 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAV: Personalized Head Avatar from Unstructured Video Collection
Jul 22, 2024



We propose PAV, Personalized Head Avatar for the synthesis of human faces under arbitrary viewpoints and facial expressions. PAV introduces a method that learns a dynamic deformable neural radiance field (NeRF), in particular from a collection of monocular talking face videos of the same character under various appearance and shape changes. Unlike existing head NeRF methods that are limited to modeling such input videos on a per-appearance basis, our method allows for learning multi-appearance NeRFs, introducing appearance embedding for each input video via learnable latent neural features attached to the underlying geometry. Furthermore, the proposed appearance-conditioned density formulation facilitates the shape variation of the character, such as facial hair and soft tissues, in the radiance field prediction. To the best of our knowledge, our approach is the first dynamic deformable NeRF framework to model appearance and shape variations in a single unified network for multi-appearances of the same subject. We demonstrate experimentally that PAV outperforms the baseline method in terms of visual rendering quality in our quantitative and qualitative studies on various subjects.
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022



We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022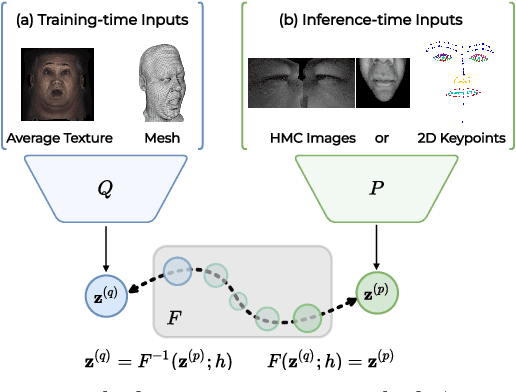
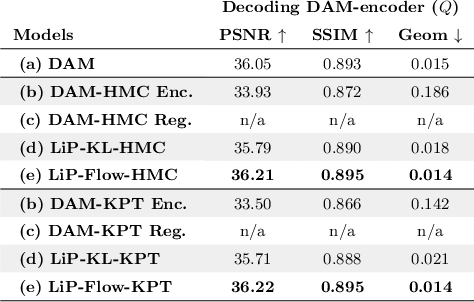

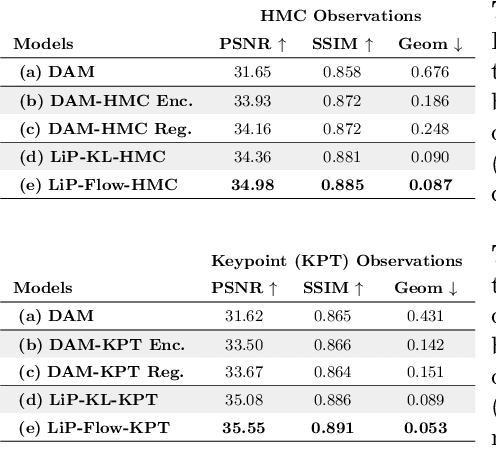
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.
Multi-person Implicit Reconstruction from a Single Image
Apr 19, 2021



We present a new end-to-end learning framework to obtain detailed and spatially coherent reconstructions of multiple people from a single image. Existing multi-person methods suffer from two main drawbacks: they are often model-based and therefore cannot capture accurate 3D models of people with loose clothing and hair; or they require manual intervention to resolve occlusions or interactions. Our method addresses both limitations by introducing the first end-to-end learning approach to perform model-free implicit reconstruction for realistic 3D capture of multiple clothed people in arbitrary poses (with occlusions) from a single image. Our network simultaneously estimates the 3D geometry of each person and their 6DOF spatial locations, to obtain a coherent multi-human reconstruction. In addition, we introduce a new synthetic dataset that depicts images with a varying number of inter-occluded humans and a variety of clothing and hair styles. We demonstrate robust, high-resolution reconstructions on images of multiple humans with complex occlusions, loose clothing and a large variety of poses and scenes. Our quantitative evaluation on both synthetic and real-world datasets demonstrates state-of-the-art performance with significant improvements in the accuracy and completeness of the reconstructions over competing approaches.
Temporal Consistency Loss for High Resolution Textured and Clothed 3DHuman Reconstruction from Monocular Video
Apr 19, 2021



We present a novel method to learn temporally consistent 3D reconstruction of clothed people from a monocular video. Recent methods for 3D human reconstruction from monocular video using volumetric, implicit or parametric human shape models, produce per frame reconstructions giving temporally inconsistent output and limited performance when applied to video. In this paper, we introduce an approach to learn temporally consistent features for textured reconstruction of clothed 3D human sequences from monocular video by proposing two advances: a novel temporal consistency loss function; and hybrid representation learning for implicit 3D reconstruction from 2D images and coarse 3D geometry. The proposed advances improve the temporal consistency and accuracy of both the 3D reconstruction and texture prediction from a monocular video. Comprehensive comparative performance evaluation on images of people demonstrates that the proposed method significantly outperforms the state-of-the-art learning-based single image 3D human shape estimation approaches achieving significant improvement of reconstruction accuracy, completeness, quality and temporal consistency.
Multi-View Consistency Loss for Improved Single-Image 3D Reconstruction of Clothed People
Sep 29, 2020

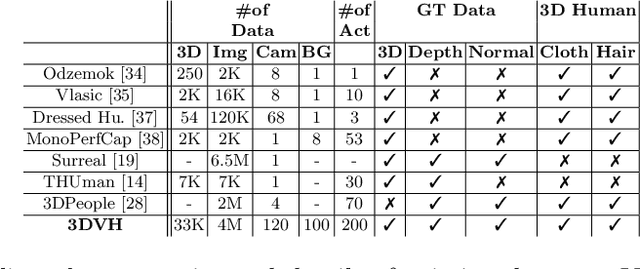

We present a novel method to improve the accuracy of the 3D reconstruction of clothed human shape from a single image. Recent work has introduced volumetric, implicit and model-based shape learning frameworks for reconstruction of objects and people from one or more images. However, the accuracy and completeness for reconstruction of clothed people is limited due to the large variation in shape resulting from clothing, hair, body size, pose and camera viewpoint. This paper introduces two advances to overcome this limitation: firstly a new synthetic dataset of realistic clothed people, 3DVH; and secondly, a novel multiple-view loss function for training of monocular volumetric shape estimation, which is demonstrated to significantly improve generalisation and reconstruction accuracy. The 3DVH dataset of realistic clothed 3D human models rendered with diverse natural backgrounds is demonstrated to allows transfer to reconstruction from real images of people. Comprehensive comparative performance evaluation on both synthetic and real images of people demonstrates that the proposed method significantly outperforms the previous state-of-the-art learning-based single image 3D human shape estimation approaches achieving significant improvement of reconstruction accuracy, completeness, and quality. An ablation study shows that this is due to both the proposed multiple-view training and the new 3DVH dataset. The code and the dataset can be found at the project website: https://akincaliskan3d.github.io/MV3DH/.
Learning Dense Wide Baseline Stereo Matching for People
Oct 02, 2019


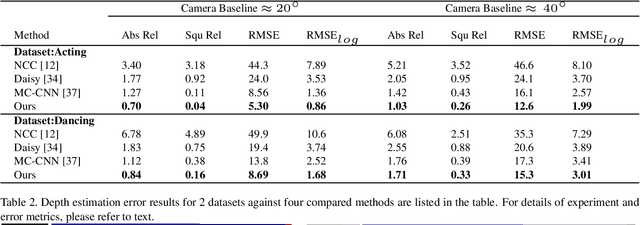
Existing methods for stereo work on narrow baseline image pairs giving limited performance between wide baseline views. This paper proposes a framework to learn and estimate dense stereo for people from wide baseline image pairs. A synthetic people stereo patch dataset (S2P2) is introduced to learn wide baseline dense stereo matching for people. The proposed framework not only learns human specific features from synthetic data but also exploits pooling layer and data augmentation to adapt to real data. The network learns from the human specific stereo patches from the proposed dataset for wide-baseline stereo estimation. In addition to patch match learning, a stereo constraint is introduced in the framework to solve wide baseline stereo reconstruction of humans. Quantitative and qualitative performance evaluation against state-of-the-art methods of proposed method demonstrates improved wide baseline stereo reconstruction on challenging datasets. We show that it is possible to learn stereo matching from synthetic people dataset and improve performance on real datasets for stereo reconstruction of people from narrow and wide baseline stereo data.