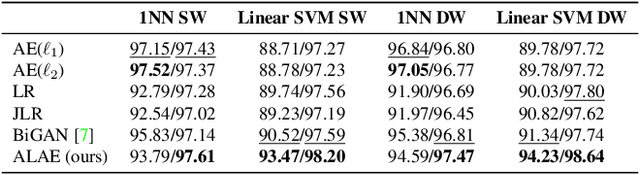
Autoencoder networks are unsupervised approaches aiming at combining generative and representational properties by learning simultaneously an encoder-generator map. Although studied extensively, the issues of whether they have the same generative power of GANs, or learn disentangled representations, have not been fully addressed. We introduce an autoencoder that tackles these issues jointly, which we call Adversarial Latent Autoencoder (ALAE). It is a general architecture that can leverage recent improvements on GAN training procedures. We designed two autoencoders: one based on a MLP encoder, and another based on a StyleGAN generator, which we call StyleALAE. We verify the disentanglement properties of both architectures. We show that StyleALAE can not only generate 1024x1024 face images with comparable quality of StyleGAN, but at the same resolution can also produce face reconstructions and manipulations based on real images. This makes ALAE the first autoencoder able to compare with, and go beyond the capabilities of a generator-only type of architecture.
syGlass: Interactive Exploration of Multidimensional Images Using Virtual Reality Head-mounted Displays
Aug 22, 2018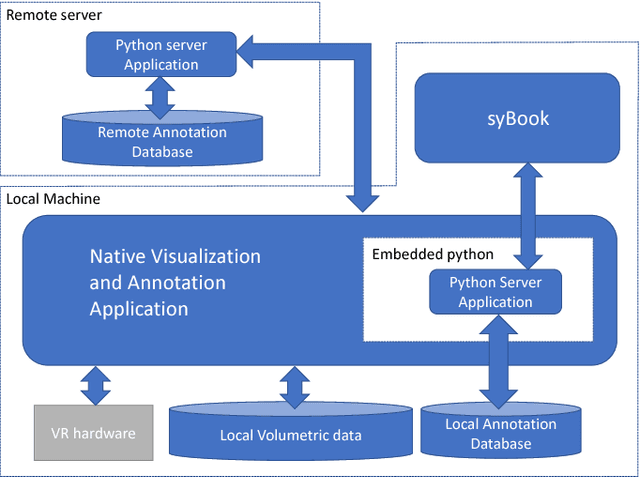
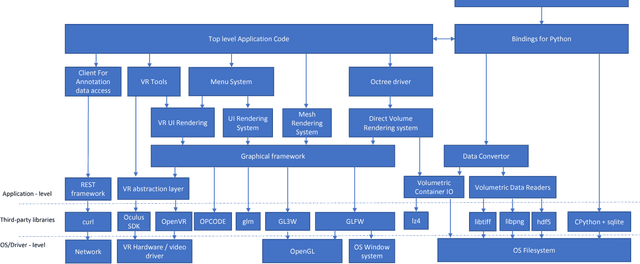
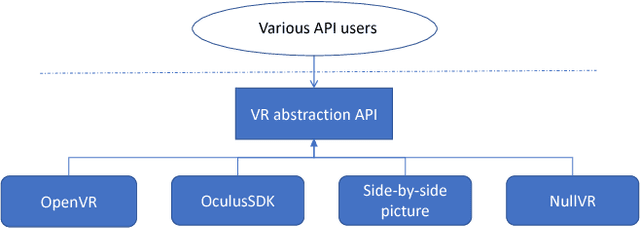
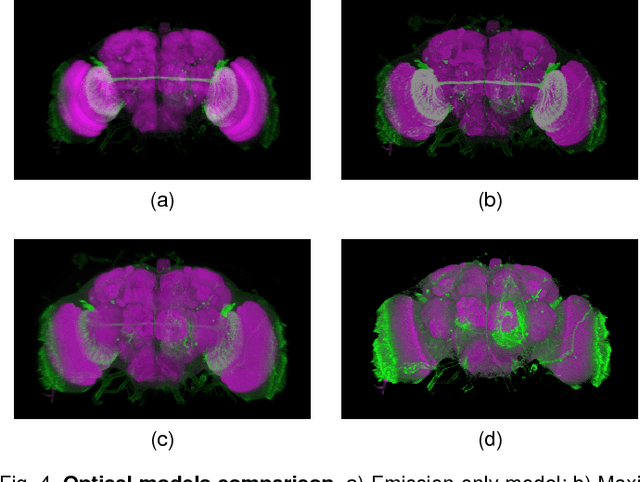
The quest for deeper understanding of biological systems has driven the acquisition of increasingly larger multidimensional image datasets. Inspecting and manipulating data of this complexity is very challenging in traditional visualization systems. We developed syGlass, a software package capable of visualizing large scale volumetric data with inexpensive virtual reality head-mounted display technology. This allows leveraging stereoscopic vision to significantly improve perception of complex 3D structures, and provides immersive interaction with data directly in 3D. We accomplished this by developing highly optimized data flow and volume rendering pipelines, tested on datasets up to 16TB in size, as well as tools available in a virtual reality GUI to support advanced data exploration, annotation, and cataloguing.
Generative Probabilistic Novelty Detection with Adversarial Autoencoders
Jul 06, 2018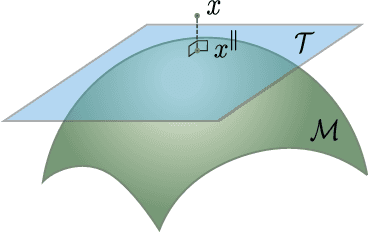
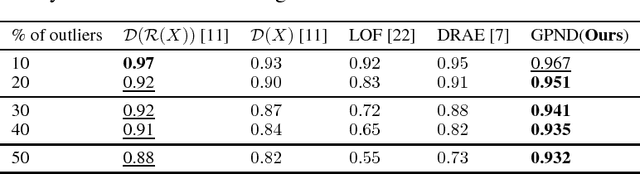
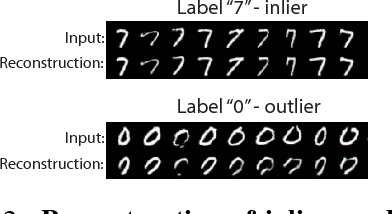
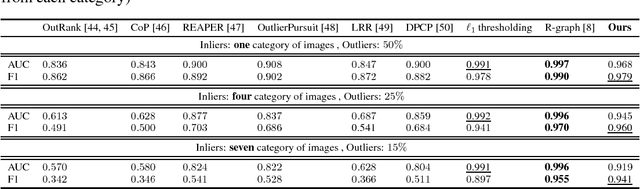
Novelty detection is the problem of identifying whether a new data point is considered to be an inlier or an outlier. We assume that training data is available to describe only the inlier distribution. Recent approaches primarily leverage deep encoder-decoder network architectures to compute a reconstruction error that is used to either compute a novelty score or to train a one-class classifier. While we too leverage a novel network of that kind, we take a probabilistic approach and effectively compute how likely is that a sample was generated by the inlier distribution. We achieve this with two main contributions. First, we make the computation of the novelty probability feasible because we linearize the parameterized manifold capturing the underlying structure of the inlier distribution, and show how the probability factorizes and can be computed with respect to local coordinates of the manifold tangent space. Second, we improved the training of the autoencoder network. An extensive set of results show that the approach achieves state-of-the-art results on several benchmark datasets.