 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Paper and Code
Mar 15, 2022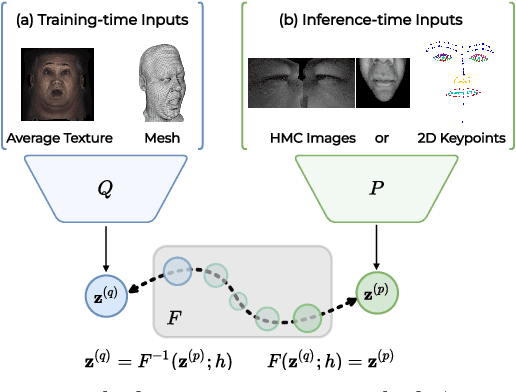
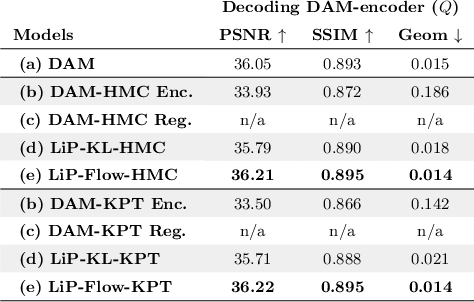

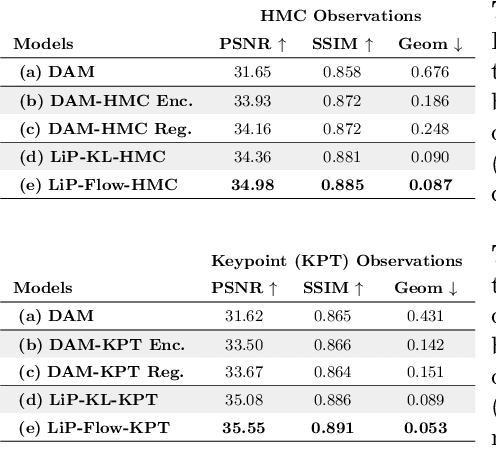
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.