 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAV: Personalized Head Avatar from Unstructured Video Collection
Jul 22, 2024



We propose PAV, Personalized Head Avatar for the synthesis of human faces under arbitrary viewpoints and facial expressions. PAV introduces a method that learns a dynamic deformable neural radiance field (NeRF), in particular from a collection of monocular talking face videos of the same character under various appearance and shape changes. Unlike existing head NeRF methods that are limited to modeling such input videos on a per-appearance basis, our method allows for learning multi-appearance NeRFs, introducing appearance embedding for each input video via learnable latent neural features attached to the underlying geometry. Furthermore, the proposed appearance-conditioned density formulation facilitates the shape variation of the character, such as facial hair and soft tissues, in the radiance field prediction. To the best of our knowledge, our approach is the first dynamic deformable NeRF framework to model appearance and shape variations in a single unified network for multi-appearances of the same subject. We demonstrate experimentally that PAV outperforms the baseline method in terms of visual rendering quality in our quantitative and qualitative studies on various subjects.
Gauge Equivariant Convolutional Networks and the Icosahedral CNN
Feb 11, 2019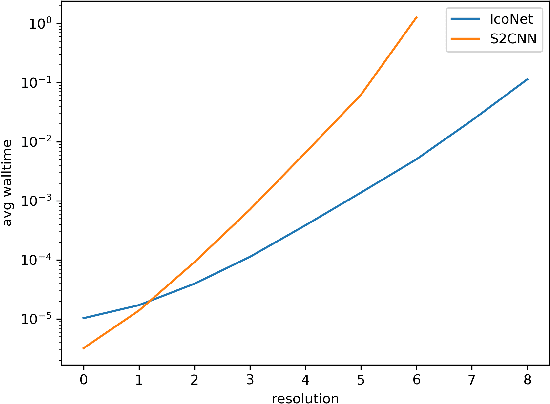
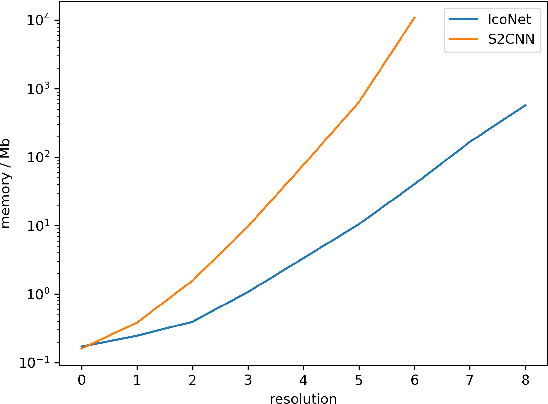
The idea of equivariance to symmetry transformations provides one of the first theoretically grounded principles for neural network architecture design. Equivariant networks have shown excellent performance and data efficiency on vision and medical imaging problems that exhibit symmetries. Here we show how this principle can be extended beyond global symmetries to local gauge transformations, thereby enabling the development of equivariant convolutional networks on general manifolds. We implement gauge equivariant CNNs for signals defined on the icosahedron, which provides a reasonable approximation of spherical signals. By choosing to work with this very regular manifold, we are able to implement the gauge equivariant convolution using a single conv2d call, making it a highly scalable and practical alternative to Spherical CNNs. We evaluate the Icosahedral CNN on omnidirectional image segmentation and climate pattern segmentation, and find that it outperforms previous methods.
A Layer-Based Sequential Framework for Scene Generation with GANs
Feb 02, 2019


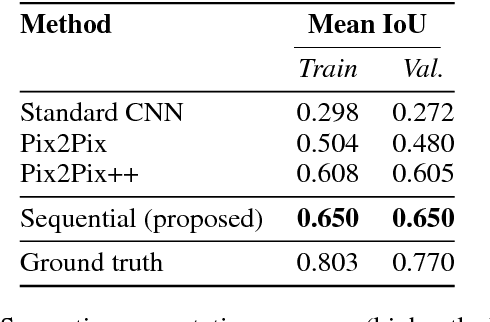
The visual world we sense, interpret and interact everyday is a complex composition of interleaved physical entities. Therefore, it is a very challenging task to generate vivid scenes of similar complexity using computers. In this work, we present a scene generation framework based on Generative Adversarial Networks (GANs) to sequentially compose a scene, breaking down the underlying problem into smaller ones. Different than the existing approaches, our framework offers an explicit control over the elements of a scene through separate background and foreground generators. Starting with an initially generated background, foreground objects then populate the scene one-by-one in a sequential manner. Via quantitative and qualitative experiments on a subset of the MS-COCO dataset, we show that our proposed framework produces not only more diverse images but also copes better with affine transformations and occlusion artifacts of foreground objects than its counterparts.
Estimating Small Differences in Car-Pose from Orbits
Sep 03, 2018

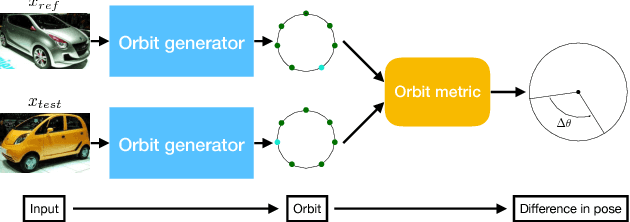

Distinction among nearby poses and among symmetries of an object is challenging. In this paper, we propose a unified, group-theoretic approach to tackle both. Different from existing works which directly predict absolute pose, our method measures the pose of an object relative to another pose, i.e., the pose difference. The proposed method generates the complete orbit of an object from a single view of the object with respect to the subgroup of SO(3) of rotations around the z-axis, and compares the orbit of the object with another orbit using a novel orbit metric to estimate the pose difference. The generated orbit in the latent space records all the differences in pose in the original observational space, and as a result, the method is capable of finding subtle differences in pose. We demonstrate the effectiveness of the proposed method on cars, where identifying the subtle pose differences is vital.
On the Dynamics of a Recurrent Hopfield Network
Feb 09, 2015



In this research paper novel real/complex valued recurrent Hopfield Neural Network (RHNN) is proposed. The method of synthesizing the energy landscape of such a network and the experimental investigation of dynamics of Recurrent Hopfield Network is discussed. Parallel modes of operation (other than fully parallel mode) in layered RHNN is proposed. Also, certain potential applications are proposed.