 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFDemorpher: Generalizable Face Demorphing for Operational Morphing Attack Detection
Mar 30, 2026Face morphing attacks compromise biometric security by creating document images that verify against multiple identities, posing significant risks from document issuance to border control. Differential Morphing Attack Detection (D-MAD) offers an effective countermeasure, particularly when employing face demorphing to disentangle identities blended in the morph. However, existing methods lack operational generalizability due to limited training data and the assumption that all document inputs are morphs. This paper presents SFDemorpher, a framework designed for the operational deployment of face demorphing for D-MAD that performs identity disentanglement within joint StyleGAN latent and high-dimensional feature spaces. We introduce a dual-pass training strategy handling both morphed and bona fide documents, leveraging a hybrid corpus with predominantly synthetic identities to enhance robustness against unseen distributions. Extensive evaluation confirms state-of-the-art generalizability across unseen identities, diverse capture conditions, and 13 morphing techniques, spanning both border verification and the challenging document enrollment stage. Our framework achieves superior D-MAD performance by widening the margin between the score distributions of bona fide and morphed samples while providing high-fidelity visual reconstructions facilitating explainability.
FLUXSynID: A Framework for Identity-Controlled Synthetic Face Generation with Document and Live Images
May 13, 2025Synthetic face datasets are increasingly used to overcome the limitations of real-world biometric data, including privacy concerns, demographic imbalance, and high collection costs. However, many existing methods lack fine-grained control over identity attributes and fail to produce paired, identity-consistent images under structured capture conditions. We introduce FLUXSynID, a framework for generating high-resolution synthetic face datasets with user-defined identity attribute distributions and paired document-style and trusted live capture images. The dataset generated using the FLUXSynID framework shows improved alignment with real-world identity distributions and greater inter-set diversity compared to prior work. The FLUXSynID framework for generating custom datasets, along with a dataset of 14,889 synthetic identities, is publicly released to support biometric research, including face recognition and morphing attack detection.
Language-Based Augmentation to Address Shortcut Learning in Object Goal Navigation
Feb 07, 2024Deep Reinforcement Learning (DRL) has shown great potential in enabling robots to find certain objects (e.g., `find a fridge') in environments like homes or schools. This task is known as Object-Goal Navigation (ObjectNav). DRL methods are predominantly trained and evaluated using environment simulators. Although DRL has shown impressive results, the simulators may be biased or limited. This creates a risk of shortcut learning, i.e., learning a policy tailored to specific visual details of training environments. We aim to deepen our understanding of shortcut learning in ObjectNav, its implications and propose a solution. We design an experiment for inserting a shortcut bias in the appearance of training environments. As a proof-of-concept, we associate room types to specific wall colors (e.g., bedrooms with green walls), and observe poor generalization of a state-of-the-art (SOTA) ObjectNav method to environments where this is not the case (e.g., bedrooms with blue walls). We find that shortcut learning is the root cause: the agent learns to navigate to target objects, by simply searching for the associated wall color of the target object's room. To solve this, we propose Language-Based (L-B) augmentation. Our key insight is that we can leverage the multimodal feature space of a Vision-Language Model (VLM) to augment visual representations directly at the feature-level, requiring no changes to the simulator, and only an addition of one layer to the model. Where the SOTA ObjectNav method's success rate drops 69%, our proposal has only a drop of 23%.
3D printed realistic finger vein phantoms
Sep 26, 2023



Finger vein pattern recognition is an emerging biometric with a good resistance to presentation attacks and low error rates. One problem is that it is hard to obtain ground truth finger vein patterns from live fingers. In this paper we propose an advanced method to create finger vein phantoms using 3D printing where we mimic the optical properties of the various tissues inside the fingers, like bone, veins and soft tissues using different printing materials and parameters. We demonstrate that we are able to create finger phantoms that result in realistic finger vein images and precisely known vein patterns. These phantoms can be used to develop and evaluate finger vein extraction and recognition methods. In addition, we show that the finger vein phantoms can be used to spoof a finger vein recognition system. This paper is based on the Master's thesis of Rasmus van der Grift.
Vulnerability of 3D Face Recognition Systems to Morphing Attacks
Sep 21, 2023



In recent years face recognition systems have been brought to the mainstream due to development in hardware and software. Consistent efforts are being made to make them better and more secure. This has also brought developments in 3D face recognition systems at a rapid pace. These 3DFR systems are expected to overcome certain vulnerabilities of 2DFR systems. One such problem that the domain of 2DFR systems face is face image morphing. A substantial amount of research is being done for generation of high quality face morphs along with detection of attacks from these morphs. Comparatively the understanding of vulnerability of 3DFR systems against 3D face morphs is less. But at the same time an expectation is set from 3DFR systems to be more robust against such attacks. This paper attempts to research and gain more information on this matter. The paper describes a couple of methods that can be used to generate 3D face morphs. The face morphs that are generated using this method are then compared to the contributing faces to obtain similarity scores. The highest MMPMR is obtained around 40% with RMMR of 41.76% when 3DFRS are attacked with look-a-like morphs.
A Face Recognition System's Worst Morph Nightmare, Theoretically
Nov 30, 2021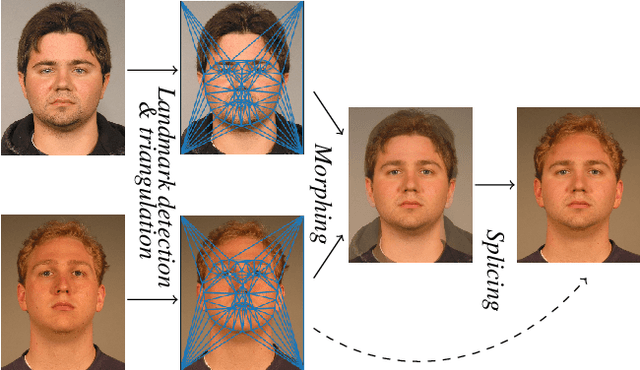
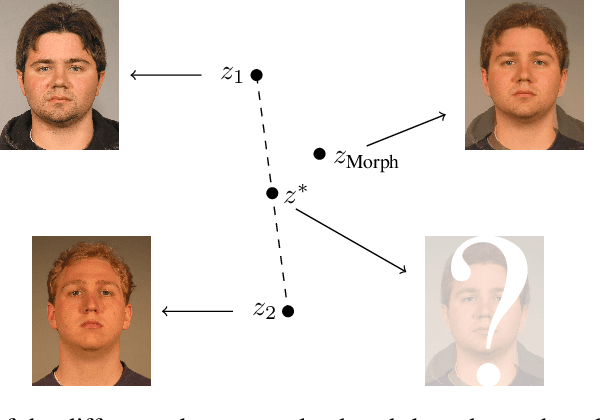
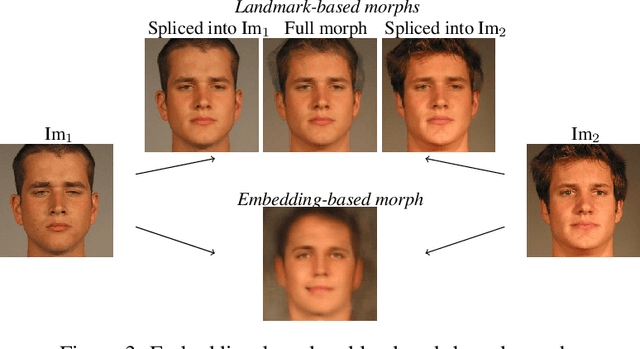
It has been shown that Face Recognition Systems (FRSs) are vulnerable to morphing attacks, but most research focusses on landmark-based morphs. A second method for generating morphs uses Generative Adversarial Networks, which results in convincingly real facial images that can be almost as challenging for FRSs as landmark-based attacks. We propose a method to create a third, different type of morph, that has the advantage of being easier to train. We introduce the theoretical concept of \textit{worst-case morphs}, which are those morphs that are most challenging for a fixed FRS. For a set of images and corresponding embeddings in an FRS's latent space, we generate images that approximate these worst-case morphs using a mapping from embedding space back to image space. While the resulting images are not yet as challenging as other morphs, they can provide valuable information in future research on Morphing Attack Detection (MAD) methods and on weaknesses of FRSs. Methods for MAD need to be validated on more varied morph databases. Our proposed method contributes to achieving such variation.
A survey of face recognition techniques under occlusion
Jun 19, 2020
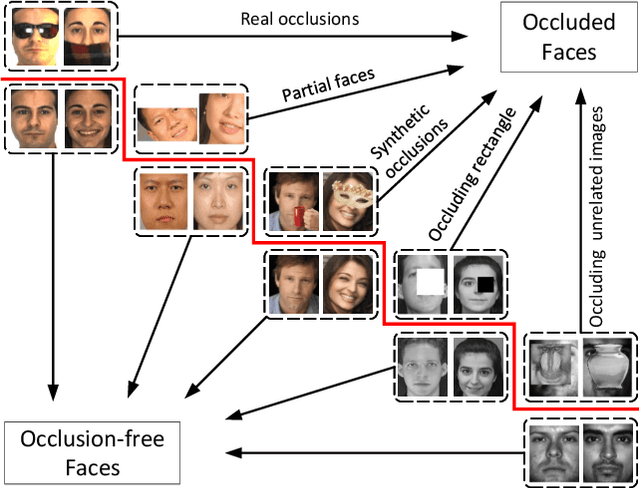
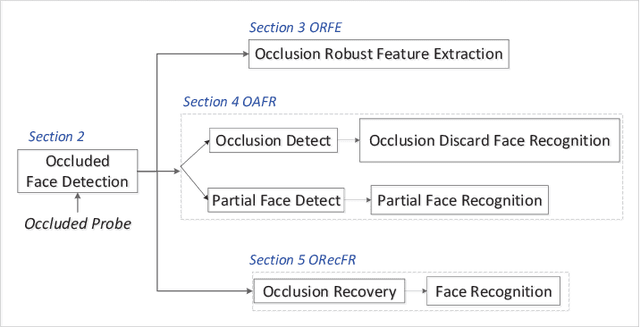
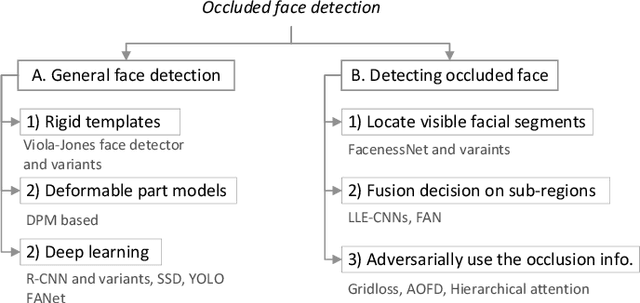
The limited capacity to recognize faces under occlusions is a long-standing problem that presents a unique challenge for face recognition systems and even for humans. The problem regarding occlusion is less covered by research when compared to other challenges such as pose variation, different expressions, etc. Nevertheless, occluded face recognition is imperative to exploit the full potential of face recognition for real-world applications. In this paper, we restrict the scope to occluded face recognition. First, we explore what the occlusion problem is and what inherent difficulties can arise. As a part of this review, we introduce face detection under occlusion, a preliminary step in face recognition. Second, we present how existing face recognition methods cope with the occlusion problem and classify them into three categories, which are 1) occlusion robust feature extraction approaches, 2) occlusion aware face recognition approaches, and 3) occlusion recovery based face recognition approaches. Furthermore, we analyze the motivations, innovations, pros and cons, and the performance of representative approaches for comparison. Finally, future challenges and method trends of occluded face recognition are thoroughly discussed.
Morphing Attack Detection -- Database, Evaluation Platform and Benchmarking
Jun 16, 2020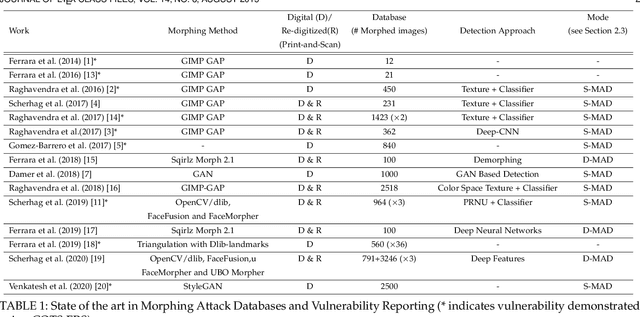
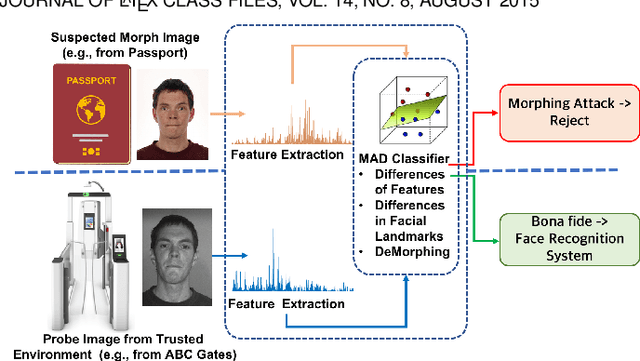
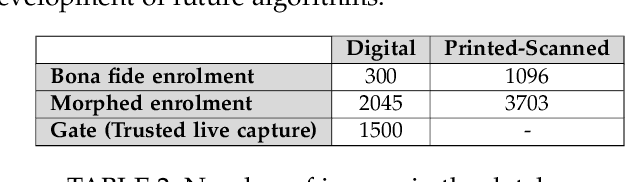

Morphing attacks have posed a severe threat to Face Recognition System (FRS). Despite the number of advancements reported in recent works, we note serious open issues that are not addressed. Morphing Attack Detection (MAD) algorithms often are prone to generalization challenges as they are database dependent. The existing databases, mostly of semi-public nature, lack in diversity in terms of ethnicity, various morphing process and post-processing pipelines. Further, they do not reflect a realistic operational scenario for Automated Border Control (ABC) and do not provide a basis to test MAD on unseen data, in order to benchmark the robustness of algorithms. In this work, we present a new sequestered dataset for facilitating the advancements of MAD where the algorithms can be tested on unseen data in an effort to better generalize. The newly constructed dataset consists of facial images from 150 subjects from various ethnicities, age-groups and both genders. In order to challenge the existing MAD algorithms, the morphed images are with careful subject pre-selection created from the subjects, and further post-processed to remove the morphing artifacts. The images are also printed and scanned to remove all digital cues and to simulate a realistic challenge for MAD algorithms. Further, we present a new online evaluation platform to test algorithms on sequestered data. With the platform we can benchmark the morph detection performance and study the generalization ability. This work also presents a detailed analysis on various subsets of sequestered data and outlines open challenges for future directions in MAD research.
A Layer-Based Sequential Framework for Scene Generation with GANs
Feb 02, 2019


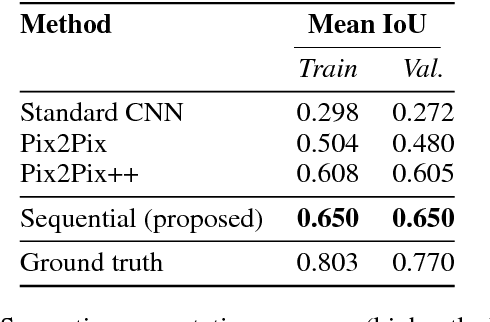
The visual world we sense, interpret and interact everyday is a complex composition of interleaved physical entities. Therefore, it is a very challenging task to generate vivid scenes of similar complexity using computers. In this work, we present a scene generation framework based on Generative Adversarial Networks (GANs) to sequentially compose a scene, breaking down the underlying problem into smaller ones. Different than the existing approaches, our framework offers an explicit control over the elements of a scene through separate background and foreground generators. Starting with an initially generated background, foreground objects then populate the scene one-by-one in a sequential manner. Via quantitative and qualitative experiments on a subset of the MS-COCO dataset, we show that our proposed framework produces not only more diverse images but also copes better with affine transformations and occlusion artifacts of foreground objects than its counterparts.
Predicting Face Recognition Performance Using Image Quality
Oct 24, 2015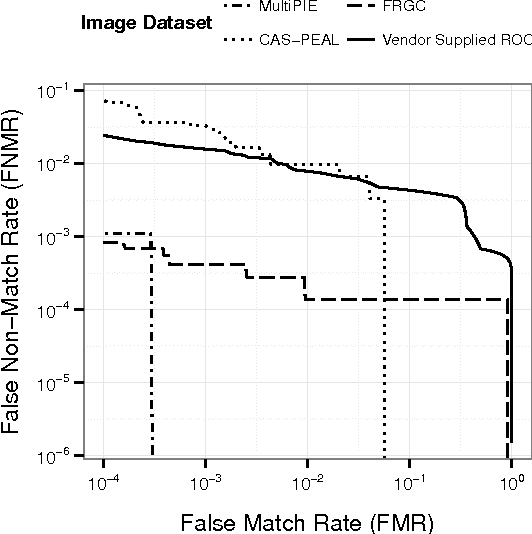
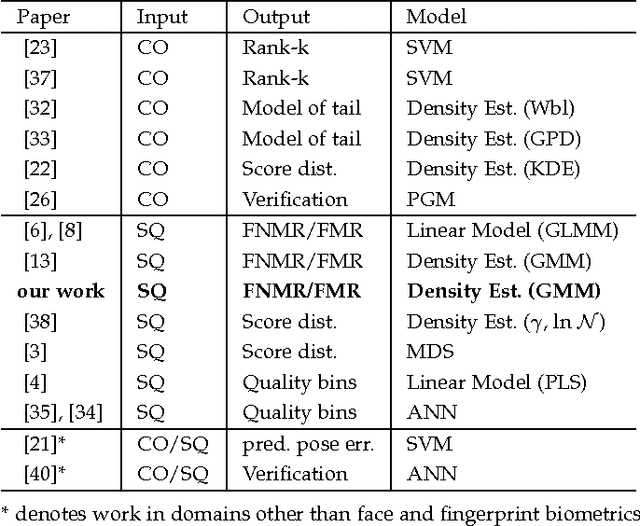


This paper proposes a data driven model to predict the performance of a face recognition system based on image quality features. We model the relationship between image quality features (e.g. pose, illumination, etc.) and recognition performance measures using a probability density function. To address the issue of limited nature of practical training data inherent in most data driven models, we have developed a Bayesian approach to model the distribution of recognition performance measures in small regions of the quality space. Since the model is based solely on image quality features, it can predict performance even before the actual recognition has taken place. We evaluate the performance predictive capabilities of the proposed model for six face recognition systems (two commercial and four open source) operating on three independent data sets: MultiPIE, FRGC and CAS-PEAL. Our results show that the proposed model can accurately predict performance using an accurate and unbiased Image Quality Assessor (IQA). Furthermore, our experiments highlight the impact of the unaccounted quality space -- the image quality features not considered by IQA -- in contributing to performance prediction errors.