 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automatic Quasi-clique Merger algorithm (AQCM)
Mar 06, 2021

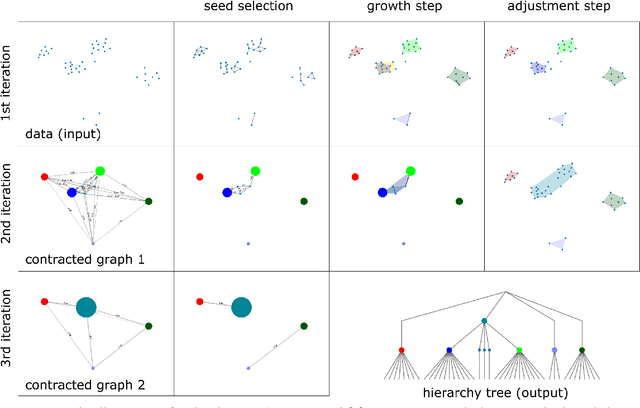
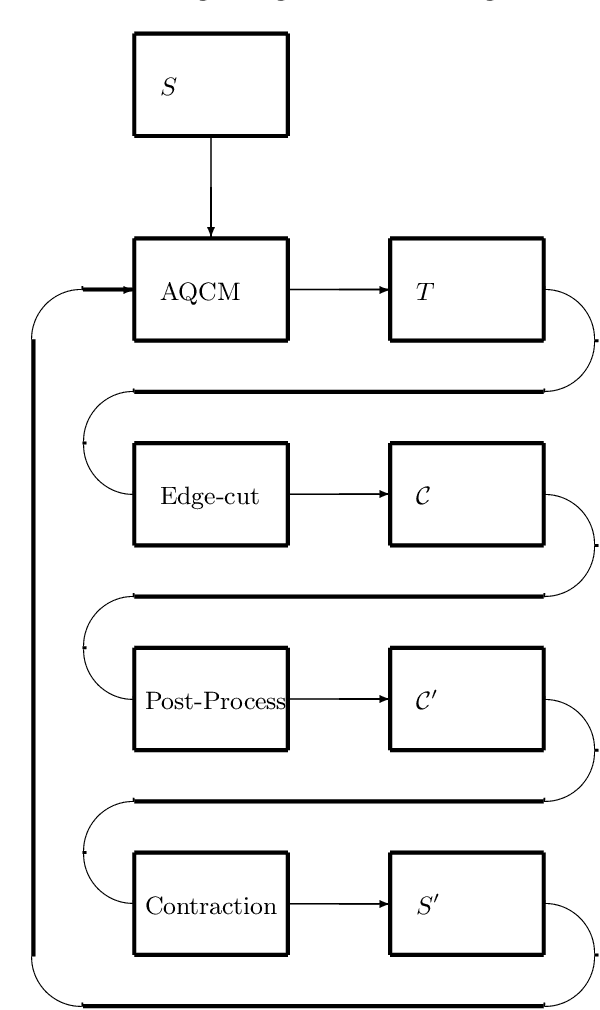
The Automatic Quasi-clique Merger algorithm is a new algorithm adapted from early work published under the name QCM (quasi-clique merger) [Ou2006, Ou2007, Zhao2011, Qi2014]. The AQCM algorithm performs hierarchical clustering in any data set for which there is an associated similarity measure quantifying the similarity of any data i and data j. Importantly, the method exhibits two valuable performance properties: 1) the ability to automatically return either a larger or smaller number of clusters depending on the inherent properties of the data rather than on a parameter 2) the ability to return a very large number of relatively small clusters automatically when such clusters are reasonably well defined in a data set. In this work we present the general idea of a quasi-clique agglomerative approach, provide the full details of the mathematical steps of the AQCM algorithm, and explain some of the motivation behind the new methodology. The main achievement of the new methodology is that the agglomerative process now unfolds adaptively according to the inherent structure unique to a given data set, and this happens without the time-costly parameter adjustment that drove the previous QCM algorithm. For this reason we call the new algorithm \emph{automatic}. We provide a demonstration of the algorithm's performance at the task of community detection in a social media network of 22,900 nodes.
syGlass: Interactive Exploration of Multidimensional Images Using Virtual Reality Head-mounted Displays
Aug 22, 2018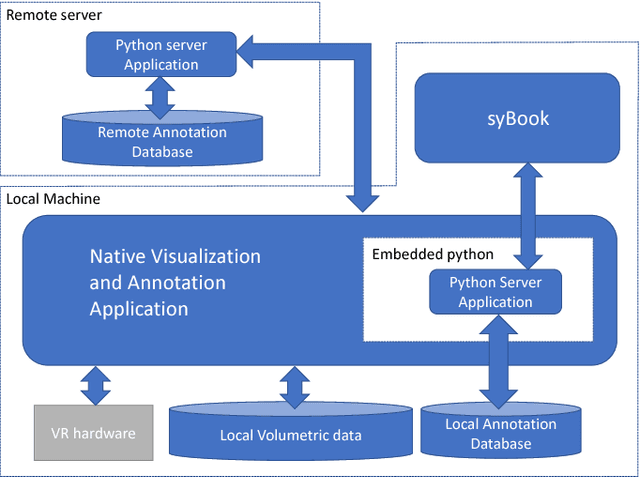
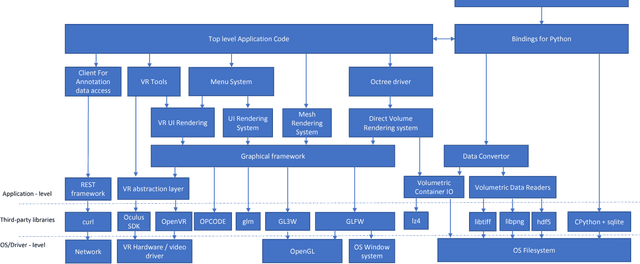
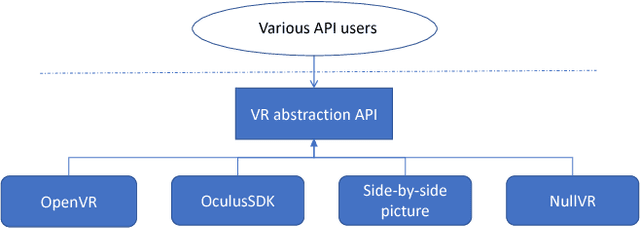
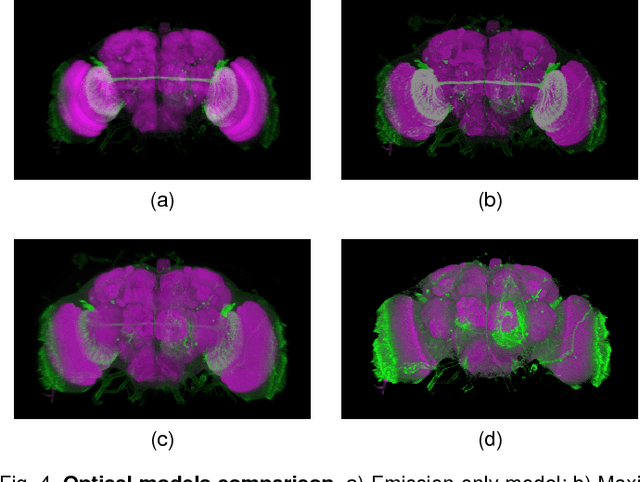
The quest for deeper understanding of biological systems has driven the acquisition of increasingly larger multidimensional image datasets. Inspecting and manipulating data of this complexity is very challenging in traditional visualization systems. We developed syGlass, a software package capable of visualizing large scale volumetric data with inexpensive virtual reality head-mounted display technology. This allows leveraging stereoscopic vision to significantly improve perception of complex 3D structures, and provides immersive interaction with data directly in 3D. We accomplished this by developing highly optimized data flow and volume rendering pipelines, tested on datasets up to 16TB in size, as well as tools available in a virtual reality GUI to support advanced data exploration, annotation, and cataloguing.